Het AI-team van Meta staat onder grote druk na de release van het R1-model van DeepSeek, dat de AI-industrie heeft uitgedaagd met zijn ongekende efficiëntie en prestaties.
Anonieme berichten op het professionele netwerkplatform Blind onthullen onrust binnen de gelederen van Meta, waarbij ingenieurs een verwoede poging beschrijven om het succes van DeepSeek te begrijpen en te repliceren, terwijl ze worstelen met interne inefficiënties en leiderschapsfouten.
Blind is een anoniem professioneel netwerkplatform waar werknemers informatie kunnen delen, kunnen discussiëren problemen op de werkplek, en netwerken met collega’s in dezelfde of verschillende sectoren. Het heeft een verificatiesysteem om ervoor te zorgen dat gebruikers daadwerkelijke werknemers zijn van de bedrijven waarvoor ze beweren te werken, en is vooral populair onder professionals in de technische industrie.
Gerelateerd: Hoe DeepSeek R1 overtreft ChatGPT o1 onder sancties, waardoor AI-efficiëntie opnieuw wordt gedefinieerd met slechts 2.048 GPU’s
Eén anonieme Meta-medewerker, post onder de naam “ngi”, vatte de stemming binnen de GenAI-divisie van Meta samen:
“Het begon met DeepSeek V3 [een DeepSeek-model uitgebracht in december 2024], waardoor Llama 4 al achterop raakte in de benchmarks. Wat het nog erger maakte, was het’onbekende Chinese bedrijf met een trainingsbudget van 5,5 miljoen’verwoed bezig om DeepSeek te ontleden en alles wat we maar kunnen ervan te kopiëren.
Ik overdrijf niet eens. Het management maakt zich zorgen over het rechtvaardigen van de enorme kosten van de GenAI-organisatie. Hoe zouden ze tegenover het leiderschap staan als iedere ‘leider’ van GenAI org meer verdient dan wat het kost om DeepSeek V3 volledig te trainen, en we hebben tientallen van zulke ‘leiders’. DeepSeek R1 maakte de zaken nog enger. Ik kan geen vertrouwelijke informatie vrijgeven, maar die zal toch binnenkort openbaar zijn.
Het had een op techniek gerichte kleine organisatie moeten zijn, maar omdat een aantal mensen mee wilden doen aan de impactgreep en het personeelsbestand kunstmatig wilden vergroten org verliest iedereen.”
De opmerkingen van de medewerker benadrukken de interne ontevredenheid over Meta’s benadering van AI-ontwikkeling, die door velen wordt omschreven als overdreven bureaucratisch, arbeidsintensief en gedreven door oppervlakkige statistieken in plaats van betekenisvol innovatie
De release van DeepSeek R1 heeft deze tekortkomingen blootgelegd en een afrekening afgedwongen voor een van de grootste spelers in de AI-industrie.
Gerelateerd: LLaMA AI Under. Fire – Wat Meta je niet vertelt over ‘open source’-modellen
DeepSeek R1 zendt schokgolven door de Amerikaanse technologiesector
Het R1-model van DeepSeek, uitgebracht op 10 januari 2025, heeft het mondiale AI-landschap op zijn kop gezet door aan te tonen dat krachtige modellen kunnen worden ontwikkeld tegen een fractie van de kosten die doorgaans aan dergelijke projecten zijn verbonden.
Met behulp van Nvidia H800 GPU’s (chips van lagere kwaliteit die beperkt zijn door Amerikaanse exportcontroles) hebben de technici van DeepSeek het model getraind voor minder dan $ 6 miljoen, volgens een onderzoekspaper uitgebracht in december 2024.
Deze GPU’s, die opzettelijk werden beperkt om te voldoen aan Amerikaanse sancties, vormden unieke uitdagingen, maar dankzij de optimalisatietechnieken van DeepSeek kon het team vergelijkbare prestaties bereiken als toonaangevende modellen.
