Penyelidik di Sakana AI, sebuah syarikat permulaan AI yang berpangkalan di Tokyo, telah memperkenalkan sistem pengoptimuman memori baharu yang meningkatkan kecekapan model berasaskan Transformer, termasuk model bahasa besar (LLM).
Kaedah, dipanggil Neural Attention Memory Models (NAMMs) tersedia melalui kod latihan penuh pada GitHub, mengurangkan penggunaan memori sehingga 75% sambil meningkatkan prestasi keseluruhan. Dengan memfokuskan pada token penting dan mengalih keluar maklumat berlebihan, NAMM menangani salah satu cabaran paling intensif sumber dalam AI moden: mengurus tetingkap konteks panjang.
Model Transformer, tulang belakang LLM, bergantung pada”tetingkap konteks”untuk memproses data input, tingkap konteks ini menyimpan”pasangan nilai kunci”(cache KV) untuk setiap token dalam jujukan input.
Apabila panjang tetingkap bertambah—kini mencecah ratusan ribu token— kos pengiraan meroket. Penyelesaian terdahulu cuba mengurangkan kos ini melalui pemangkasan token manual atau strategi heuristik tetapi sering merendahkan prestasi. NAMM, bagaimanapun, menggunakan rangkaian saraf yang dilatih melalui pengoptimuman evolusi untuk mengautomasikan dan memperhalusi proses pengurusan memori.
Pengoptimuman Memori dengan NAMM
NAMM menganalisis nilai perhatian dihasilkan oleh Transformers untuk menentukan kepentingan token. Mereka memproses nilai ini menjadi spektrogram—perwakilan berasaskan frekuensi yang biasa digunakan dalam pemprosesan audio dan isyarat—untuk memampatkan dan mengekstrak ciri utama corak perhatian.
Maklumat ini kemudiannya dihantar melalui rangkaian saraf ringan yang memberikan skor kepada setiap token, memutuskan sama ada ia harus dikekalkan atau dibuang.
Sakana AI menyerlahkan cara algoritma evolusi memacu NAMM’kejayaan. Tidak seperti kaedah berasaskan kecerunan tradisional, yang tidak serasi dengan keputusan binari seperti”ingat”atau”lupa”, pengoptimuman evolusi secara berulang menguji dan memperhalusi strategi ingatan untuk memaksimumkan prestasi hiliran.
“Evolusi secara semula jadi mengatasi ketidakbolehbezaan operasi pengurusan ingatan kami, yang melibatkan hasil binari’ingat’atau’lupa’,”jelas para penyelidik.
Hasil Terbukti Merentasi Penanda Aras
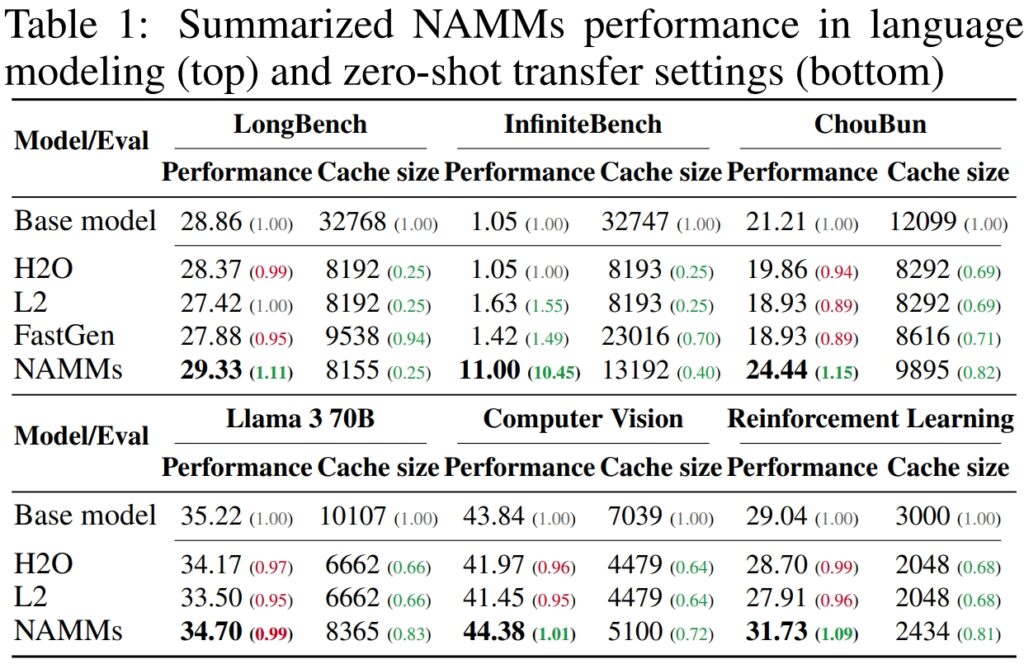
Untuk mengesahkan prestasi dan kecekapan Model Memori Perhatian Neural (NAMM), Sakana AI menjalankan ujian yang meluas ke atas berbilang penanda aras terkemuka industri yang direka untuk menilai jangka-panjang. pemprosesan konteks dan keupayaan berbilang tugasan Hasilnya menggariskan keupayaan NAMM untuk meningkatkan prestasi dengan ketara sambil mengurangkan keperluan memori, membuktikan keberkesanannya merentasi pelbagai rangka kerja penilaian.
