DeepSeek AI telah mengeluarkan DeepSeek-VL2, keluarga Model Vision-Language (VLM) yang kini tersedia di bawah lesen sumber terbuka. Siri ini memperkenalkan tiga varian—Tiny, Small dan VL2 standard—yang menampilkan saiz parameter diaktifkan masing-masing 1.0 bilion, 2.8 bilion dan 4.5 bilion.
Model boleh diakses melalui GitHub dan Memeluk Muka. Mereka berjanji untuk memajukan aplikasi AI utama, termasuk menjawab soalan visual (VQA), pengecaman aksara optik (OCR), dan analisis dokumen dan carta resolusi tinggi.
Menurut dokumentasi GitHub rasmi, “DeepSeek-VL2 menunjukkan keupayaan unggul merentas pelbagai tugas, termasuk tetapi tidak terhad kepada jawapan soalan visual, pemahaman dokumen/jadual/carta dan asas visual.”
Masa keluaran ini meletakkan DeepSeek AI dalam persaingan langsung dengan pemain utama seperti OpenAI dan Google, yang kedua-duanya mendominasi domain AI bahasa penglihatan dengan proprietari model seperti GPT-4V dan Gemini-Exp
Penekanan DeepSeek pada kerjasama sumber terbuka, digabungkan dengan ciri teknikal lanjutan keluarga VL2, meletakkannya sebagai pilihan percuma untuk penyelidik.
Jubin Dinamik: Memajukan Pemprosesan Imej Resolusi Tinggi
Salah satu kemajuan yang paling ketara dalam DeepSeek-VL2 ialah strategi pengekodan penglihatan jubin dinamiknya, yang merevolusikan cara model memproses data visual resolusi tinggi.
Tidak seperti pendekatan resolusi tetap tradisional, jubin dinamik membahagikan imej kepada jubin yang lebih kecil dan fleksibel yang menyesuaikan diri dengan pelbagai nisbah aspek. Kaedah ini memastikan pengekstrakan ciri terperinci sambil mengekalkan kecekapan pengiraan.
Pada repositori GitHubnya, DeepSeek menerangkan ini sebagai cara untuk”memproses imej resolusi tinggi dengan cekap dengan nisbah aspek yang berbeza-beza, mengelakkan penskalaan pengiraan yang biasanya dikaitkan dengan peleraian imej yang semakin meningkat.”
Keupayaan ini membolehkan DeepSeek-VL2 cemerlang dalam aplikasi seperti pembumian visual, di mana ketepatan tinggi adalah penting untuk mengenal pasti objek dalam imej yang kompleks dan OCR yang padat tugasan, yang memerlukan pemprosesan teks dalam dokumen atau carta terperinci
Dengan melaraskan secara dinamik kepada resolusi imej dan nisbah aspek yang berbeza, model tersebut mengatasi batasan kaedah pengekodan statik, menjadikannya sesuai untuk kes penggunaan yang menuntut kedua-dua kefleksibelan. dan ketepatan.
Campuran Pakar dan Perhatian Terpendam Berbilang Kepala untuk Kecekapan
Pencapaian prestasi DeepSeek-VL2 disokong lagi dengan penyepaduan rangka kerja Campuran Pakar (MoE) dan mekanisme Perhatian Terpendam Berbilang Kepala (MLA)
Seni bina MoE secara terpilih mengaktifkan subset tertentu , atau”pakar,”dalam model untuk mengendalikan tugas dengan lebih cekap. Reka bentuk ini mengurangkan overhed pengiraan dengan melibatkan hanya parameter yang diperlukan untuk setiap operasi, ciri yang amat berguna dalam persekitaran yang dikekang sumber.
Mekanisme MLA melengkapkan rangka kerja MoE dengan memampatkan cache Nilai-Kekunci menjadi terpendam vektor semasa inferens. Pengoptimuman ini meminimumkan penggunaan memori dan meningkatkan kelajuan pemprosesan tanpa mengorbankan ketepatan model.