De benchmarks van R1 omvatten een score van 97,3% op MATH-500 en een score van 79,8% op AIME 2024, waardoor het een van de meest capabele AI-systemen ter wereld is.
De efficiëntie van DeepSeek R1, dat ook gedeeltelijk beter presteert dan het o1-model van OpenAI, heeft niet alleen het vertrouwen in Amerikaanse technologiegiganten als Meta geschokt, maar ook aanzienlijke marktreacties teweeggebracht.
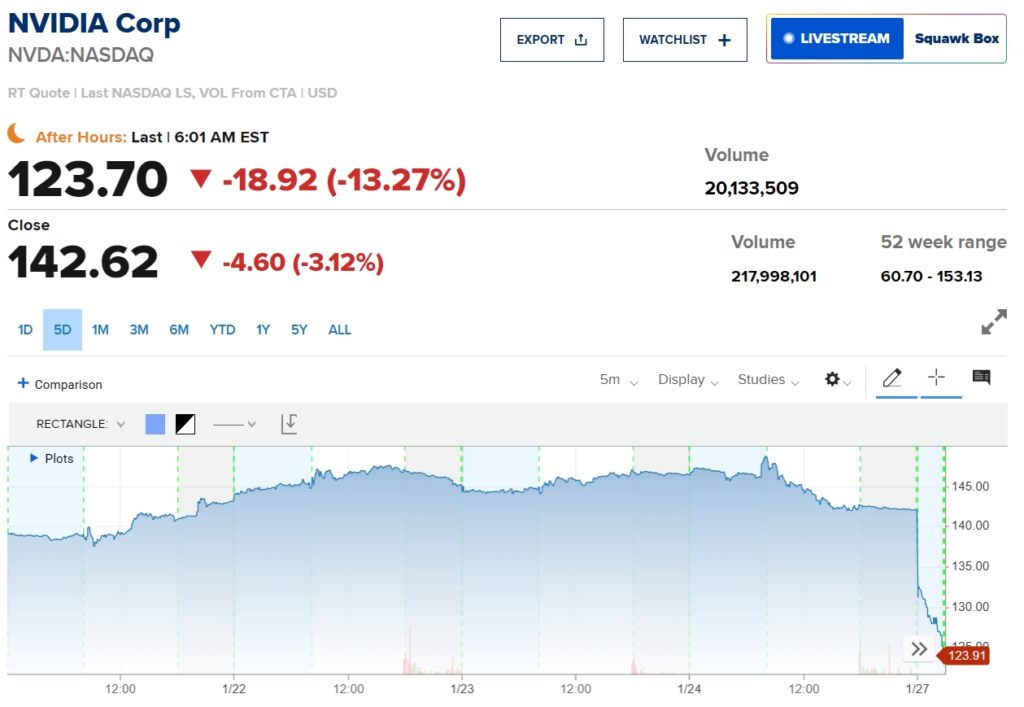
De aandelen van Nvidia daalden met meer dan 13% in premarket-handel na de release van het model, en de Nasdaq 100-futures daalden met meer dan 5%. Ondertussen is DeepSeek naar de eerste plaats geklommen in de Amerikaanse App Store van Apple en overtreft daarmee OpenAI’s ChatGPT in downloads.
Meta-ingenieurs twijfelen aan de afhankelijkheid van dure computer-AI-training
Binnen Meta hebben ingenieurs kritiek geuit op de afhankelijkheid van het bedrijf van brute rekenkracht in plaats van het nastreven van efficiëntiegedreven innovatie.
Een medewerker merkte op Blind op: Veel leiders hebben letterlijk geen idee (zelfs veel techniek) van de onderliggende technologie en ze blijven’meer GPU’s=winst’aan de leiders verkopen.”frustratie over de cultuur van’impactchasing’, die het omschrijft als een race om promoties in plaats van een toewijding aan betekenisvolle vooruitgang.
