Het Qwen-onderzoeksteam van Alibaba heeft QVQ-72B geïntroduceerd, een open-source multimodaal AI-model dat is ontworpen om visueel en tekstueel redeneren te combineren. Met de mogelijkheid om afbeeldingen en tekst stap voor stap te verwerken, biedt het model een nieuwe benadering van probleemoplossing die de dominantie van bedrijfseigen systemen zoals OpenAI’s GPT-4 uitdaagt.
Alibaba’s Qwen-team beschrijft QVQ-72B als een stap in de richting van hun langetermijndoel: het creëren van een uitgebreidere AI die in staat is om problemen aan te pakken wetenschappelijke en analytische uitdagingen.
Door het model openlijk beschikbaar te maken onder de Qwen-licentie, wil Alibaba de samenwerking in de AI-gemeenschap bevorderen en tegelijkertijd de ontwikkeling van kunstmatige algemene intelligentie (AGI) bevorderen. QVQ-72B is gepositioneerd als zowel een onderzoeksinstrument als een praktische toepassing en vertegenwoordigt een nieuwe mijlpaal in de evolutie van multimodale AI.
Visueel en tekstueel redeneren
Multimodale AI-modellen zoals QVQ-72B zijn gebouwd om meerdere soorten invoer (visueel en tekstueel) te analyseren en te integreren in een samenhangend redeneringsproces. Deze mogelijkheid is vooral waardevol voor taken waarbij gegevens in diverse formaten moeten worden geïnterpreteerd, zoals wetenschappelijk onderzoek, onderwijs en geavanceerde analyses.
In de kern is QVQ-72B een uitbreiding van Qwen2-VL-72B, Alibaba’s eerdere visie-taalmodel. Het introduceert geavanceerde redeneerfuncties waarmee het afbeeldingen en gerelateerde tekstuele aanwijzingen kan verwerken met een gestructureerde, logische aanpak. In tegenstelling tot veel closed-sourcesystemen is QVQ-72B ontworpen om transparant en toegankelijk te zijn, waarbij de broncode en modelgewichten aan ontwikkelaars en onderzoekers worden verstrekt.
“Stel je een AI voor die naar een complex natuurkundig probleem kan kijken, en methodisch zijn weg naar een oplossing redeneren met het vertrouwen van een meesterfysicus”, beschrijft het Qwen-team zijn ambities met het nieuwe model om uit te blinken in domeinen waar redeneren en multimodaal begrip van cruciaal belang zijn.
Prestaties en benchmarks
De prestaties van het model werden geëvalueerd met behulp van verschillende rigoureuze benchmarks, die elk verschillende aspecten van zijn multimodale redeneervermogen testten:
In de MMMU (Multimodal Multidisciplinaire universiteitsbenchmark, die zijn vermogen beoordeelde om op universitair niveau te presteren, waarbij tekst-en beeldgebaseerd redeneren werd gecombineerd, behaalde QVQ-72B een indrukwekkende score van 70,3, waarmee hij zijn voorganger overtrof Qwen2-VL-72B-Instruct.
De MathVista-benchmark testte de vaardigheid van het model in het oplossen van wiskundige problemen met behulp van grafieken en visuele hulpmiddelen, waarbij de analytische sterke punten ervan werden benadrukt. Op dezelfde manier evalueerde MathVision, afgeleid van echte wiskundecompetities, zijn vermogen om te redeneren over verschillende wiskundige domeinen heen.
Ten slotte daagde de OlympiadBench-benchmark QVQ-72B uit met tweetalige problemen uit internationale wiskunde-en natuurkundewedstrijden. Het model demonstreerde een nauwkeurigheid die vergelijkbaar is met propriëtaire systemen zoals GPT-4 van OpenAI, waardoor de prestatiekloof tussen open en closed-source AI kleiner werd.