Pada LongBench, penanda aras yang dibuat khusus untuk mengukur prestasi model pada tugas konteks panjang, NAMM mencapai 11% peningkatan dalam ketepatan berbanding model garis dasar konteks penuh. Peningkatan ini dicapai sambil mengurangkan penggunaan memori sebanyak 75%, menyerlahkan kecekapan kaedah dalam mengurus cache nilai-kekunci (KV).
Dengan memangkas token yang kurang relevan secara bijak, NAMM membenarkan model memfokus pada konteks kritikal tanpa mengorbankan hasil, menjadikannya sesuai untuk senario yang memerlukan input lanjutan, seperti analisis dokumen atau jawapan soalan berbentuk panjang.
p>
Untuk InfiniteBench, tanda aras yang menolak model ke hadnya dengan urutan yang sangat panjang—beberapa melebihi 200,000 token—NAMM menunjukkan keupayaan mereka untuk membuat skala dengan berkesan.
Walaupun model garis dasar bergelut dengan permintaan pengiraan input yang begitu panjang, NAMM mencapai peningkatan prestasi yang dramatik, meningkatkan ketepatan daripada 1.05% kepada 11.00%.
Hasil ini amat ketara kerana ia mempamerkan kapasiti NAMM untuk mengendalikan konteks ultra panjang, keupayaan yang semakin penting untuk aplikasi seperti memproses kesusasteraan saintifik, dokumen undang-undang atau repositori kod yang besar dengan saiz input token yang besar.
Pada penanda aras ChouBun Sakana AI sendiri, yang menilai penaakulan konteks panjang untuk tugasan bahasa Jepun, NAMM menyampaikan peningkatan 15% berbanding garis dasar. ChouBun menangani jurang dalam penanda aras sedia ada, yang cenderung menumpukan pada bahasa Inggeris dan Cina, dengan menguji model pada input teks Jepun lanjutan.
Kejayaan NAMM di ChouBun menyerlahkan kepelbagaian mereka merentas bahasa dan membuktikan kemantapan mereka dalam mengendalikan input bukan bahasa Inggeris—ciri utama untuk aplikasi AI global. NAMM dapat mengekalkan kandungan khusus konteks dengan cekap sambil membuang redundansi tatabahasa dan token yang kurang bermakna, membolehkan model melaksanakan tugas dengan lebih berkesan seperti ringkasan dan pemahaman bentuk panjang dalam bahasa Jepun.
 Sumber: Sakana AI
Sumber: Sakana AI
The keputusan secara kolektif menunjukkan bahawa NAMM cemerlang dalam mengoptimumkan penggunaan memori tanpa menjejaskan ketepatan. Sama ada dinilai pada tugas yang memerlukan urutan yang sangat panjang atau merentasi konteks bukan bahasa Inggeris, NAMM secara konsisten mengatasi model garis dasar, mencapai kedua-dua kecekapan pengiraan dan hasil yang lebih baik.
