Google DeepMind heeft FACTS Grounding gelanceerd, een nieuwe benchmark die is ontworpen om grote taalmodellen (LLM’s) te testen op hun vermogen om feitelijk nauwkeurige, op documenten gebaseerde antwoorden te genereren.
De benchmark, gehost op Kaggle, heeft tot doel een van de meest urgente uitdagingen in de wereld aan te pakken kunstmatige intelligentie: ervoor zorgen dat AI-outputs gebaseerd zijn op de gegevens die eraan worden verstrekt, in plaats van te vertrouwen op externe kennis of hallucinaties te introduceren – plausibele maar onjuiste informatie.
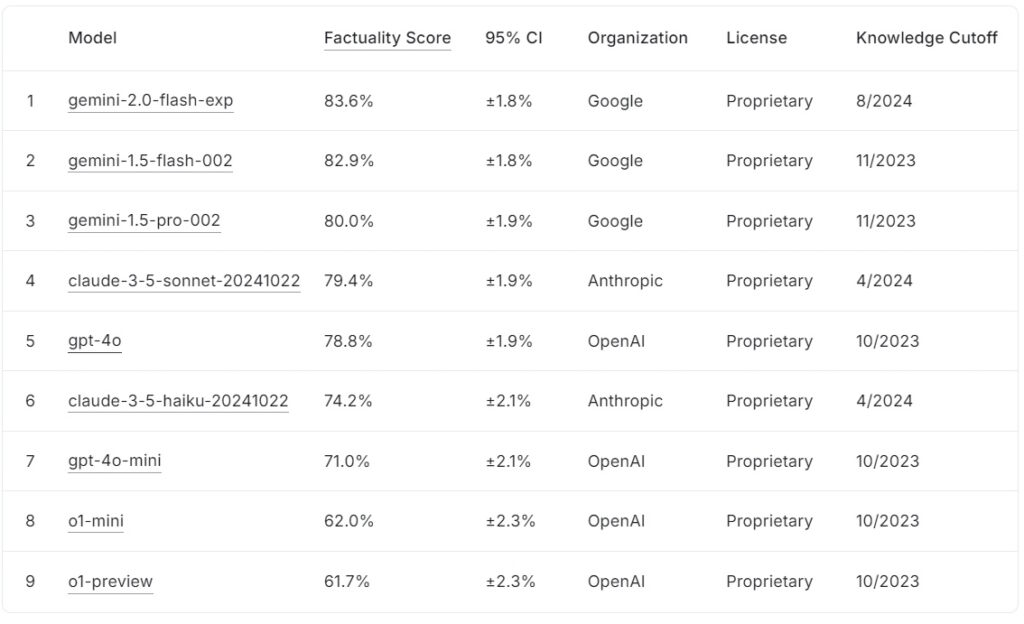
Het huidige FACTS Grounding leaderboard rangschikt grote taalmodellen op basis van hun feitelijkheidsscores, met die van Google gemini-2.0-flash-exp leidt met 83,6%, op de voet gevolgd door gemini-1.5-flash-002 met 82,9%, en gemini-1,5-pro-002 op 80,0%.
Antropische claude-3.5-sonnet-20241022 staat op de vierde plaats met 79,4%, terwijl OpenAI’s gpt-4o behaalt 78,8% en staat daarmee op de vijfde plaats. Lager op de lijst scoort claude-3.5-haiku-20241022 van Anthropic 74,2%, gevolgd door gpt-4o-mini met 71,0%.
De kleinere modellen van OpenAI, o1-mini en o1-preview, ronden het klassement af met 62,0% en 61,7%.
 Bron: Kaggle
Bron: Kaggle
FACTS Grounding onderscheidt zich door lange antwoorden te vereisen die gedetailleerde invoerdocumenten synthetiseren, waardoor het een van de meest rigoureuze is benchmarks voor AI-feitelijkheid tot nu toe.
FEITEN Aarding vertegenwoordigt een cruciale ontwikkeling voor de AI-industrie, vooral in toepassingen waar vertrouwen en nauwkeurigheid essentieel zijn. Door LLM’s te evalueren in domeinen zoals geneeskunde, recht, financiën, detailhandel en technologie, zet de benchmark de weg vrij voor verbeterde AI-betrouwbaarheid in praktijkscenario’s.