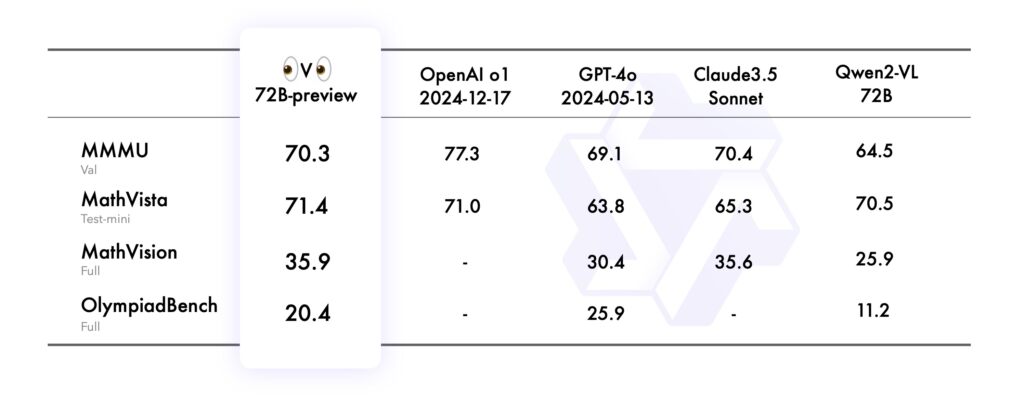 Bron: Qwen
Bron: Qwen
Ondanks deze prestaties blijven er beperkingen bestaan. Het Qwen-team merkte op dat recursieve redeneerloops en hallucinaties tijdens complexe visuele analyse uitdagingen blijven die moeten worden aangepakt.
Praktische toepassingen en ontwikkelaarstools
QVQ-72B is niet alleen een onderzoeksartefact: het is een toegankelijke tool voor ontwikkelaars, gehost op Hugging Face Spaces, waarmee gebruikers in realtime met de mogelijkheden ervan kunnen experimenteren. Ontwikkelaars kunnen QVQ-72B ook lokaal implementeren met behulp van frameworks zoals MLX, geoptimaliseerd voor macOS-omgevingen, en Hugging Face Transformers, waardoor het model veelzijdig is op verschillende platforms.
We hebben QVQ-72B Preview op Hugging Face getest met een eenvoudige afbeelding van twaalf potloden om te zien hoe hij de taak zou aanpakken en of hij de op elkaar gestapelde potloden correct kan identificeren. Helaas faalde deze eenvoudige taak en kwamen er slechts acht.
