Onderzoekers van de Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) in Abu Dhabi hebben onthulde LlamaV-o1, een nieuw multimodaal AI-model dat prioriteit geeft aan transparantie en logische samenhang in redeneren.
In tegenstelling tot andere redenerende AI-modellen, die vaak black-box-uitvoer leveren, demonstreert LlamaV-o1 het probleemoplossende proces stap voor stap, waardoor gebruikers elke fase van de logica kunnen volgen.
In combinatie met de introductie van VRC-Bench, een nieuwe maatstaf voor het evalueren van tussenliggende redeneerstappen, biedt LlamaV-o1 een fris perspectief op de interpreteerbaarheid en bruikbaarheid van AI op diverse gebieden, zoals medische diagnostiek, financiën en wetenschappen research.
De release van dit model en deze benchmark weerspiegelt de groeiende vraag naar AI systemen die niet alleen nauwkeurige resultaten opleveren, maar ook uitleggen hoe deze resultaten worden bereikt.
Gerelateerd: OpenAI Onthult nieuw o3-model met drastisch verbeterde redeneervaardigheden
VRC-Bench: een benchmark ontworpen voor transparant redeneren
De VRC-Bench-benchmark is een kernelement van De ontwikkeling en evaluatie van LlamaV-o1. Traditionele AI-benchmarks richten zich primair op de nauwkeurigheid van het uiteindelijke antwoord, waarbij vaak de logische processen worden genegeerd die tot die antwoorden leiden.
VRC-Bench pakt deze beperking aan door de kwaliteit van redeneerstappen te evalueren via statistieken als Faithfulness-Step en Semantic Coverage, die meten hoe goed de redenering van een model aansluit bij het bronmateriaal en de logische consistentie.
Gerelateerd: Google’s nieuwe Gemini 2.0 Flash Thinking Model daagt OpenAI’s o1 Pro uit met uitstekende prestaties
Bestrijkt meer dan 1.000 taken in acht categorieën omvat VRC-Bench domeinen zoals visueel redeneren, medische beeldvorming en culturele contextanalyse. Deze taken omvatten meer dan 4.000 handmatig geverifieerde redeneerstappen, waardoor de benchmark een van de meest uitgebreide is voor het evalueren van stapsgewijze redeneringen.
De onderzoekers beschrijven het belang ervan als volgt: “De meeste benchmarks richten zich primair op de nauwkeurigheid van de eindtaak, waarbij de kwaliteit van tussenliggende redeneerstappen wordt verwaarloosd. VRC-Bench presenteert een gevarieerde reeks uitdagingen… die een robuuste evaluatie van logische samenhang en correctheid in de redenering mogelijk maken.”
Door een nieuwe standaard te zetten voor multimodale AI-evaluatie, zorgt VRC-Bench ervoor dat modellen zoals LlamaV-o1 verantwoordelijk gehouden voor hun besluitvormingsprocessen en bieden een niveau van transparantie dat van cruciaal belang is voor toepassingen met hoge inzet.
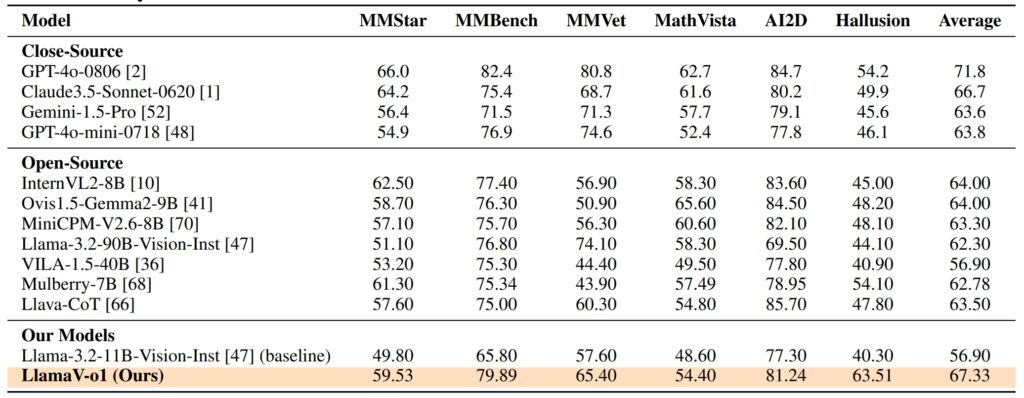
Prestatiestatistieken: hoe LlamaV-o1 ervoor staat De prestaties van LlamaV-o1 op VRC-Bench en andere benchmarks demonstreren zijn technische bekwaamheid. Het behaalde een redeneerscore van 68,93, waarmee het andere open-sourcemodellen zoals LLava-CoT (66,21) en LLava-CoT (66,21) en andere overtreft. het verkleinen van de kloof met eigen modellen zoals GPT-4o, die een score van 71,8 scoorde. LlamaV-o1 leverde vijf keer hogere inferentiesnelheden vergeleken met zijn concurrenten, wat de efficiëntie aantoont.
