Pasukan penyelidik Qwen di Alibaba telah memperkenalkan QVQ-72B, model AI multimodal sumber terbuka yang direka untuk menggabungkan penaakulan visual dan teks. Dengan keupayaannya untuk memproses imej dan teks langkah demi langkah, model ini menawarkan pendekatan baru untuk menyelesaikan masalah yang mencabar penguasaan sistem proprietari seperti GPT-4 OpenAI.
Pasukan Qwen Alibaba menghuraikan QVQ-72B sebagai satu langkah ke arah matlamat jangka panjang mereka untuk mencipta lebih AI komprehensif yang mampu menangani cabaran saintifik dan analitikal.
Dengan menjadikan model itu tersedia secara terbuka di bawah lesen Qwen, Alibaba berhasrat untuk memupuk kerjasama dalam komuniti AI sambil memajukan pembangunan kecerdasan am buatan (AGI). Diposisikan sebagai alat penyelidikan dan aplikasi praktikal, QVQ-72B mewakili pencapaian baharu dalam evolusi AI multimodal.
Visual dan Penaakulan Tekstual
Model AI berbilang mod seperti QVQ-72B dibina untuk menganalisis dan menyepadukan berbilang jenis input—visual dan tekstual—ke dalam proses penaakulan yang padu. Keupayaan ini amat berharga untuk tugasan yang memerlukan pentafsiran data dalam pelbagai format, seperti penyelidikan saintifik, pendidikan dan analitik lanjutan.
Pada terasnya, QVQ-72B ialah lanjutan daripada Qwen2-VL-72B, model bahasa penglihatan Alibaba yang terdahulu. Ia memperkenalkan ciri penaakulan lanjutan yang membolehkannya memproses imej dan gesaan teks yang berkaitan dengan pendekatan logik berstruktur. Tidak seperti kebanyakan sistem sumber tertutup, QVQ-72B direka bentuk untuk telus dan mudah diakses, memberikan kod sumber dan pemberat modelnya kepada pembangun dan penyelidik.
“Bayangkan AI yang boleh melihat masalah fizik yang kompleks, dan secara berkaedah memikirkan caranya kepada penyelesaian dengan keyakinan ahli fizik yang mahir,”pasukan Qwen menerangkan cita-citanya dengan model baharu untuk cemerlang dalam domain di mana penaakulan dan pemahaman multimodal kritikal.
Prestasi dan Penanda Aras
Prestasi model telah dinilai menggunakan beberapa penanda aras yang ketat, setiap satu menguji aspek yang berbeza dari keupayaan penaakulan multimodalnya:
Dalam penanda aras MMMU (Multimodal Multidisciplinary University), yang menilai keupayaannya untuk berprestasi di peringkat universiti, menggabungkan teks dan penaakulan berasaskan imej, QVQ-72B mencapai markah yang mengagumkan iaitu 70.3, mengatasi pendahulunya Qwen2-VL-72B-Instruct.
Tanda aras MathVista menguji kecekapan model dalam menyelesaikan masalah matematik menggunakan graf dan alat visual, menyerlahkan kekuatan analisisnya. Begitu juga, MathVision, yang diperoleh daripada pertandingan matematik dunia sebenar, menilai keupayaannya untuk membuat penaakulan merentas domain matematik yang pelbagai.
Akhir sekali, penanda aras OlympiadBench mencabar QVQ-72B dengan masalah dwibahasa daripada pertandingan matematik dan fizik antarabangsa. Model ini menunjukkan ketepatan yang setanding dengan sistem proprietari seperti GPT-4 OpenAI, mengecilkan jurang prestasi antara AI sumber terbuka dan tertutup.
 Sumber: Qwen
Sumber: Qwen
Walaupun pencapaian ini, pengehadan kekal. Pasukan Qwen menyatakan bahawa gelung penaakulan rekursif dan halusinasi semasa analisis visual kompleks kekal sebagai cabaran yang perlu ditangani.
Aplikasi Praktikal dan Alat Pembangun
QVQ-72B bukan sekadar artifak penyelidikan—ia adalah alat yang boleh diakses untuk pembangun, dihoskan pada Memeluk Ruang Wajah, membolehkan pengguna mencuba keupayaannya dalam masa nyata. Pembangun juga boleh menggunakan QVQ-72B secara tempatan menggunakan rangka kerja seperti MLX, dioptimumkan untuk persekitaran macOS dan Hugging Face Transformers, menjadikan model serba boleh merentas platform.
Kami telah menguji Pratonton QVQ-72B pada Memeluk Wajah dengan imej ringkas daripada dua belas pensel untuk melihat bagaimana ia akan mendekati tugasan dan jika ia dapat mengenal pasti pensel yang disusun bersama dengan betul. Malangnya tugas mudah ini gagal, menghasilkan hanya lapan.
