Microsoft heeft Phi-4, het compacte taalmodel, open source gemaakt voor het publiek door zijn volledige gewicht op Hugging Face onder een MIT-licentie vrij te geven.
Phi-4, voor het eerst geïntroduceerd in december 2024 tot en met Het Azure AI Foundry-platform van Microsoft was aanvankelijk alleen beschikbaar voor onderzoekers onder een gecontroleerde licentie. Met de open-source release biedt Microsoft onderzoekers en ontwikkelaars over de hele wereld de tools om het compacte maar toch goed presterende model aan te passen, te implementeren en te commercialiseren.
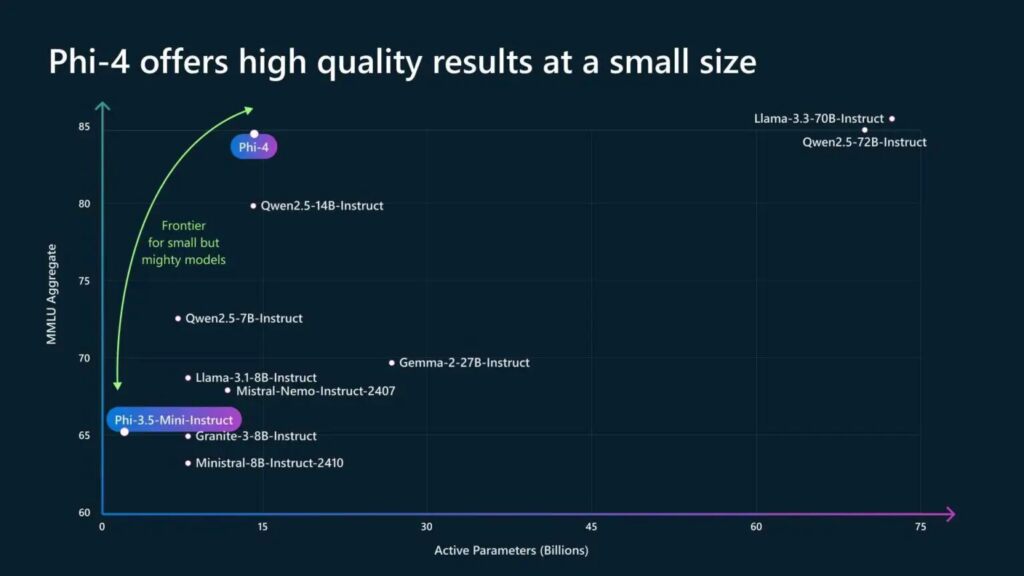
Phi-4: een compact model met buitenmaats formaat Resultaten
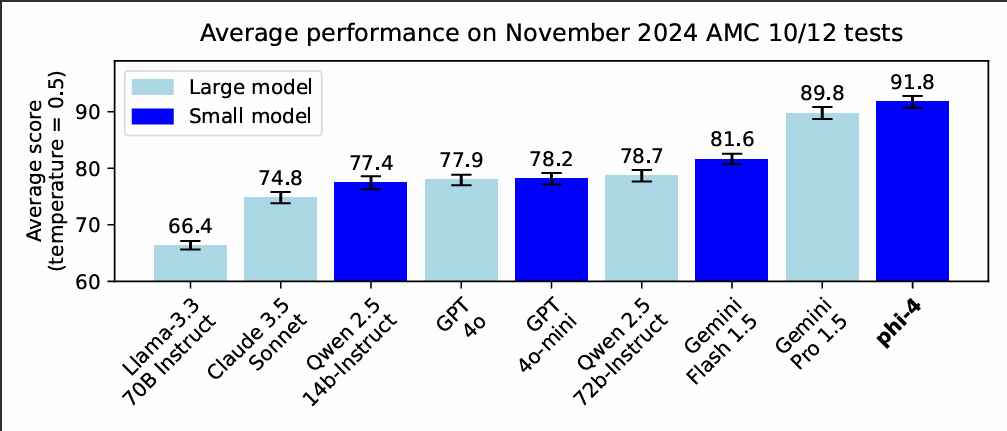
Phi-4 vertegenwoordigt een afwijking van de traditionele AI-ontwikkeling, die vaak prioriteit heeft gegeven aan schaal als de belangrijkste maatstaf voor prestaties. Met slechts 14 miljard parameters levert Phi-4 resultaten die wedijveren met en zelfs overtreffen van grotere tegenhangers, zoals Google’s Gemini Pro 1.5 en OpenAI’s GPT-4o.
 Bron: Microsoft
Bron: Microsoft
In recente benchmarks Phi-4 scoorde een indrukwekkende 91,8 op de American Mathematics Competition (AMC 12), en presteerde beter dan de score van Gemini Pro 1.5 89,8 en GPT-4o’s 77,9.
Microsoft demonstreerde de wiskundige redeneermogelijkheden van Phi-4 via een combinatorisch probleem, waarbij het model nauwkeurig 431 verschillende permutaties berekende voor een hypothetisch ras waarbij vijf slakken betrokken waren.