Meta’s AI-inspanningen zijn ook onder de loep genomen vanwege hun gebrek aan wendbaarheid in vergelijking met concurrenten. Het R1-model van DeepSeek is niet alleen kosteneffectief, maar ook open-source, waardoor ontwikkelaars over de hele wereld de architectuur ervan kunnen onderzoeken en erop kunnen voortbouwen.
De Blind-discussies brengen ook bredere zorgen binnen de sector aan het licht. Google-medewerkers erkenden de ontwrichtende impact van DeepSeek met één opmerking: “Het is echt krankzinnig wat DeepSeek doet. Het is niet alleen Meta, ze steken ook een vuurtje aan onder de kont van OpenAI, Google en Anthropic. Dat is een goede zaak, we zien in realtime hoe effectief een open concurrentie is voor innovatie.”
Dit sentiment weerspiegelt de groeiende erkenning dat traditionele strategieën die veel hulpbronnen vergen, mogelijk niet langer de dominantie in de AI-ontwikkeling garanderen.
Deze transparantie heeft lof gekregen van marktleiders, waaronder Meta’s eigen Chief AI Scientist, Yann LeCun, die op LinkedIn schreef: “DeepSeek heeft geprofiteerd van open onderzoek en open source (bijv. PyTorch en Llama van Meta). Ze kwamen met nieuwe ideeën en bouwden deze voort op het werk van anderen.”
Mark Zuckerberg verdubbelt investeringen in AI-infrastructuur
In schril contrast hiermee heeft Meta zich gericht op grootschalige infrastructuurinvesteringen. CEO Mark Zuckerberg heeft onlangs plannen aangekondigd om in 2025 meer dan 1,3 miljoen GPU’s in te zetten en 60 tot 65 miljard dollar te investeren in de ontwikkeling van AI.
“Dit is een enorme inspanning, en de komende jaren zal het onze kernproducten en-activiteiten aandrijven, historische innovatie ontsluiten en het Amerikaanse technologische leiderschap vergroten”, zei Zuckerberg eerder dit jaar in een openbare verklaring. Deze plannen lijken nu echter steeds meer in strijd te zijn met de gestroomlijnde, op efficiëntie gerichte aanpak van DeepSeek.
De opkomst van DeepSeek heeft sinds 2021 ook de debatten over Amerikaanse exportbeperkingen op AI-gerelateerde technologieën naar China nieuw leven ingeblazen. de regering-Biden heeft maatregelen geïmplementeerd om de toegang van China tot geavanceerde chips, waaronder Nvidia’s H100 GPU’s, te beperken.
Het vermogen van DeepSeek om resultaten van wereldklasse te behalen met beperkte hardware onderstreept echter de beperkingen van dit beleid door het aanleggen van voorraden van H800 GPU’s Voordat de sancties volledig van kracht werden en zich concentreerde op efficiëntie, heeft DeepSeek beperkingen omgezet in voordelen hedgefondsmanager beschreef de strategie van het bedrijf: “Wij schatten dat de beste binnenlandse en buitenlandse modellen een kloof van één factor kunnen hebben in de modelstructuur en de trainingsdynamiek. Om deze reden moeten we vier keer meer rekenkracht verbruiken om hetzelfde effect te bereiken. Wat we moeten doen is deze gaten voortdurend verkleinen.”
Terwijl de AI-industrie worstelt met de implicaties van het succes van DeepSeek, wordt Meta geconfronteerd met een dringende noodzaak om zich aan te passen. De werknemers van het bedrijf hebben hun frustraties duidelijk gemaakt en opgeroepen tot een verschuiving naar efficiëntere, innovatiegedreven strategieën. Voorlopig geldt het R1-model van DeepSeek als een krachtige demonstratie van vindingrijke engineering, die de concurrentiedynamiek van de mondiale AI-ontwikkeling opnieuw vormgeeft.