TL;DR
De essentie: Google Research heeft Titans onthuld, een nieuwe neurale architectuur die gebruikmaakt van testtijdtraining om modellen in realtime gegevens te laten leren en onthouden tijdens gevolgtrekkingen. Belangrijkste specificaties: De architectuur bereikt een effectieve terugroepactie bij contextvensters van meer dan 2 miljoen tokens, wat aanzienlijk beter presteert dan GPT-4 op de BABILong-benchmark voor ophaaltaken. Waarom het belangrijk is: Titans vermindert het catastrofale vergeten dat werd waargenomen in eerdere lineaire RNN’s op lange-contextbenchmarks substantieel. De wisselwerking: hoewel Titans qua rekenkracht potentieel zwaarder is dan statische inferentiemodellen zoals IBM Granite, zou Titans superieure expressiviteit kunnen bieden voor complexe taken zoals juridische ontdekking of genomische analyse.
Google Research heeft ‘Titans’onthuld, een nieuwe neurale architectuur die de fundamentele rigiditeit van de huidige AI-modellen uitdaagt door ze in realtime te laten’leren onthouden’tijdens inferentie.
In tegenstelling tot traditionele Transformers die afhankelijk zijn van statische gewichten of Recurrent Neural Netwerken (RNN’s) die gebruik maken van verval in vaste toestand, Titans maakt gebruik van een”Neural Memory”-module. Deze component werkt zijn eigen parameters actief bij naarmate de gegevens binnenkomen, waardoor het contextvenster effectief wordt behandeld als een continue trainingslus in plaats van als een statische buffer.
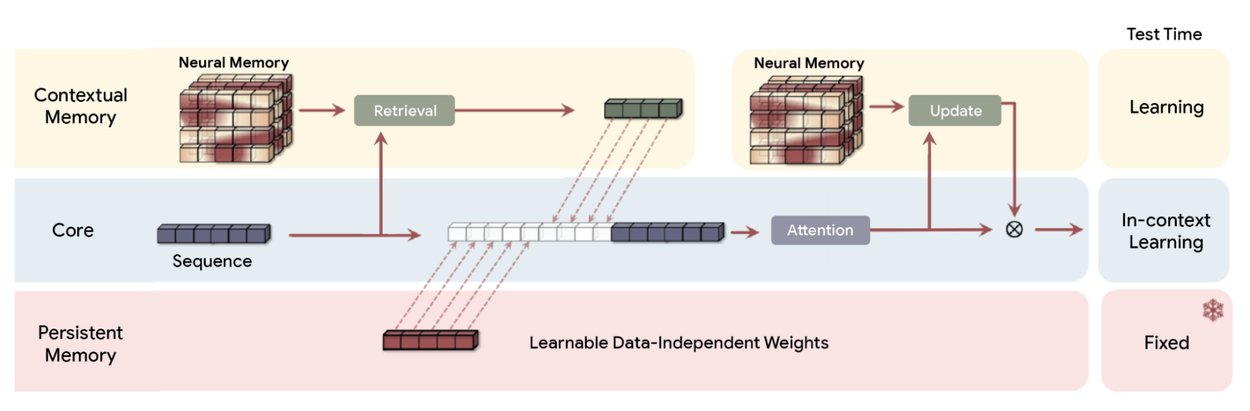
Demonstreert effectieve herinnering bij het overschrijden van contextvensters Met 2 miljoen tokens presteert de architectuur aanzienlijk beter dan GPT-4 op de BABILong-benchmark. Deze’Needle-in-a-Hooiberg’-test daagt modellen uit om specifieke datapunten uit uitgebreide documenten te halen, een taak waar standaardmodellen vaak falen.
Promo
De paradigmaverschuiving van het’neurale geheugen’
De huidige AI-architecturen worden geconfronteerd met een fundamentele afweging tussen contextlengte en rekenefficiëntie. Transformers, de dominante architectuur achter modellen als GPT-4 en Claude, vertrouwen op een aandachtsmechanisme dat kwadratisch schaalt met de lengte van de reeks. Dit maakt extreem lange contexten computationeel onbetaalbaar.
Omgekeerd comprimeren lineaire RNN’s zoals Mamba de context in een vector met een vaste toestand. Hoewel dit een oneindige lengte mogelijk maakt, resulteert dit vaak in ‘catastrofaal vergeten’, omdat nieuwe gegevens oude informatie overschrijven. Titans introduceert een derde pad:’Test-Time Training'(TTT).