Gabungan penjimatan memori dan ketepatan ini meletakkan NAMM sebagai kemajuan yang hebat untuk sistem AI perusahaan yang ditugaskan untuk mengendalikan input yang luas dan kompleks.
Hasilnya amat ketara berbanding kaedah terdahulu seperti H₂O dan L2, yang mengorbankan prestasi untuk kecekapan. NAMM, sebaliknya, mencapai kedua-duanya.
“Hasil kami menunjukkan bahawa NAMM berjaya memberikan peningkatan yang konsisten merentas kedua-dua paksi prestasi dan kecekapan berbanding dengan Transformers garis dasar,”kata penyelidik.
Aplikasi Merentas Mod: Melangkaui Bahasa
Salah satu penemuan yang paling mengagumkan ialah keupayaan NAMM untuk memindahkan pukulan sifar kepada tugas dan modaliti input lain.
Salah satu aspek yang paling luar biasa bagi Model Memori Perhatian Neural (NAMM) ialah keupayaannya untuk memindahkan dengan lancar merentas tugasan dan modaliti input yang berbeza—melangkaui aplikasi berasaskan bahasa tradisional
Tidak seperti yang lain kaedah pengoptimuman ingatan, yang selalunya memerlukan latihan semula atau penalaan halus untuk setiap domain, NAMM mengekalkan kecekapan dan faedah prestasi mereka tanpa pelarasan tambahan daripada eksperimen AI Sakana mempamerkan perkara ini serba boleh dalam dua domain utama: penglihatan komputer dan pembelajaran pengukuhan, kedua-duanya memberikan cabaran unik untuk model berasaskan Transformer.
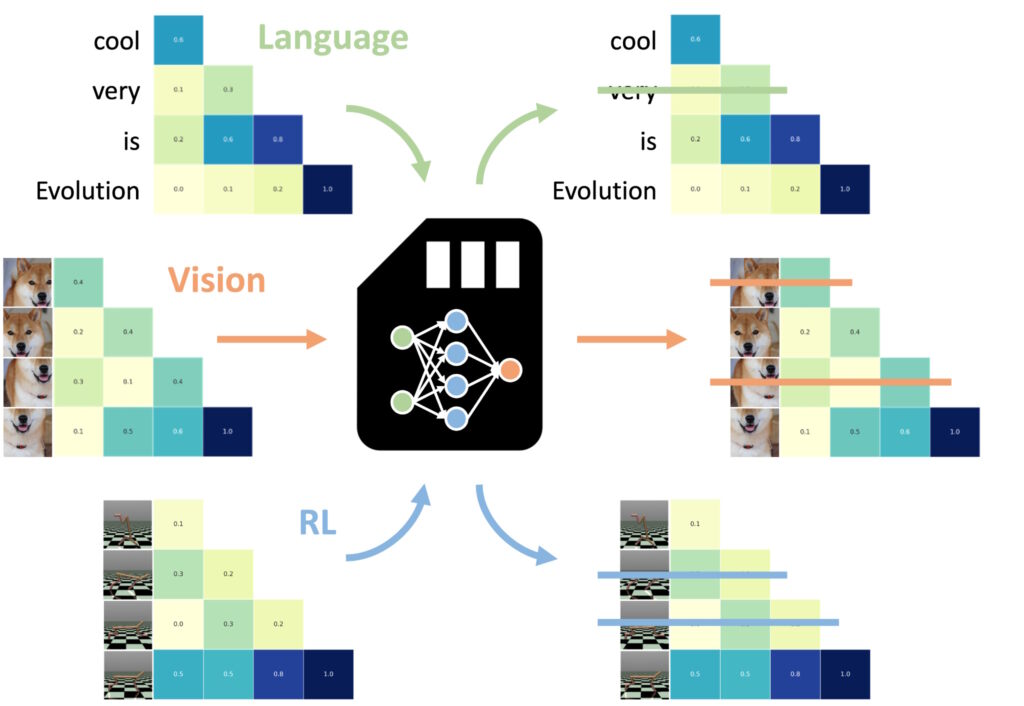 NAMM dilatih pada bahasa boleh sifar pukulan dipindahkan ke transformer lain merentas modaliti input dan domain tugas. (Imej: Sakana AI)
NAMM dilatih pada bahasa boleh sifar pukulan dipindahkan ke transformer lain merentas modaliti input dan domain tugas. (Imej: Sakana AI)
Dalam penglihatan komputer, NAMM telah dinilai menggunakan model Video Seterusnya Llava, a Transformer direka untuk memproses urutan video yang panjang. Video sememangnya mengandungi sejumlah besar data berlebihan, seperti bingkai berulang atau variasi kecil yang memberikan sedikit maklumat tambahan.