Menurut dokumentasi teknikal, “Seni bina MoE, digabungkan dengan MLA, membolehkan DeepSeek-VL2 mencapai prestasi kompetitif atau lebih baik daripada model padat dengan parameter diaktifkan yang lebih sedikit.”
Saluran Paip Latihan Tiga Peringkat
Pembangunan DeepSeek-VL2 melibatkan saluran paip latihan tiga peringkat yang ketat yang direka untuk mengoptimumkan keupayaan multimodal model Peringkat pertama memfokuskan pada penjajaran bahasa penglihatan, di mana model dilatih untuk menyepadukan ciri visual dengan maklumat teks
Ini dicapai menggunakan set data seperti ShareGPT4V, yang menyediakan contoh teks imej berpasangan. penjajaran awal Peringkat kedua melibatkan pralatihan bahasa penglihatan, yang menggabungkan pelbagai set data, termasuk WIT, WikiHow, dan data OCR berbilang bahasa, untuk meningkatkan kebolehan generalisasi model merentas berbilang domain
Akhir sekali, peringkat ketiga terdiri daripada penyeliaan halus (SFT), di mana set data khusus tugasan digunakan untuk memperhalusi prestasi model dalam. bidang seperti pembumian visual, pemahaman antara muka pengguna grafik (GUI) dan kapsyen padat.
Peringkat latihan ini membolehkan DeepSeek-VL2 membina kapsyen yang kukuh asas untuk pemahaman multimodal sambil membolehkan model menyesuaikan diri dengan tugas khusus. Penggabungan set data berbilang bahasa meningkatkan lagi kebolehgunaan model dalam tetapan penyelidikan dan industri global.
Berkaitan: Model Pratonton R1-Lite DeepSeek Cina Mensasarkan Peneraju OpenAI dalam Penaakulan Automatik
p>
Hasil Penandaarasan
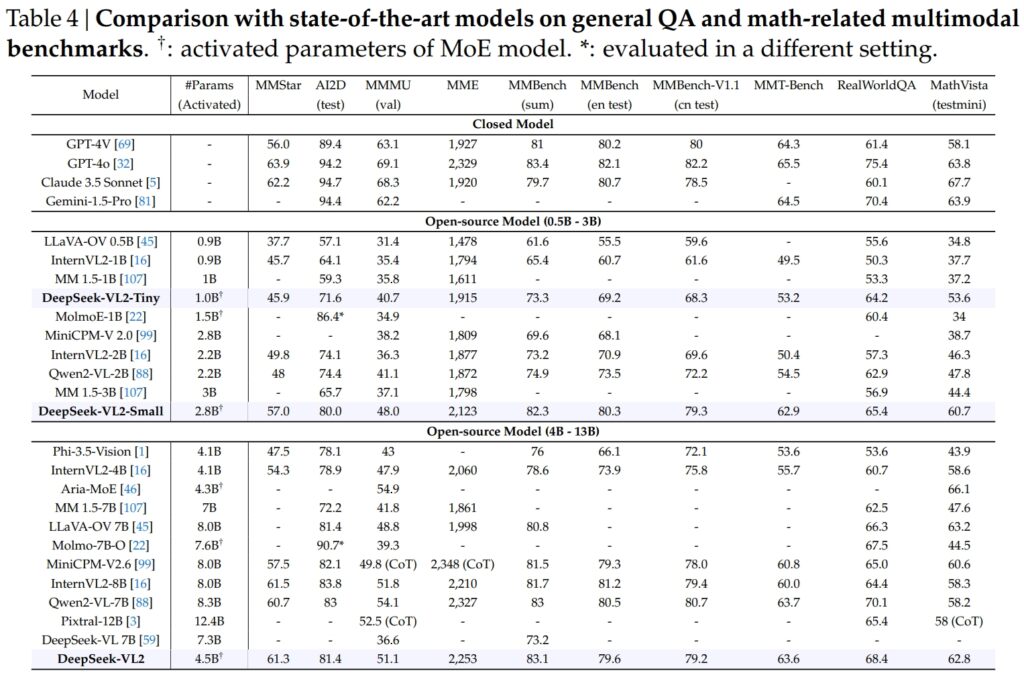
Model DeepSeek-VL2, termasuk varian Tiny, Small dan standard, cemerlang dalam penanda aras kritikal untuk menjawab soalan umum (QA) dan tugasan multimodal berkaitan matematik.