In plaats van de gewichten van het model na de initiële trainingsfase te bevriezen, zorgt de Titans-architectuur ervoor dat de geheugenmodule blijft leren tijdens inferentie. Door het contextvenster als een gegevensset te behandelen, voert het model een mini-gradiënt-afdalingslus uit op de binnenkomende tokens. Hierdoor worden de interne parameters bijgewerkt om het specifieke document dat het verwerkt beter weer te geven.
Zoals het Google Research-team uitlegt:”in plaats van informatie te comprimeren in een statische toestand, leert deze architectuur actief zijn eigen parameters kennen en bijwerken naarmate de gegevens binnenstromen.”
Door dit actieve leerproces past het model zijn compressiestrategie dynamisch aan, waarbij prioriteit wordt gegeven aan informatie die relevant is voor de huidige taak in plaats van een one-size-fits-all vervalfunctie toe te passen.
Overzicht van de Titans (MAC)-architectuur. Het maakt gebruik van een langetermijngeheugen om de gegevens uit het verleden te comprimeren en vervolgens de samenvatting in de context op te nemen en onder de aandacht te brengen. De aandacht kan dan beslissen of het aandacht moet schenken aan de samenvatting van het verleden of niet. (Bron: Google)
Om de rekenoverhead te beheren, gebruikt Titans een “Verrassingsmetriek” gebaseerd op gradiëntfouten. Bij het verwerken van een nieuw token berekent het model het verschil tussen de voorspelling en de daadwerkelijke invoer. Een hoge fout duidt op “verrassing”, wat betekent dat de informatie nieuw is en moet worden onthouden. Een kleine fout duidt erop dat de informatie overbodig of al bekend is.
Aan de hand van een concreet voorbeeld merken de onderzoekers op dat”als het nieuwe woord’kat’is en de geheugenstatus van het model al een dierlijk woord verwacht, de gradiënt (verrassing) laag is. Het onthouden kan veilig worden overgeslagen.”
Dergelijke selectieve memorisatie bootst de biologische efficiëntie na, waardoor het systeem routinematige gegevens kan weggooien terwijl kritische afwijkingen of nieuwe feiten behouden blijven.
Dit actief aanvullen. leren is een adaptief ‘vergeetmechanisme’. Deze functie fungeert als poort en past gewichtsverval toe op de geheugenparameters wanneer de narratieve context aanzienlijk verandert. Door de inname van verrassende nieuwe gegevens in evenwicht te brengen met de gecontroleerde vrijgave van verouderde informatie, behoudt Titans een hifi-weergave van de context.
Dit voorkomt dat het model bezwijkt voor de ruis die fixed-state modellen teistert. Het Nested Learning-paradigma definieert de theoretische basis voor deze aanpak:
“Nested Learning laat zien dat een complex ML-model feitelijk een reeks coherente, onderling verbonden optimalisatieproblemen is die in elkaar zijn genest of parallel lopen.”
“Elk van deze interne problemen heeft zijn eigen contextstroom, zijn eigen specifieke set informatie waarvan het probeert te leren.”
Deze theoretische basis stelt dat architectuur en optimalisatie twee kanten van dezelfde medaille zijn. Door het model te beschouwen als een hiërarchie van optimalisatieproblemen, kan Titans gebruik maken van een diepe rekenkracht in zijn geheugenmodule. Dit lost het’catastrofale vergeetprobleem’op dat lange tijd de bruikbaarheid van terugkerende netwerken heeft beperkt.
Extreme context en benchmarks
Het meest opvallende is dat dit actieve geheugensysteem contextvensters afhandelt die traditionele architecturen doorbreken. Uit de benchmarks van Google blijkt dat Titans een effectieve herinnering behoudt bij een contextlengte van meer dan 2.000.000 tokens. De meeste gebruikte productie-LLM’s, zoals GPT-4o, bereiken een maximum van ongeveer 128.000 tokens, hoewel een paar geavanceerde modellen nu ~1 miljoen bereiken.
In de uitdagende’Needle-in-a-Haystack'(NIAH)-tests, die het vermogen van een model meten om een specifiek feit op te halen dat verborgen is in een grote hoeveelheid niet-gerelateerde tekst, toonde Titans een aanzienlijke superioriteit ten opzichte van lineaire RNN-basislijnen. Bij de “Single Needle”-taak met synthetische ruis (S-NIAH-PK) met een tokenlengte van 8k behaalde de Titans MAC-variant een nauwkeurigheid van 98,8%, vergeleken met slechts 31,0% voor Mamba2.