Op zes multimodale benchmarks, waaronder MathVista, AI2D en Hallion, behaalde LlamaV-o1 een gemiddelde score van 67,33% onderstreept zijn vermogen om diverse redeneertaken uit te voeren met behoud van logische samenhang en transparantie.
Training LlamaV-o1: de synergie van leren in het curriculum en Beam Search
Het succes van LlamaV-o1 is geworteld in zijn innovatieve trainingsmethoden. De onderzoekers maakten gebruik van curriculum learning, een techniek geïnspireerd door menselijke opvoeding.
Deze aanpak begint met eenvoudigere taken en evolueert geleidelijk naar complexere taken, waardoor het model fundamentele redeneervaardigheden kan opbouwen voordat geavanceerde uitdagingen worden aangepakt.
Door het trainingsproces te structureren verbetert het leerplan het vermogen van het model om te generaliseren over diverse taken, van document-OCR tot wetenschappelijk redeneren.
Gerelateerd: QwQ van Alibaba-32B-Preview sluit zich aan bij de AI-modelredeneringsstrijd met OpenAI
Beam Search, een optimalisatie-algoritme, verbetert deze trainingsaanpak door meerdere redeneerpaden parallel te genereren en de meest logische te selecteren. Deze methode verbetert niet alleen de nauwkeurigheid van het model, maar verlaagt ook de rekenkosten, waardoor het efficiënter wordt voor toepassingen in de echte wereld.
Zoals de onderzoekers uitleggen:”Door gebruik te maken van curriculumleren en Beam Search, verwerft ons model stapsgewijs vaardigheden… waardoor zowel geoptimaliseerde gevolgtrekkingen als robuuste redeneermogelijkheden worden gegarandeerd.”
Toepassingen in de geneeskunde , Financiën en meer
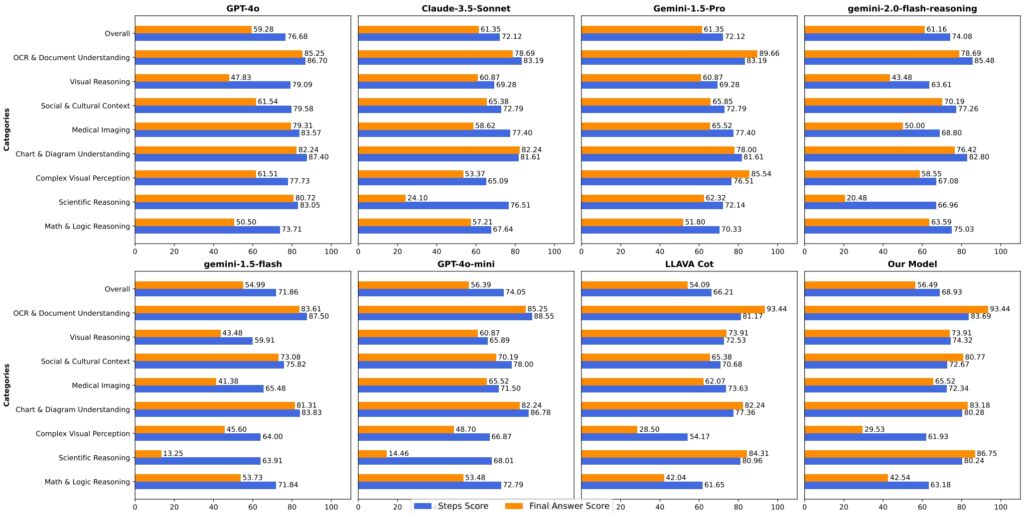
Het transparante redeneervermogen van LlamaV-o1 maakt het bijzonder geschikt voor toepassingen waarbij vertrouwen en interpreteerbaarheid essentieel zijn. Bij medische beeldvorming kan het model bijvoorbeeld niet alleen een diagnose bieden maar een gedetailleerde uitleg over hoe het tot deze conclusie is gekomen.
Deze functie stelt radiologen en andere medische professionals in staat AI-gestuurde inzichten te valideren, waardoor het vertrouwen en de nauwkeurigheid bij kritische besluitvorming worden vergroot.
In de financiële sector blinkt LlamaV-o1 uit in het interpreteren van complexe grafieken en diagrammen, en biedt stapsgewijze uitsplitsingen die bruikbare inzichten opleveren.
LlamaV-o1 vertegenwoordigt een aanzienlijke vooruitgang in multimodale AI, vooral wat betreft het vermogen om transparante redenering. Door curriculumleren en Beam Search te combineren met de robuuste evaluatiestatistieken van VRC-Bench, zet het een nieuwe maatstaf voor interpreteerbaarheid en efficiëntie.
Naarmate AI-systemen steeds meer worden geïntegreerd in cruciale industrieën, zal de behoefte aan modellen die hun redeneerprocessen kunnen verklaren alleen maar toenemen.