DeepSeek-VL2-Small, dengan 2.8 bilion parameter diaktifkan, mencapai skor MMStar 57.0 dan mengatasi model bersaiz serupa seperti InternVL2-2B (49.8) dan Qwen2-VL-2B (48.0). Ia juga menyaingi rapat model yang lebih besar, seperti 4.1B InternVL2-4B (54.3) dan 8.3B Qwen2-VL-7B (60.7), yang menunjukkan kecekapan daya saingnya.
Pada ujian AI2D untuk visual alasan, DeepSeek-VL2-Small mencapai skor 80.0, mengatasi InternVL2-2B (74.1) dan MM 1.5-3B (tidak dilaporkan). Walaupun menentang pesaing berskala lebih besar seperti InternVL2-4B (78.9) dan MiniCPM-V2.6 (82.1), DeepSeek-VL2 menunjukkan hasil yang kukuh dengan lebih sedikit parameter diaktifkan.
 Sumber: DeepSeek
Sumber: DeepSeek
Keutamaan Model DeepSeek-VL2 (4.5 bilion parameter diaktifkan) memberikan hasil yang luar biasa, menjaringkan 61.3 pada MMStar dan 81.4 pada AI2D. Ia mengatasi pesaing seperti Molmo-7B-O (7.6B parameter diaktifkan, 39.3) dan MiniCPM-V2.6 (8.0B, 57.5), seterusnya mengesahkan keunggulan teknikalnya.
Kecemerlangan dalam OCR-Tanda Aras Berkaitan
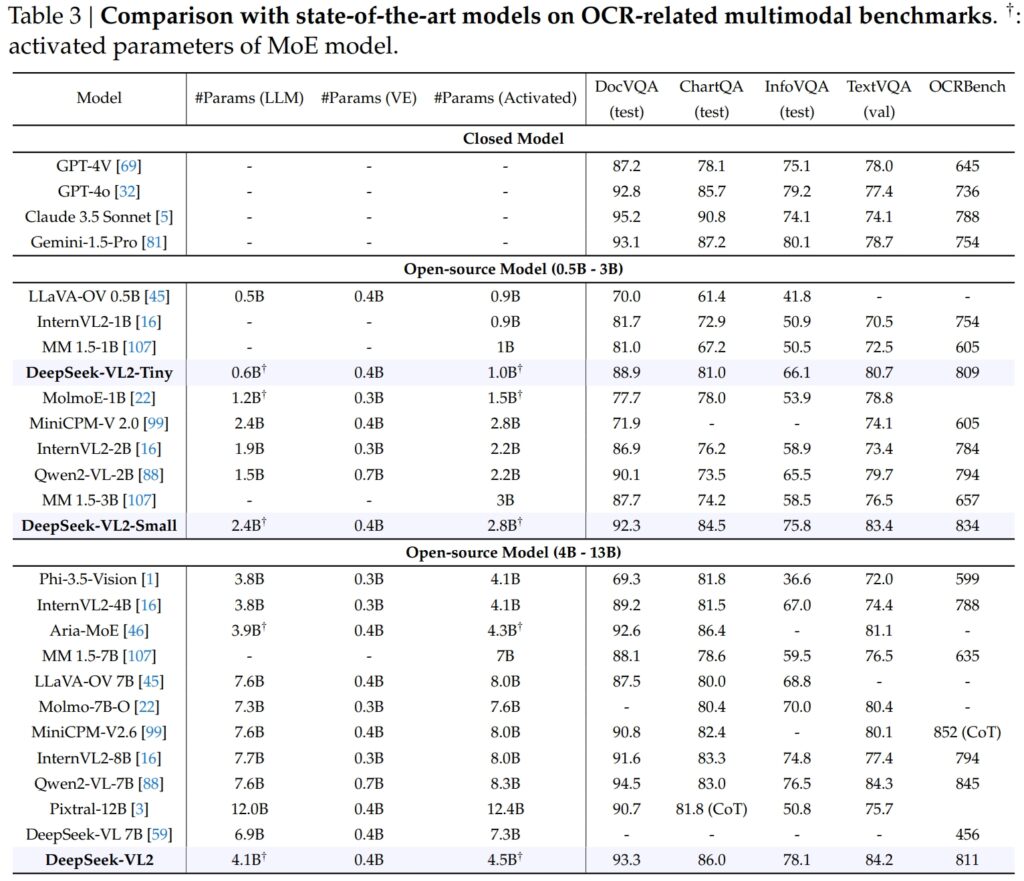
Keupayaan DeepSeek-VL2 meluas dengan ketara kepada Tugas berkaitan OCR (pengecaman aksara optik), kawasan penting untuk pemahaman dokumen dan pengekstrakan teks dalam AI. Dalam ujian DocVQA, DeepSeek-VL2-Small mencapai ketepatan 92.3% yang mengagumkan, mengatasi semua model sumber terbuka lain yang berskala serupa, termasuk InternVL2-4B (89.2%) dan MiniCPM-V2.6 (90.8%). Ketepatannya berada di belakang model tertutup seperti GPT-4o (92.8) dan Claude 3.5 Sonnet (95.2).