Volgens het onderzoeksteam van DeepMind meet de”benchmark het vermogen van LLM’s om antwoorden te genereren die uitsluitend gebaseerd zijn op de geboden context… zelfs wanneer de context in strijd is met de kennis van vóór de training.”
Dataset voor complexiteit in de echte wereld
FACTS Grounding bestaat uit 1.719 voorbeelden, samengesteld door menselijke annotators om relevantie en diversiteit te garanderen. Deze voorbeelden zijn afkomstig uit gedetailleerde documenten die maximaal 32.000 tokens omvatten, wat overeenkomt met ongeveer 20.000 woorden.
Elke taak daagt LLM’s uit om samenvattingen uit te voeren, vragen en antwoorden te genereren of inhoud te herschrijven, met strikte instructies om alleen naar de verstrekte gegevens te verwijzen creativiteit, wiskundig redeneren of deskundige interpretatie, waarbij de nadruk in plaats daarvan ligt op het testen van het vermogen van een model om complexe informatie te synthetiseren en te articuleren.
Om de transparantie te behouden en overfitting te voorkomen, heeft DeepMind de dataset in twee segmenten: 860 openbare voorbeelden beschikbaar voor extern gebruik en 859 privévoorbeelden gereserveerd voor scorebordevaluaties.
Deze dubbele structuur waarborgt de integriteit van de benchmark en stimuleert tegelijkertijd de samenwerking van AI-ontwikkelaars over de hele wereld. “We evalueren onze automatische beoordelaars rigoureus op basis van testgegevens om hun prestaties op onze taak te valideren”, merkt het onderzoeksteam op, waarbij ze het zorgvuldige ontwerp benadrukken dat ten grondslag ligt aan FACTS Grounding.
Nauwkeurigheid beoordelen met peer AI-modellen
In tegenstelling tot conventionele benchmarks maakt FACTS Grounding gebruik van een peer review-proces waarbij drie geavanceerde LLM’s betrokken zijn: Gemini 1.5 Pro, GPT-4o en Claude 3.5 Sonnet. Deze modellen dienen als juryleden en beoordelen antwoorden op basis van twee kritische criteria: geschiktheid en feitelijke juistheid.
Reacties moeten eerst een geschiktheidscontrole doorstaan om te bevestigen dat ze de vraag van de gebruiker zinvol beantwoorden beoordeeld op hun basis in het bronmateriaal, waarbij de scores over de drie modellen zijn samengevoegd om vooringenomenheid te minimaliseren.
De onderzoekers van DeepMind benadrukken het belang van deze meergelaagde evaluatie en stellen: “Metrieken die zijn gericht op het evalueren van de feitelijkheid van de gegenereerde tekst… kunnen worden omzeild door de intentie achter het gebruikersverzoek te negeren. Door kortere antwoorden te geven die het overbrengen van uitgebreide informatie ontwijken… is het mogelijk om een hoge feitelijkheidsscore te behalen zonder een nuttig antwoord te geven.”
Het gebruik van meerdere scoresjablonen, inclusief span-level en JSON-gebaseerde benaderingen , zorgt verder voor afstemming op het menselijk oordeel en aanpassingsvermogen aan diverse taken.
De uitdaging van AI-hallucinaties aanpakken
AI-hallucinaties behoren tot de belangrijkste obstakels voor wijdverbreide adoptie van LLM’s in kritieke gebieden. Deze fouten, waarbij modellen uitkomsten genereren die plausibel lijken maar feitelijk onjuist zijn, vormen ernstige risico’s op domeinen als de gezondheidszorg, juridische analyse en financiële rapportage.
FACTS Grounding pakt dit probleem rechtstreeks aan door strenge regels op te leggen Het naleven van de verstrekte invoergegevens evalueert niet alleen het vermogen van een model om onwaarheden te voorkomen, maar zorgt er ook voor dat de uitvoer in lijn blijft met de intentie van de gebruiker.
In tegenstelling tot benchmarks zoals die van OpenAI. SimpleQA, dat de feitelijkheid meet bij het ophalen van trainingsgegevens, FACTS Grounding test hoe goed modellen nieuwe informatie synthetiseren.