 Phi-4 presteert beter dan veel grotere modellen, waaronder Gemini Pro 1.5, wat betreft wiskundige concurrentieproblemen (Bron: Microsoft)
Phi-4 presteert beter dan veel grotere modellen, waaronder Gemini Pro 1.5, wat betreft wiskundige concurrentieproblemen (Bron: Microsoft)
Dit nauwkeurigheidsniveau benadrukt het potentieel ervan voor domeinen die logische en wiskundige nauwkeurigheid vereisen, zoals zoals financiën, techniek en wetenschappelijk onderzoek.
Microsoft legde zijn doelstellingen voor Phi-4 uit in zijn officiële documentatie: “Phi-4 blijft de grens verleggen van omvang versus kwaliteit”, een sentiment dat wordt herhaald door onderzoekers die hebben de prestaties ervan vergeleken met modellen met vijf keer zoveel parameters.
Trainingsmethodologie en synthetische gegevens
De basis van het succes van Phi-4 ligt in zijn trainingsaanpak. Microsoft maakte gebruik van synthetische datasets bestaande uit: inhoud in leerboekstijl, met de nadruk op wiskundig redeneren, programmeren en op gezond verstand gebaseerde logica. Deze datasets, in totaal 9,8 biljoen tokens, werden aangevuld met samengestelde openbare documenten, academische teksten en meertalige data.
“In plaats van te dienen als een goedkope vervanging voor organische data, bieden synthetische data directe voordelen”, merkte Microsoft op in zijn technisch rapport benadrukte het de controle en het aanpassingsvermogen dat het biedt tijdens modeltraining. Deze aanpak verminderde ook de afhankelijkheid van web-scraped inhoud, die vaak werd bekritiseerd vanwege inconsistenties in de kwaliteit.
Om de prestaties van het model te verbeteren. Door te redeneren en op één lijn te brengen, paste Microsoft geavanceerde post-trainingstechnieken toe, zoals supervisie en directe voorkeursoptimalisatie. Deze methodologieën verfijnden het vermogen van Phi-4 om onderscheid te maken tussen output van hoge en lage kwaliteit, waardoor de nauwkeurigheid ervan in domeinspecifieke toepassingen verder werd vergroot..
Open-source beschikbaarheid
De beslissing om Phi-4 als open-source uit te brengen weerspiegelt de bredere strategie van Microsoft om AI-tools te democratiseren waar ontwikkelaars nu toegang toe hebben de model op Hugging Face, waar de volledige gewichten zijn beschikbaar onder een MIT-licentie. Shital Shah, een hoofdingenieur bij Microsoft, kondigde de release aan op X (voorheen Twitter) en schreef:”Veel mensen hadden ons om gewichtsvermindering gevraagd… Nou, wacht niet langer.”
We waren volledig verbaasd over de reacties op de release van phi-4. Veel mensen hadden ons om gewichtsvrijgave gevraagd. meer vandaag officieel phi-4-model op HuggingFace!
Met MIT-licentie!! p>— Shital Sjah (@sytelus) 8 januari 2025
De open-source release stelt ontwikkelaars in staat Phi-4 voor specifieke toepassingen zonder de rekenkundige overhead die doorgaans gepaard gaat met grotere modellen. De compacte, uitsluitend decoderende architectuur, een variant van het transformatormodel, minimaliseert de benodigde middelen, waardoor het zelfs toegankelijk wordt voor organisaties met een beperkte infrastructuur.
Ethische overwegingen en gevolgen voor de sector
De uitrol van Phi-4 door Microsoft benadrukt zijn toewijding aan verantwoorde inzet van AI. Het Azure AI Foundry-platform, dat aanvankelijk Phi-4 hostte, bevat veiligheidsmaatregelen zoals inhoudfiltering en vijandig testen. Deze maatregelen zijn bedoeld om risico’s zoals vooringenomenheid, desinformatie en het genereren van schadelijke inhoud te beperken.
Door Phi-4 uit te brengen onder een open-sourcelicentie komt Microsoft ook tegemoet aan de groeiende vraag naar transparantie in de AI-ontwikkeling. Deze stap komt overeen met trends in de sector die te zien zijn in releases als Meta’s Llama 3.2 en Google’s Gemma-serie, hoewel de opvallende prestaties van Phi-4 in benchmarks een nieuwe standaard zetten voor compacte modellen.
Phi-4 betwist de veronderstelling dat grotere modellen zijn inherent beter. Het compacte ontwerp verlaagt niet alleen de computer-en energiekosten, maar verbreedt ook de toegang tot geavanceerde AI-mogelijkheden. Deze efficiëntie is vooral waardevol voor middelgrote organisaties en onderzoekers die niet over de middelen beschikken om enorme modellen in te zetten.
Terwijl AI blijft evolueren, biedt Phi-4 een kijkje in een toekomst waarin kleinere, slimmere modellen elkaar kunnen ontmoeten voldoet aan de eisen van gespecialiseerde taken zonder dat dit ten koste gaat van de prestaties.