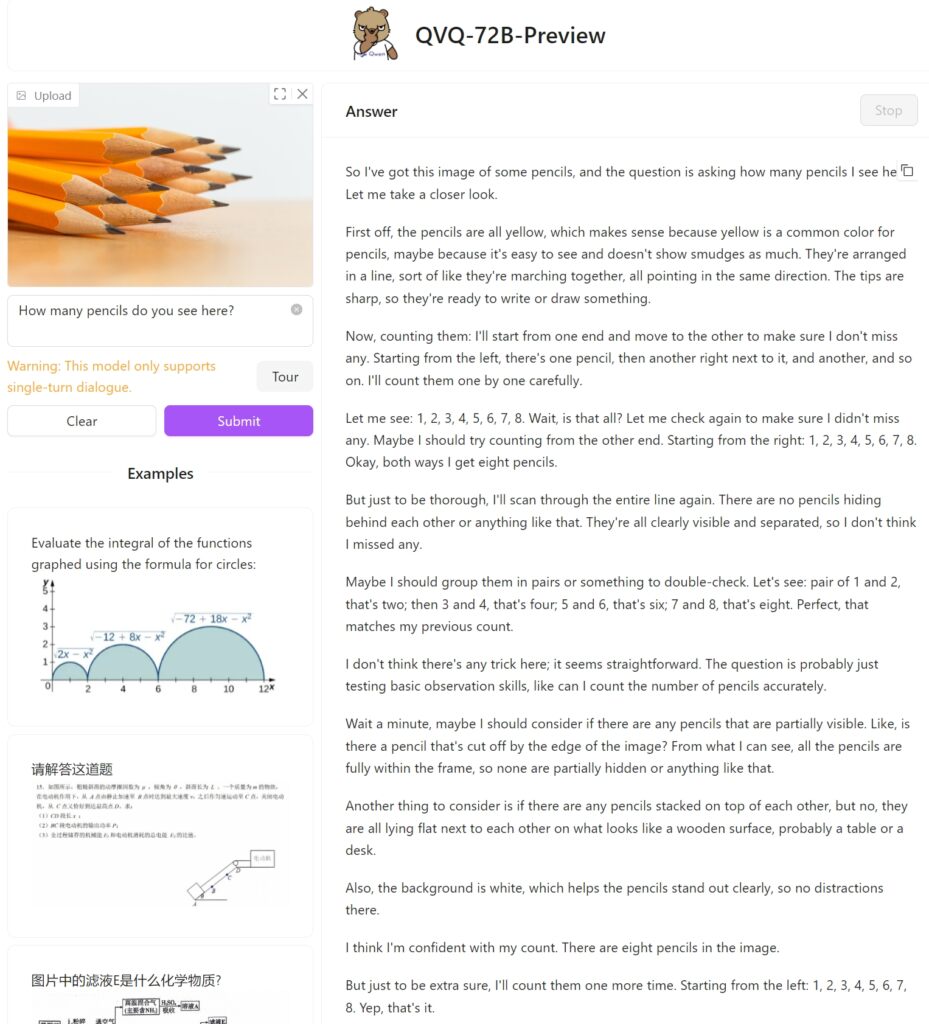
Sebagai perbandingan, GPT-4o OpenAI disediakan jawapan yang betul secara langsung:
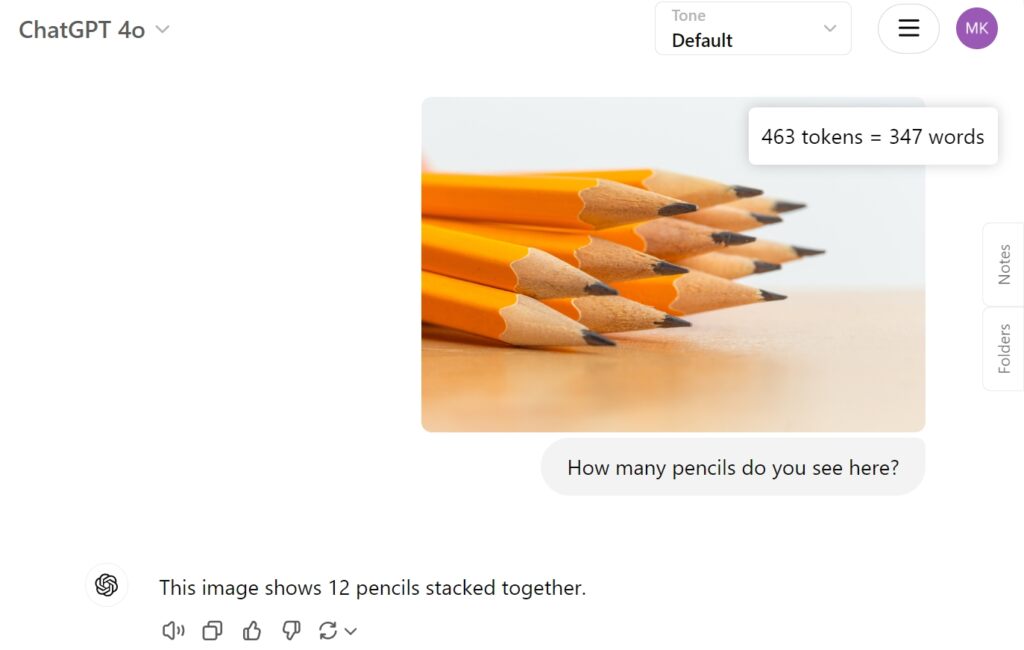
Mengatasi Cabaran dan Hala Tuju Masa Depan
Walaupun QVQ-72B mewakili kemajuan, ia juga menyerlahkan kerumitan memajukan AI multimodal. Isu seperti penukaran bahasa, halusinasi dan gelung penaakulan rekursif menggambarkan cabaran untuk membangunkan sistem yang teguh dan boleh dipercayai. Mengenal pasti objek berasingan yang merupakan kunci untuk pengiraan yang betul dan penaakulan seterusnya masih menjadi isu untuk model.
Walau bagaimanapun, matlamat jangka panjang Qwen melangkaui QVQ-72B. Pasukan ini membayangkan model bersatu yang menyepadukan modaliti tambahan—menggabungkan teks, penglihatan, audio dan seterusnya—untuk mendekati kecerdasan am buatan. Mereka menekankan bahawa QVQ-72B adalah satu langkah ke arah visi ini, menyediakan platform terbuka untuk penerokaan dan inovasi selanjutnya.