Het onderzoekspaper onderstreept dit onderscheid: “Het garanderen van feitelijke nauwkeurigheid tijdens het genereren van LLM-reacties is een uitdaging. De belangrijkste uitdagingen in LLM-feitelijkheid zijn modellering (dat wil zeggen architectuur, training en gevolgtrekking) en meting (dat wil zeggen evaluatiemethodologie, gegevens en statistieken).
Technische uitdagingen en benchmarkontwerp
De complexiteit van lange invoer introduceert unieke technische uitdagingen, vooral bij het ontwerpen van geautomatiseerde evaluatiemethoden die dergelijke reacties nauwkeurig kunnen beoordelen.
FACTS Grounding vertrouwt op rekenintensieve processen om antwoorden te valideren, waarbij strenge criteria worden gebruikt om betrouwbaarheid te garanderen. De opname van modellen met meerdere beoordelaars vermindert potentiële vooroordelen en versterkt het algehele evaluatiekader.
Het onderzoeksteam benadrukt het belang van het diskwalificeren van vage of irrelevante antwoorden. en merkt op: “Het diskwalificeren van niet-geschikte antwoorden leidt tot een vermindering… omdat deze antwoorden als onnauwkeurig worden behandeld.”
Deze strikte handhaving van relevantie zorgt ervoor dat modellen niet worden beloond voor het omzeilen van de geest van de taak.
Samenwerking aanmoedigen door transparantie
De beslissing van DeepMind om FACTS Grounding op Kaggle te hosten weerspiegelt haar toewijding aan het bevorderen van samenwerking in de AI-industrie. Door het publieke deel van de dataset toegankelijk te maken, nodigt het project AI-onderzoekers en-ontwikkelaars uit om hun modellen te evalueren aan de hand van een robuuste standaard en bij te dragen aan het bevorderen van feitelijkheidsbenchmarks.
Deze aanpak sluit aan bij de bredere doelstellingen van transparantie en gedeelde vooruitgang op het gebied van AI, en zorgt ervoor dat verbeteringen in nauwkeurigheid en onderbouwing niet beperkt blijven tot één enkele organisatie.
Onderscheiden van andere Benchmarks
FACTS Grounding onderscheidt zich van andere benchmarks door de focus op het baseren op nieuw geïntroduceerde inputs in plaats van op voorgetrainde kennis.
Terwijl benchmarks zoals OpenAI’s SimpleQA beoordelen hoe goed een model informatie uit het trainingscorpus ophaalt en gebruikt, evalueert FACTS Grounding modellen op hun vermogen om reacties te synthetiseren en te articuleren, uitsluitend gebaseerd op de aangeleverde gegevens.
Dit onderscheid is cruciaal bij het aanpakken van de uitdagingen die voortkomen uit modelvooroordelen of inherente vooroordelen. Door de taak van het verwerken van externe input te isoleren, zorgt FACTS Grounding ervoor dat prestatiestatistieken het vermogen van een model weerspiegelen om in dynamische, realistische scenario’s te werken, in plaats van eenvoudigweg vooraf geleerde informatie opnieuw op te wekken.
Zoals DeepMind in zijn onderzoekspaper uitlegt, is de benchmark ontworpen om LLM’s te evalueren op hun vermogen om complexe, lange zoekopdrachten met feitelijke onderbouwing te beheren, waarbij taken worden gesimuleerd die relevant zijn voor toepassingen in de echte wereld.
Alternatieve methoden voor het aarden van LLM’s
Verschillende methoden bieden vergelijkbare aardingskenmerken als FACTS Grounding, elk met zijn sterke en zwakke punten. Deze methoden zijn bedoeld om de resultaten van LLM te verbeteren door hun toegang tot nauwkeurige informatie te verbeteren of hun trainings-en afstemmingsprocessen te verfijnen.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) verbetert de nauwkeurigheid van LLM-uitvoer door dynamisch relevante informatie op te halen uit externe kennisbanken of databases en deze opnemen in de reacties van het model. In plaats van de hele LLM opnieuw te trainen, werkt RAG door gebruikersprompts te onderscheppen en deze te verrijken met actuele informatie.
Geavanceerde RAG-implementaties maken vaak gebruik van op entiteiten gebaseerd ophalen, waarbij gegevens die aan specifieke entiteiten zijn gekoppeld, worden verenigd om bieden zeer relevante context voor LLM-reacties.