De prestaties op natuurlijke taalgegevens waren eveneens robuust. Op de WikiText-versie van de test (S-NIAH-W) scoorde Titans MAC 88,2%, terwijl Mamba2 het moeilijk had met 4,2%. Dergelijke resultaten suggereren dat hoewel lineaire RNN’s efficiënt zijn, hun compressie met een vaste toestand kritische betrouwbaarheid verliest bij het omgaan met de complexe, luidruchtige gegevens die in echte documenten worden aangetroffen.
Benchmarkprestaties: Titans versus ultramoderne basislijnen
Het Google Research-team benadrukt mogelijkheden die verder gaan dan alleen het zoeken op trefwoorden en merkt op dat”het model niet alleen maar aantekeningen maakt; het begrijpt en synthetiseert het hele verhaal.”Door de gewichten bij te werken om de verrassing van de hele reeks te minimaliseren, bouwt het model een structureel begrip van de verhaallijn op. Hierdoor kan informatie worden opgehaald op basis van semantische relaties in plaats van alleen maar tokenmatching.
Google biedt een gedetailleerd overzicht van het bepalende kenmerk van de architectuur: de geheugenmodule. In tegenstelling tot traditionele Recurrent Neural Networks (RNN’s), die doorgaans worden beperkt door een vector-of matrixgeheugen met een vaste grootte, in wezen een statische container die gemakkelijk overvol of luidruchtig kan worden naarmate de gegevens zich ophopen, introduceert Titans een nieuwe neurale langetermijngeheugenmodule.
Deze module functioneert op zichzelf als een diep neuraal netwerk, waarbij specifiek gebruik wordt gemaakt van een meerlaags perceptron (MLP). Door het geheugen te structureren als een leerbaar netwerk in plaats van als een statische opslag, bereikt Titans een aanzienlijk grotere expressieve kracht. Deze architectonische verschuiving stelt het model in staat om grote hoeveelheden informatie dynamisch op te nemen en samen te vatten.
In plaats van simpelweg oudere gegevens af te korten of te comprimeren naar een low-fidelity-status om ruimte te maken voor nieuwe invoer, synthetiseert de MLP-geheugenmodule de context, waardoor wordt verzekerd dat kritische details en semantische relaties behouden blijven, zelfs als het contextvenster zich uitbreidt naar de miljoenen tokens.
Naast de nauwkeurigheid van het ophalen is Titans ook veelbelovend in algemene taalmodellering. efficiëntie. Op de schaal van 340 miljoen parameters behaalde de Titans MAC-varianbench een perplexiteit van 25,43 op de WikiText-dataset. Dergelijke prestaties overtreffen zowel de Transformer++-basislijn (31.52) als de originele Mamba-architectuur (30.83).
Dit geeft aan dat de actieve geheugenupdates een betere weergave bieden van taalwaarschijnlijkheidsverdelingen dan alleen statische gewichten. Ali Behrouz, een hoofdonderzoeker van het project, benadrukt de theoretische implicaties van dit ontwerp en stelt dat”Titans in staat zijn om problemen op te lossen die verder gaan dan TC0, wat betekent dat Titans theoretisch expressiever zijn dan Transformers en de meeste moderne lineaire terugkerende modellen bij het volgen van toestanden.”
Dergelijke expressiviteit stelt Titans in staat om taken voor het volgen van toestanden uit te voeren, zoals het volgen van de veranderende variabelen in een lang codebestand of het volgen van de plotpunten van een roman, die vaak eenvoudiger terugkerende taken verwarren modellen.
Efficiëntie: MIRAS versus de markt
Om deze architecturale innovaties te formaliseren heeft Google het MIRAS-framework geïntroduceerd. Door verschillende benaderingen van sequentiemodellering te verenigen, waaronder Transformers, RNNs en Titans, opereert het model onder de paraplu van ‘associatief geheugen.
Volgens Google deconstrueert het MIRAS-framework sequentiemodellering in vier fundamentele ontwerpkeuzes. De eerste is de geheugenarchitectuur, die de structurele vorm dicteert die wordt gebruikt om informatie op te slaan, variërend van eenvoudige vectoren en matrices tot de diepe meerlaagse perceptrons die in Titans worden aangetroffen. Dit gaat gepaard met Attentional Bias, een intern leerdoel dat bepaalt hoe het model binnenkomende gegevens prioriteert en effectief bepaalt wat belangrijk genoeg is om te onthouden.