Model DeepSeek-VL2 juga mendahului dalam ujian ChartQA dengan skor 86.0, mengatasi prestasi InternVL2-4B (81.5) dan MiniCPM-V2.6 (82.4). Hasil ini mencerminkan keupayaan lanjutan DeepSeek-VL2 untuk memproses carta dan mengekstrak cerapan daripada data visual yang kompleks.
 Sumber: DeepSeek
Sumber: DeepSeek
Dalam OCRBench, sebuah syarikat yang sangat kompetitif metrik untuk pengecaman teks terperinci, DeepSeek-VL2 mencapai 811, mengatasi 7.6B Qwen2-VL-7B (845) dan MiniCPM-V2.6 (852 dengan CoT), dan menyerlahkan kekuatannya dalam tugas OCR yang padat.
Perbandingan Terhadap Model Penglihatan-Bahasa Terkemuka
strong>
Apabila diletakkan bersama pemimpin industri seperti GPT-4V OpenAI dan Gemini-1.5-Pro Google, Model DeepSeek-VL2 menawarkan keseimbangan prestasi dan kecekapan yang menarik. Sebagai contoh, GPT-4V mendapat markah 87.2 dalam DocVQA, yang hanya mendahului sedikit daripada DeepSeek-VL2 (93.3), walaupun yang terakhir beroperasi di bawah rangka kerja sumber terbuka dengan lebih sedikit parameter diaktifkan.
Pada TextVQA, DeepSeek-VL2-Small mencapai 83.4, dengan ketara mengatasi model sumber terbuka serupa seperti InternVL2-2B (73.4) dan MiniCPM-V2.0 (74.1). Malah MiniCPM-V2.6 (8.0B) yang jauh lebih besar hanya mencapai 80.4, seterusnya menggariskan kebolehskalaan dan kecekapan seni bina DeepSeek-VL2.
Untuk ChartQA, skor DeepSeek-VL2 sebanyak 86.0 melebihi skor Pixtral-12B (81.8) dan InternVL2-8B (83.3), menunjukkan keupayaannya untuk cemerlang dalam tugas khusus yang memerlukan pemahaman teks visual yang tepat.