NAMM secara automatik mengenal pasti dan membuang bingkai berlebihan ini semasa inferens, memampatkan tetingkap konteks dengan berkesan tanpa menjejaskan keupayaan model untuk mentafsir kandungan video.
Sebagai contoh, NAMM mengekalkan bingkai dengan butiran visual utama—seperti perubahan tindakan, interaksi objek atau peristiwa kritikal—sambil mengalih keluar bingkai berulang atau statik. Ini menghasilkan kecekapan pemprosesan yang lebih baik, membolehkan model memfokuskan pada elemen visual yang paling relevan, sekali gus mengekalkan ketepatan sambil mengurangkan kos pengiraan.
Dalam pembelajaran pengukuhan, NAMM telah digunakan pada Pengubah Keputusan, model yang direka untuk memproses urutan tindakan, pemerhatian, dan ganjaran untuk mengoptimumkan tugas membuat keputusan. Tugasan pembelajaran pengukuhan selalunya melibatkan urutan input yang panjang dengan tahap perkaitan yang berbeza-beza, di mana tindakan suboptimum atau berlebihan boleh menghalang prestasi.
NAMM menangani cabaran ini dengan secara terpilih mengalih keluar token yang sepadan dengan tindakan tidak cekap dan maklumat bernilai rendah sambil mengekalkan yang penting untuk mencapai hasil yang lebih baik.
Sebagai contoh, dalam tugas seperti Hopper dan Walker2d—yang melibatkan mengawal ejen maya dalam gerakan berterusan—NAMM meningkatkan prestasi sebanyak lebih 9%. Dengan menapis pergerakan suboptimum atau butiran yang tidak diperlukan, Decision Transformer mencapai pembelajaran yang lebih cekap dan berkesan, memfokuskan kuasa pengiraannya pada keputusan yang memaksimumkan kejayaan dalam tugasan.
Hasil ini menyerlahkan kebolehsuaian NAMM merentas domain yang jauh berbeza. Sama ada memproses bingkai video dalam model penglihatan atau mengoptimumkan urutan tindakan dalam pembelajaran pengukuhan, NAMM menunjukkan keupayaan mereka untuk meningkatkan prestasi, mengurangkan penggunaan sumber dan mengekalkan ketepatan model—semuanya tanpa latihan semula.
NAMM belajar melupakan hampir secara eksklusif bahagian daripada bingkai video yang berlebihan, bukannya token bahasa yang menerangkan gesaan terakhir, nota kertas, yang menyerlahkan kebolehsuaian NAMM.
Dasar Teknikal NAMM
Kecekapan dan keberkesanan Model Memori Perhatian Neural (NAMM) terletak pada proses pelaksanaan yang diperkemas dan sistematik, yang membolehkan pemangkasan token yang tepat tanpa campur tangan manual. Proses ini dibina pada tiga komponen teras: spektrogram perhatian, pemampatan ciri dan pemarkahan automatik.
NAMM melaraskan gelagat mereka secara dinamik bergantung pada keperluan tugas dan kedalaman lapisan Transformer. Lapisan awal mengutamakan konteks”global”seperti perihalan tugas, manakala lapisan yang lebih dalam mengekalkan butiran khusus tugas”tempatan”. Dalam tugas pengekodan, contohnya, NAMM membuang komen dan kod plat dandang; dalam tugas bahasa semula jadi, mereka menghapuskan redundansi tatabahasa sambil mengekalkan kandungan utama.
Pengekalan token adaptif ini memastikan model kekal fokus pada maklumat yang berkaitan sepanjang pemprosesan, meningkatkan kelajuan dan ketepatan.