Om de capaciteit te beheren, maakt het raamwerk gebruik van een Retention Gate. MIRAS herinterpreteert traditionele ‘vergeetmechanismen’ als specifieke vormen van regularisatie, waardoor een stabiel evenwicht wordt gegarandeerd tussen het leren van nieuwe concepten en het behouden van de historische context. Ten slotte bepaalt het geheugenalgoritme de specifieke optimalisatieregels die worden gebruikt om de geheugenstatus bij te werken, waardoor de cyclus van actief leren wordt voltooid.
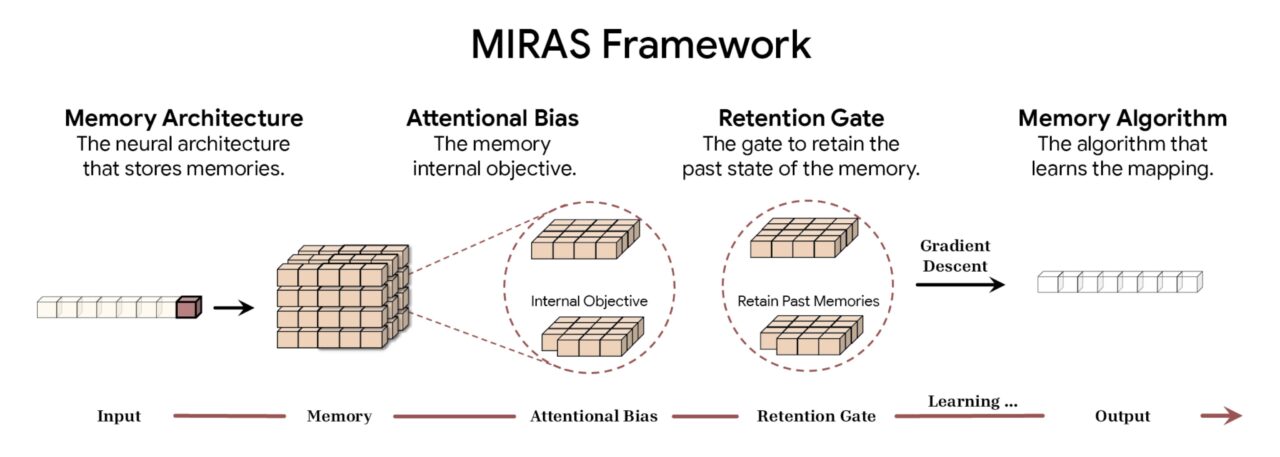 MIRAS-frameworkoverzicht (bron: Google)
MIRAS-frameworkoverzicht (bron: Google)
Door de volgorde op te splitsen Door deze vier componenten te modelleren, demystificeert MIRAS de ‘magie’ van aandachtsmechanismen. Het classificeert ze opnieuw als slechts één type associatief geheugen met specifieke instellingen voor bias en retentie. Onderzoekers kunnen dus componenten mixen en matchen, wat mogelijk kan leiden tot hybride architecturen die de precisie van aandacht combineren met de efficiëntie van herhaling.
Architecturale paradigmaverschuiving: het MIRAS Framework
Dynamisch geheugen met hoge capaciteit staat in schril contrast met de heersende trend in Edge AI, waarbij het doel vaak is om statische modellen voor lokale implementatie te verkleinen. De Granite 4.0 Nano-lancering door IBM introduceerde bijvoorbeeld modellen zo klein als 350 miljoen parameters die ontworpen zijn om op laptops te draaien.
Terwijl de strategie van IBM zich richt op het alomtegenwoordig en goedkoop maken van statische intelligentie, is de Titans-aanpak van Google erop gericht het model zelf slimmer en beter aanpasbaar te maken. Dit is zelfs van toepassing als hiervoor de rekenkundige overhead nodig is van het bijwerken van gewichten tijdens inferentie.
Computationele overhead, of de ‘Context Gap’, blijft de belangrijkste hindernis voor Titans. Het in realtime bijwerken van geheugenparameters is computationeel duurder dan de statische gevolgtrekking die wordt gebruikt door modellen als Granite of Llama. Voor toepassingen die een diepgaand begrip van grootschalige datasets vereisen, zoals juridische ontdekking, genomische analyse of refactoring van codebases, kan het vermogen om het document te’leren’echter waardevoller blijken dan de snelheid van ruwe gevolgtrekking.
De’Hope’-architectuur, die diende als de eerste implementatie van deze zelfmodificerende visie, werd geïntroduceerd als een proof-of-concept in de Nested Learning-paper. Terwijl de industrie blijft aandringen op langere contexten en diepere redeneringen, kunnen architecturen zoals Titans, die de grens tussen training en gevolgtrekking doen vervagen, de volgende generatie basismodellen definiëren.