Onderzoekers van Google hebben een nieuw raamwerk geïntroduceerd met de naam Chain-of-Agents (CoA), ontworpen om een van de meest hardnekkige beperkingen van grote taalmodellen (LLM’s) aan te pakken: het omgaan met taken met een lange context.
CoA maakt gebruik van een samenwerkingsmodel met meerdere agenten om de efficiëntie en redeneernauwkeurigheid aanzienlijk te verbeteren bij taken zoals samenvattingen, het beantwoorden van vragen en het voltooien van code.
Door lange invoer op te delen in kleinere, beheersbare Door chunks te verdelen en deze toe te wijzen aan gespecialiseerde agenten, levert het raamwerk betere resultaten op dan traditionele benaderingen zoals Retrieval-Augmented Generation (RAG) en Full-Context-modellen.
Gerelateerd: Google onthult Agentspace om het groeiende AI-ecosysteem van Microsoft uit te dagen
De CoA-framework biedt een paradigmaverschuiving voor AI, vooral op het gebied van zijn vermogen om uitgebreide input te verwerken die anders de beperkingen van LLM’s zou overschrijden. Google benadrukte de eenvoud en effectiviteit van de aanpak en omschreef deze als “trainingsvrij, taak-/lengte-agnostisch, interpreteerbaar en kosteneffectief.”
De uitdagingen van AI-taken met lange context
Een van de grootste obstakels bij het bevorderen van AI-mogelijkheden ligt in het beheren van invoer met lange context. De meeste LLM’s werken met een vast contextvenster dat hun vermogen beperkt om grote datasets te verwerken zonder afkapping
Methoden voor invoerreductie, zoals RAG, proberen dit te ondervangen door alleen de meest relevante delen van de invoer op te halen. Deze aanpak heeft echter vaak te kampen met een lage ophaalnauwkeurigheid, wat leidt tot onvolledige informatie strong>Gerelateerd: NVIDIA verbetert Agentic AI met Llama-en Cosmos Nemotron-modellen
Aan de andere kant breiden Full-Context-modellen hun verwerkingscapaciteit uit, maar worden vooral geconfronteerd met rekeninefficiënties naarmate de invoerlengte toeneemt. Deze modellen worden vaak geconfronteerd met het’lost-in-the-middle’-probleem, waarbij kritieke informatie in het midden van de dataset geen prioriteit meer krijgt.
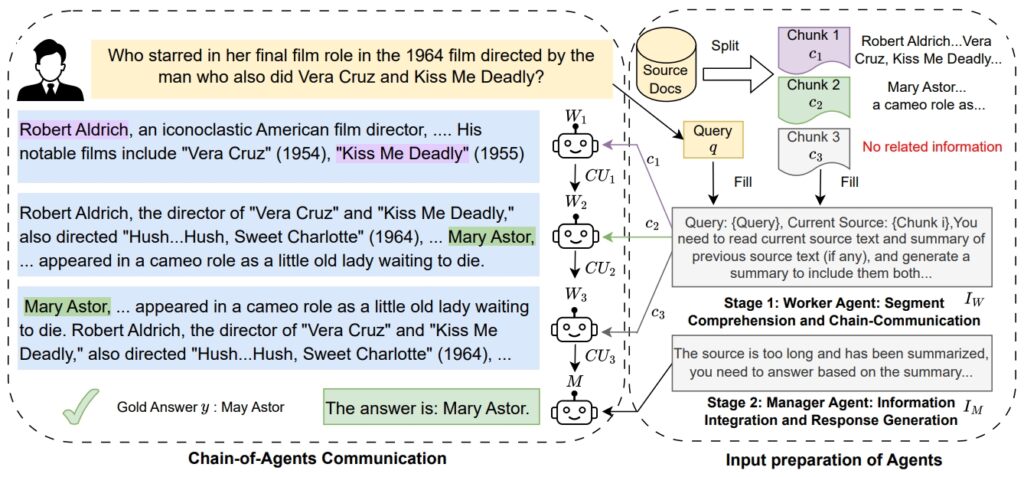
Het CoA-framework van Google pakt deze problemen aan door gebruik te maken van een samenwerkingssysteem waarbij werkagenten specifieke segmenten van de invoer opeenvolgend verwerken. Elke werkagent verfijnt en draagt zijn bevindingen over aan de volgende, zodat er geen context verloren gaat.
Een manager-agent synthetiseert vervolgens alle verzamelde informatie om een definitief antwoord te produceren. Deze stapsgewijze aanpak bootst het oplossen van menselijke problemen na, waarbij taken in kleinere delen worden opgedeeld voor een betere focus en nauwkeurigheid.