RAG maakt doorgaans gebruik van semantische zoektechnieken voor het ophalen van informatie. Documenten of hun fragmenten worden geïndexeerd op basis van hun semantische inbedding, waardoor het systeem de zoekopdracht van de gebruiker kan matchen met de meest contextueel relevante vermeldingen. Deze aanpak zorgt ervoor dat LLM’s antwoorden genereren op basis van de nieuwste en meest relevante gegevens.
De effectiviteit van RAG hangt sterk af van de kwaliteit en organisatie van de kennisbank, evenals van de nauwkeurigheid van de ophaalalgoritmen. Terwijl FACTS Grounding het vermogen van een LLM evalueert om verankerd te blijven in een verstrekt contextdocument, vult RAG dit aan door LLM’s in staat te stellen hun kennis dynamisch uit te breiden, waarbij ze putten uit externe bronnen om de feitelijkheid en relevantie te vergroten.
Kennisdistillatie
Kennisdistillatie omvat het overdragen van de mogelijkheden van van een groot, complex model (de leraar genoemd) naar een kleiner, taakspecifiek model (de leerling). Deze methode verbetert de efficiëntie terwijl een groot deel van de nauwkeurigheid van het originele model behouden blijft. Er worden twee primaire benaderingen gebruikt bij het distilleren van kennis:
Response-based Knowledge Distillation: richt zich op het repliceren van de resultaten van het lerarenmodel, waarbij ervoor wordt gezorgd dat het leerlingmodel vergelijkbare resultaten oplevert voor bepaalde input.
Op kenmerken gebaseerde kennisdistillatie: extraheert interne representaties en kenmerken uit het lerarenmodel, waardoor het leerlingmodel diepere inzichten kan repliceren.
Door kleinere modellen te verfijnen , kennis distillatie maakt de inzet van LLM’s mogelijk in omgevingen met beperkte middelen zonder significant prestatieverlies. In tegenstelling tot FACTS Grounding, dat de trouw aan de basis evalueert, houdt kennisdestillatie zich meer bezig met het schalen van LLM-mogelijkheden en het optimaliseren ervan voor specifieke taken.
Fine-tuning met geaarde datasets
Fine-tuning omvat het aanpassen van vooraf getrainde LLM’s aan specifieke domeinen of taken door ze te trainen op samengestelde datasets waarbij feitelijke onderbouwing van cruciaal belang is. Datasets bestaande uit wetenschappelijke literatuur of historische gegevens kunnen bijvoorbeeld worden gebruikt om het vermogen van het model om nauwkeurige en domeinspecifieke resultaten te produceren te verbeteren. Deze techniek verbetert de LLM-prestaties voor gespecialiseerde toepassingen, zoals de analyse van medische of juridische documenten.
Het verfijnen is echter arbeidsintensief en riskeert catastrofaal vergeten, waarbij het model de kennis verliest die is opgedaan tijdens de initiële training. FACTS Grounding richt zich op het testen van de feitelijkheid in geïsoleerde contexten, terwijl verfijning de basisprestaties van LLM’s op specifieke gebieden probeert te verbeteren.
Versterkend leren met menselijke feedback (RLHF)
Reinforcement Learning met menselijke feedback (RLHF) omvat menselijke voorkeuren voor het opleidingsproces van LLM’s. Door het model iteratief te trainen om zijn reacties af te stemmen op menselijke feedback, verfijnt RLHF de kwaliteit, feitelijkheid en bruikbaarheid van de resultaten. Menselijke beoordelaars beoordelen de resultaten van de LLM en deze scores worden gebruikt als signalen om het model te optimaliseren.
RLHF is bijzonder succesvol geweest in het vergroten van de gebruikerstevredenheid en het garanderen dat de gegenereerde reacties aansluiten bij de menselijke verwachtingen. Terwijl FACTS Grounding de feitelijke basis evalueert aan de hand van specifieke documenten, legt RLHF de nadruk op het afstemmen van LLM-resultaten op menselijke waarden en voorkeuren.