Berkaitan: Mistral AI Debut Pixtral 12B untuk Pemprosesan Teks dan Imej
Meluaskan Aplikasi: Dari Grounded Perbualan kepada Penceritaan Visual
Satu ciri ketara model DeepSeek-VL2 ialah keupayaan mereka untuk menjalankan perbualan berasaskan, di mana model boleh mengenal pasti objek dalam imej dan mengintegrasikannya ke dalam perbincangan kontekstual.
Sebagai contoh, dengan menggunakan token khusus, model boleh memberikan butiran khusus objek, seperti lokasi dan penerangan, untuk menjawab pertanyaan tentang imej. Ini membuka kemungkinan untuk aplikasi dalam robotik, realiti tambahan dan pembantu digital, di mana penaakulan visual yang tepat diperlukan.
Satu lagi bidang aplikasi ialah penceritaan visual. DeepSeek-VL2 boleh menjana naratif yang koheren berdasarkan urutan imej, menggabungkan pengecaman visual lanjutan dan keupayaan bahasanya.
Ini amat berharga dalam domain seperti pendidikan, media dan hiburan, di mana penciptaan kandungan dinamik menjadi keutamaan. Model tersebut memanfaatkan pemahaman multimodal yang kuat untuk mencipta cerita yang terperinci dan sesuai kontekstual, menyepadukan elemen visual seperti tanda tempat dan teks ke dalam naratif dengan lancar.
Keupayaan model dalam asas visual adalah sama kuat. Dalam ujian yang melibatkan imej yang kompleks, DeepSeek-VL2 telah menunjukkan keupayaan untuk mengesan dan menerangkan objek dengan tepat berdasarkan gesaan deskriptif.
Sebagai contoh, apabila diminta untuk mengenal pasti”kereta yang diletakkan di sebelah kiri jalan”, model boleh menentukan objek tepat dalam imej dan menjana koordinat kotak sempadan untuk menggambarkan tindak balasnya. Ciri-ciri ini menjadikan ia sangat sesuai untuk sistem dan pengawasan autonomi, di mana analisis visual terperinci adalah kritikal.
Kebolehcapaian dan Skalabilitas Sumber Terbuka
DeepSeek AI’s keputusan untuk mengeluarkan DeepSeek-VL2 sebagai sumber terbuka sangat berbeza dengan sifat proprietari pesaing seperti GPT-4V OpenAI dan Gemini-Exp Google, yang merupakan sistem tertutup yang direka untuk akses awam terhad.
Menurut dokumentasi teknikal,”Dengan menjadikan model dan kod pra-latihan kami tersedia secara terbuka, kami berhasrat untuk mempercepatkan kemajuan dalam pemodelan bahasa penglihatan dan mempromosikan kerjasama inovasi merentas komuniti penyelidikan.”
Skalabiliti DeepSeek-VL2 meningkatkan lagi daya tarikannya. Model ini dioptimumkan untuk penggunaan merentas pelbagai konfigurasi perkakasan, daripada GPU tunggal dengan memori 10GB kepada persediaan berbilang GPU yang mampu mengendalikan beban kerja berskala besar.
Fleksibiliti ini memastikan DeepSeek-VL2 boleh digunakan oleh organisasi dari semua saiz, daripada syarikat permulaan kepada perusahaan besar, tanpa memerlukan infrastruktur khusus.
Inovasi dalam Data dan Latihan
Faktor utama di sebalik kejayaan DeepSeek-VL2 ialah data latihannya yang luas dan pelbagai. Fasa pralatihan menggabungkan set data seperti WIT, WikiHow dan OBELICS, yang menyediakan gabungan pasangan teks imej berjalin untuk generalisasi.
Data tambahan untuk tugasan tertentu, seperti OCR dan menjawab soalan visual, datang daripada sumber seperti LaTeX OCR dan PubTabNet, memastikan model boleh mengendalikan kedua-dua tugas umum dan khusus dengan ketepatan yang tinggi.