Yang pertama langkah melibatkan penjanaan Spektrogram Perhatian. Transformer mengira”nilai perhatian”pada setiap lapisan untuk menentukan kepentingan relatif setiap token dalam tetingkap konteks. NAMM mengubah nilai perhatian ini menjadi perwakilan berasaskan kekerapan menggunakan Short-Time Fourier Transform (STFT).
STFT ialah teknik pemprosesan isyarat yang digunakan secara meluas yang memecahkan jujukan kepada komponen frekuensi setempat dari semasa ke semasa, memberikan gambaran kepentingan token yang padat tetapi terperinci menukar jujukan perhatian mentah kepada data seperti spektrogram, membolehkan analisis yang lebih jelas tentang token yang menyumbang secara bermakna kepada output model.
Seterusnya, Ciri Mampatandigunakan untuk mengurangkan dimensi data spektrogram sambil mengekalkan ciri pentingnya. Ini dicapai menggunakan purata bergerak eksponen (EMA), kaedah matematik yang memampatkan corak perhatian sejarah menjadi ringkasan bersaiz tetap. EMA memastikan bahawa perwakilan kekal ringan dan terurus, membolehkan NAMM menganalisis jujukan perhatian yang panjang dengan cekap sambil meminimumkan overhed pengiraan.
Langkah terakhir ialah Pemarkahan dan Pemangkasan, di mana NAMM menggunakan ringan. pengelas rangkaian saraf untuk menilai perwakilan token termampat dan memberikan markah berdasarkan kepentingannya. Token dengan markah di bawah ambang yang ditetapkan dipangkas daripada tetingkap konteks, dengan berkesan”melupakan”butiran yang tidak membantu atau berlebihan. Mekanisme pemarkahan ini membolehkan NAMM mengutamakan token kritikal yang menyumbang kepada proses membuat keputusan model sambil membuang data yang kurang berkaitan.
Apa yang menjadikan NAMM sangat berkesan ialah pergantungan mereka pada pengoptimuman evolusi untuk memperhalusi proses ini kaedah seperti perjuangan keturunan kecerunan dengan tugas yang tidak boleh dibezakan—seperti memutuskan sama ada token harus dikekalkan atau dibuang
Sebaliknya, NAMM menggunakan algoritma evolusi berulang, yang diilhamkan oleh pemilihan semula jadi, untuk”mutasi”dan “. pilih”strategi pengurusan memori yang paling cekap dari semasa ke semasa. Melalui percubaan berulang, sistem berkembang untuk mengutamakan token penting secara automatik, mencapai keseimbangan antara prestasi dan kecekapan ingatan tanpa memerlukan penalaan halus manual.
Pelaksanaan diperkemas ini—menggabungkan analisis token berasaskan spektrogram, pemampatan cekap dan pemangkasan automatik—membolehkan NAMM menyampaikan kedua-dua penjimatan memori yang ketara dan peningkatan prestasi merentas pelbagai berasaskan Transformer tugasan. Dengan mengurangkan keperluan pengiraan sambil mengekalkan atau meningkatkan ketepatan, NAMM menetapkan penanda aras baharu untuk pengurusan memori yang cekap dalam model AI moden.
Apa Yang Akan Datang Seterusnya untuk Transformers?
Sakana AI percaya NAMM hanyalah permulaan. Walaupun kerja semasa memfokuskan pada mengoptimumkan model pra-latihan secara inferens, penyelidikan masa depan mungkin menyepadukan NAMM ke dalam proses latihan itu sendiri. Ini boleh membolehkan model mempelajari strategi pengurusan memori secara asli, memanjangkan lagi panjang tetingkap konteks dan meningkatkan kecekapan merentas domain.
“Kerja ini hanya mula meneroka ruang reka bentuk model memori kami, yang kami jangkakan mungkin menawarkan banyak peluang baharu untuk memajukan generasi pengubah masa hadapan,”kata pasukan itu menyimpulkan.
Keupayaan terbukti NAMM untuk meningkatkan prestasi, mengurangkan kos dan menyesuaikan diri merentas modaliti menetapkan piawaian baharu untuk kecekapan model AI berskala besar.