Instructie volgen en in-context leren
Instructie volgen en in-context leren houdt in dat je de basis legt voor LLM’s via zorgvuldig vervaardigde voorbeelden binnen de gebruikersprompt. Deze methoden zijn afhankelijk van het vermogen van het model om te generaliseren vanuit een paar demonstraties. Hoewel deze aanpak snelle verbeteringen kan opleveren, bereikt deze mogelijk niet hetzelfde niveau van aardingskwaliteit als verfijnde afstemming of op retrieval gebaseerde methoden.
Externe tools en API’s
LLM’s kunnen worden geïntegreerd met externe tools en API’s om realtime toegang tot externe gegevens te bieden, waardoor hun aardingsmogelijkheden aanzienlijk worden verbeterd. Voorbeelden hiervan zijn:
Browsermogelijkheden: Hiermee kunnen LLM’s toegang krijgen tot realtime informatie van internet en deze ophalen om specifieke vragen te beantwoorden of hun kennis bij te werken.
strong>API Calls: Hiermee kunnen LLM’s communiceren met gestructureerde databases of services, waardoor reacties worden verrijkt met nauwkeurige en actuele informatie.
Deze tools vergroten de bruikbaarheid van LLM’s door ze te verbinden met echte-wereldkennisbronnen, het verbeteren van hun vermogen om nauwkeurige en geaarde output te genereren. Terwijl FACTS Grounding de betrouwbaarheid van interne aarding evalueert, bieden externe tools een alternatief middel om de feitelijkheid uit te breiden en te verifiëren.
Open-Source Model Grounding Opties
Er zijn verschillende open source-implementaties beschikbaar voor de hierboven besproken alternatieve aardingsmethoden:
Implicaties voor toepassingen met hoge inzet
Het belang van nauwkeurige en gefundeerde AI-reacties wordt vooral duidelijk bij toepassingen met hoge inzet, zoals medische diagnostiek , juridische beoordelingen en financiële analyses. In deze contexten kunnen zelfs kleine onnauwkeurigheden tot aanzienlijke gevolgen leiden, waardoor de betrouwbaarheid van door AI gegenereerde resultaten een niet-onderhandelbare vereiste wordt.
FACTS Grounding’s nadruk op feitelijkheid en naleving van bronmateriaal zorgt ervoor dat modellen worden getest onder omstandigheden die de eisen uit de echte wereld nauw weerspiegelen.
In medische contexten bijvoorbeeld, een LLM die belast is met Het samenvatten van patiëntendossiers moet voorkomen dat er fouten worden geïntroduceerd die behandelbeslissingen verkeerd kunnen beïnvloeden. Op dezelfde manier vereist het genereren van samenvattingen of analyses van jurisprudentie in juridische contexten een nauwkeurige onderbouwing van de aangeleverde documenten.
FACTS Grounding evalueert niet alleen modellen op hun vermogen om aan deze strenge eisen te voldoen, maar stelt ook een benchmark vast waar ontwikkelaars naar kunnen streven bij het creëren van systemen die geschikt zijn voor dergelijke toepassingen.
Uitbreiden de FACTS-dataset en toekomstige richtingen
DeepMind heeft FACTS Grounding gepositioneerd als een ‘levende benchmark’, een benchmark die mee zal evolueren naast de vooruitgang op het gebied van AI. Toekomstige updates zullen de dataset waarschijnlijk uitbreiden met nieuwe domeinen en taaktypen, waardoor de blijvende relevantie ervan wordt gegarandeerd naarmate de LLM-mogelijkheden groeien.
Bovendien zou de introductie van meer diverse evaluatiesjablonen de robuustheid van het scoreproces verder kunnen vergroten, waardoor randgevallen kunnen worden aangepakt en resterende vooroordelen kunnen worden verminderd.
p>
Zoals het onderzoeksteam van DeepMind erkent, kan geen enkele benchmark de complexiteit van toepassingen in de echte wereld volledig inkapselen. Door echter voort te bouwen op FACTS Grounding en de bredere AI-gemeenschap erbij te betrekken, wil het project de lat hoger leggen feitelijkheid en verankering in AI-systemen.
Zoals het team van DeepMind stelt: “Feitaliteit en gronding behoren tot de sleutelfactoren die het toekomstige succes en de bruikbaarheid van LLM’s en bredere AI-systemen zullen bepalen, en we streven ernaar om FACTS Grounding te laten groeien en te herhalen naarmate het veld vordert. voortdurend de lat hoger leggen.”