 Afbeelding: Google
Afbeelding: Google
De onderzoekers van Google benadrukten de motivatie achter het raamwerk en stelt: “Als het venster zelfs langer wordt dan hun uitgebreide invoercapaciteiten, hebben dergelijke LLM’s nog steeds moeite om zich te concentreren op de benodigde informatie om de taak op te lossen en lijden ze onder ineffectief gebruik van de context, zoals het’lost in the middle’-probleem.”
Hoe Chain-of-Agents werkt
Het Chain-of-Agents-framework werkt in twee verschillende fasen. In de eerste fase verwerken werkagenten toegewezen stukjes invoer, waarbij taken worden uitgevoerd zoals het extraheren van ondersteuning bewijsmateriaal of het doorsturen van relevante bevindingen.
Deze communicatieketen zorgt ervoor dat elke medewerker voortbouwt op de inzichten van de vorige. In de tweede fase verzamelt de manager-agent al het verzamelde bewijsmateriaal en genereert een samenhangend eindresultaat. Deze hiërarchische structuur verbetert niet alleen de nauwkeurigheid van redeneren, maar verlaagt ook de rekenkosten.
Gerelateerd: Salesforce onthult Agentforce 2.0, breidt AI-agenten verder uit dan CRM
Google legde de Het ontwerp van het raamwerk bestaat uit het”verweven van lezen en redeneren, waarbij elke agent een korte context wordt toegewezen.”Met deze aanpak kan CoA lange contexten afhandelen zonder dat LLM’s alle tokens tegelijkertijd moeten verwerken.
Door de rekenkracht te verminderen complexiteit biedt CoA een efficiëntere en schaalbare oplossing voor taken met een lange context.
Superieure prestaties in alle benchmarks
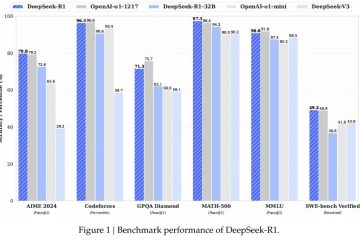
Google heeft uitgebreide experimenten uitgevoerd met negen datasets om de De prestaties van CoA omvatten verschillende domeinen, waaronder het beantwoorden van vragen (bijvoorbeeld HotpotQA, MuSiQue), samenvatting (bijvoorbeeld QMSum, GovReport) en het voltooien van code. (bijv. RepoBench-P).
CoA presteerde consistent beter dan RAG-en Full-Context-modellen in termen van zowel nauwkeurigheid als efficiëntie.
 Bron: Google
Bron: Google
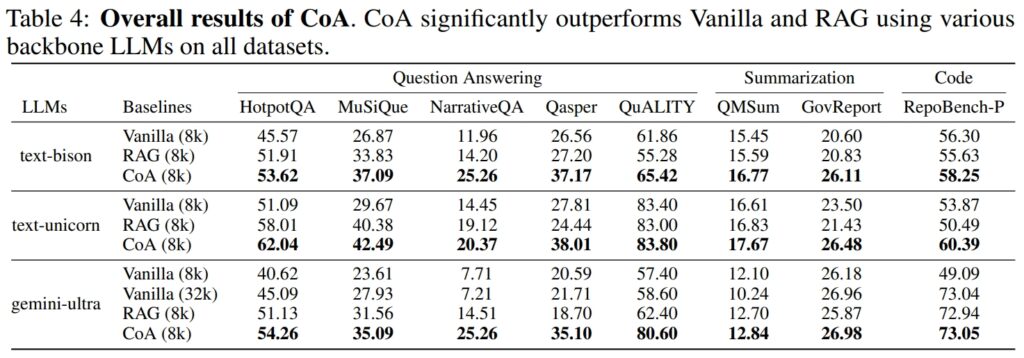
Op de HotpotQA-dataset blonk CoA bijvoorbeeld uit in multi-hop-redenering, een taak waarbij informatie uit meerdere bronnen moet worden gesynthetiseerd om tot een resultaat te komen. accuraat antwoord.
Hoewel RAG er vaak niet in slaagde semantisch onsamenhangende maar contextueel relevante stukjes informatie met elkaar te verbinden, bracht CoA systematisch inzichten uit elk inputfragment samen. Google merkte op:”Onze resultaten laten zien dat CoA op alle negen datasets een verbetering tot 10% behaalt ten opzichte van alle basislijnen.”
Op de NarrativeQA-dataset demonstreerde CoA zijn vermogen om Full-Context-modellen te overtreffen, zelfs degenen die in staat zijn om 200.000 tokens te verwerken, door het contextvenster te beperken tot 8.000 tokens en de multi-agent-aanpak te gebruiken, handhaafde CoA hoge prestaties terwijl de rekenkosten aanzienlijk werden verlaagd.