Pemasukan set data berbilang bahasa juga mencerminkan matlamat DeepSeek AI untuk kebolehgunaan global. Set data bahasa Cina seperti Wanjuan telah disepadukan bersama set data bahasa Inggeris untuk memastikan model tersebut boleh beroperasi dengan berkesan dalam persekitaran berbilang bahasa.
Pendekatan ini meningkatkan kebolehgunaan DeepSeek-VL2 di wilayah yang data bukan bahasa Inggeris mendominasi, mengembangkan potensi pangkalan penggunanya dengan ketara.
Fasa penalaan halus diselia memperhalusi model-model tersebut. keupayaan dengan memfokuskan pada tugas tertentu seperti pemahaman GUI dan analisis carta. Dengan menggabungkan set data dalaman dengan sumber sumber terbuka berkualiti tinggi, DeepSeek-VL2 mencapai prestasi terkini pada beberapa penanda aras, mengesahkan keberkesanan metodologi latihannya.
Penyusunan teliti DeepSeek AI data dan saluran paip latihan yang inovatif telah membolehkan model VL2 cemerlang dalam pelbagai tugas sambil mengekalkan kecekapan dan kebolehskalaan. Faktor-faktor ini menjadikan mereka tambahan yang berharga kepada bidang AI multimodal.
Keupayaan model untuk mengendalikan tugas pemprosesan imej yang kompleks, seperti pembumian visual dan OCR padat, menjadikannya sesuai untuk industri seperti logistik dan keselamatan. Dalam logistik, mereka boleh mengautomasikan penjejakan inventori dengan menganalisis imej stok gudang, mengenal pasti item dan menyepadukan penemuan ke dalam sistem pengurusan inventori.
Dalam domain keselamatan, DeepSeek-VL2 boleh membantu dalam pengawasan dengan mengenal pasti objek atau individu dalam masa nyata, berdasarkan pertanyaan deskriptif dan menyediakan maklumat kontekstual terperinci kepada pengendali.
DeepSeek-Keupayaan perbualan berasaskan VL2 juga menawarkan kemungkinan dalam robotik dan realiti tambahan. Sebagai contoh, robot yang dilengkapi dengan model ini boleh mentafsir persekitarannya secara visual, bertindak balas kepada pertanyaan manusia tentang objek tertentu dan melakukan tindakan berdasarkan pemahamannya tentang input visual.
Begitu juga, peranti realiti tambahan boleh memanfaatkan ciri asas visual dan penceritaan model untuk memberikan pengalaman interaktif dan mendalam, seperti lawatan berpandu atau tindanan kontekstual dalam persekitaran masa nyata.
Cabaran dan Prospek Masa Depan
Walaupun mempunyai banyak kekuatan, DeepSeek-VL2 menghadapi beberapa cabaran. Satu had utama ialah saiz tetingkap konteksnya, yang pada masa ini mengehadkan bilangan imej yang boleh diproses dalam satu interaksi.
Memperluas tetingkap konteks ini dalam lelaran masa hadapan akan membolehkan interaksi berbilang imej yang lebih kaya dan meningkatkan utiliti model dalam tugas yang memerlukan pemahaman konteks yang lebih luas.
Cabaran lain terletak pada pengendalian out-of-domain atau input visual berkualiti rendah, seperti imej kabur atau objek yang tidak terdapat dalam data latihannya. Walaupun DeepSeek-VL2 telah menunjukkan keupayaan generalisasi yang luar biasa, meningkatkan keteguhan terhadap input sedemikian akan meningkatkan lagi kebolehgunaannya merentas senario dunia sebenar.
Melihat ke hadapan, DeepSeek AI merancang untuk mengukuhkan keupayaan penaakulan modelnya, membolehkan mereka mengendalikan tugas multimodal yang semakin kompleks. Dengan menyepadukan saluran paip latihan yang dipertingkatkan dan mengembangkan set data untuk merangkumi lebih banyak senario yang pelbagai, versi masa depan DeepSeek-VL2 boleh menetapkan penanda aras baharu untuk prestasi AI bahasa penglihatan.