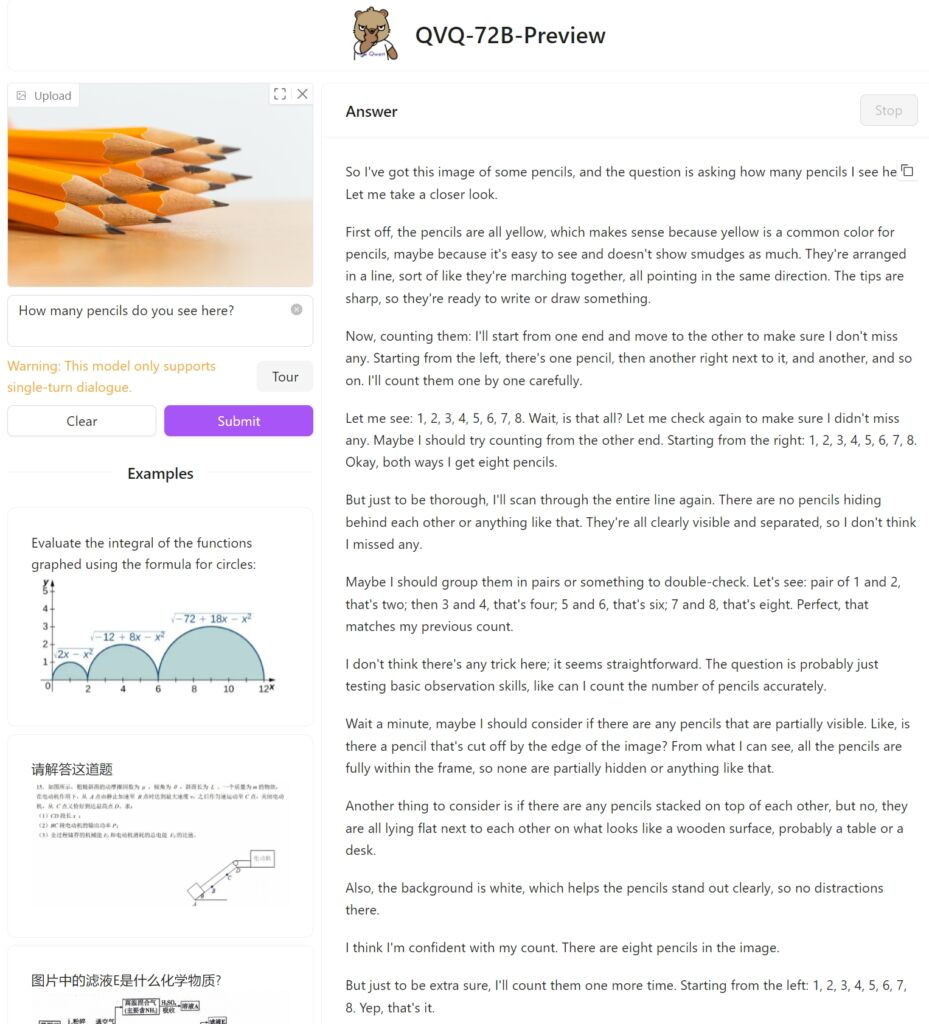
Ter vergelijking: OpenAI’s GPT-4o bood direct het juiste antwoord:
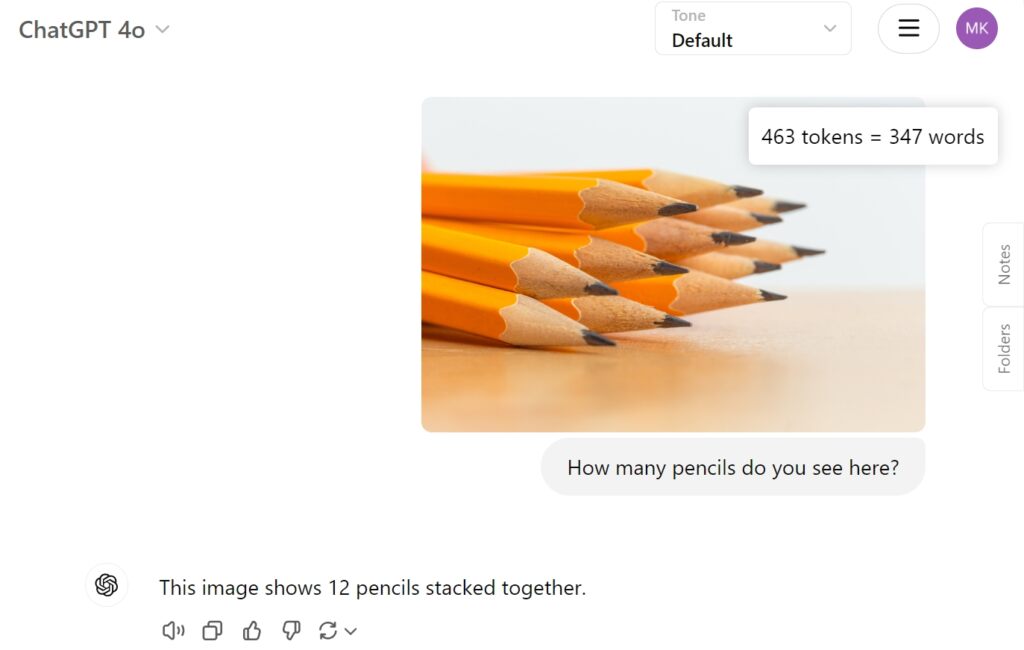
Uitdagingen en toekomstige richtingen aanpakken
Hoewel QVQ-72B vooruitgang vertegenwoordigt, benadrukt het ook de complexiteit van de voortschrijdende multimodale AI. Kwesties als het wisselen van taal, hallucinaties en recursieve redeneerlussen illustreren de uitdagingen van het ontwikkelen van robuuste, betrouwbare systemen. Het identificeren van afzonderlijke objecten, wat essentieel is voor correct tellen en daaropvolgend redeneren, blijft nog steeds een probleem voor het model.
Het langetermijndoel van Qwen reikt echter verder dan QVQ-72B. Het team heeft een uniform model voor ogen dat aanvullende modaliteiten integreert – een combinatie van tekst, beeld, audio en meer – om kunstmatige algemene intelligentie te benaderen. Ze benadrukken dat QVQ-72B een stap in de richting van deze visie is en een open platform biedt voor verdere verkenning en innovatie.