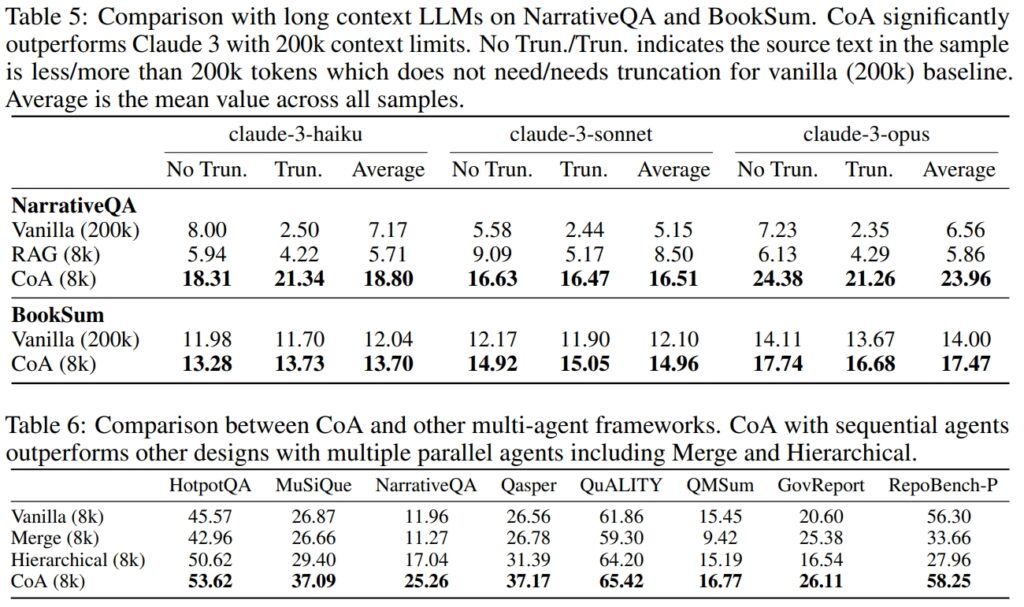 Bron: Google
Bron: Google
Toepassingen in realistische scenario’s
De praktische toepassingen van CoA strekken zich uit over meerdere sectoren. Bij juridische analyse kan CoA uitgebreide juridische documenten verwerken en kritische informatie identificeren zonder belangrijke details te missen. In de gezondheidszorg zou het raamwerk patiëntendossiers uit verschillende bronnen kunnen samenvoegen om uitgebreide diagnostische inzichten te bieden.
Academische en overheidsinstellingen zouden CoA kunnen gebruiken voor het samenvatten van onderzoek, waarbij bevindingen uit grote datasets worden gesynthetiseerd.
Het vermogen van CoA om taken voor het voltooien van code af te handelen, benadrukt ook het potentieel ervan in softwareontwikkeling. Door grote codebases te analyseren en afhankelijkheden te identificeren, kan het raamwerk de workflows optimaliseren voor ontwikkelaars die met complexe systemen werken.
Gerelateerd: Cognition.ai introduceert zijn Devin AI Software Engineer voor $ 500/maand
Vergelijkingen met concurrenten uit de sector
De introductie van CoA door Google weerspiegelt een groeiende nadruk op afzonderlijke AI-agenten en op samenwerking gerichte AI-agentframeworks binnen de technologie-industrie. OpenAI heeft zojuist Operator gelanceerd, een browsergebaseerde AI-agent ontworpen voor taakautomatisering, terwijl Microsoft AutoGen v0.4 onthulde met het Magic-One-framework voor workflows met meerdere agenten.
Het CoA van Google onderscheidt zich door specifiek te focussen op lange-context redeneren en taakverwerking.
Volgens de onderzoekers van Google ontvangen LLM’s vaak een onvolledige context vanwege beperkingen in traditionele methoden, maar CoA lost dit op door de gehele invoer gezamenlijk te verwerken via meerdere agenten.
Deze focus op taken met een lange context geeft CoA een unieke voorsprong op gebieden die uitgebreide informatiesynthese vereisen.
Een glimp In de toekomst van AI
De introductie van CoA benadrukt een bredere trend in de AI-ontwikkeling in de richting van modulaire en collaboratieve systemen. Door gespecialiseerde agenten in staat te stellen samen te werken, laat CoA zien hoe het verdelen van taken de nauwkeurigheid en schaalbaarheid kan verbeteren.
Het raamwerk zou de weg kunnen vrijmaken voor vooruitgang op het gebied van kunstmatige algemene intelligentie (AGI), waarbij systemen in staat zijn tot redeneren en probleemoplossing op menselijk niveau.
De inspanningen van Google benadrukken ook het belang van kosteneffectieve en interpreteerbare oplossingen in zakelijke AI.