DeepSeek AI は、ビジョン言語モデル (VLM) のファミリーである DeepSeek-VL2 をリリースし、現在はオープンソース ライセンスで利用可能です。このシリーズには、Tiny、Small、および標準 VL2 の 3 つのバリアントが導入されており、それぞれ 10 億、28 億、45 億の有効化パラメータ サイズを備えています。
モデルは、GitHub および抱き合う顔。彼らは、ビジュアル質問応答 (VQA)、光学式文字認識 (OCR)、高解像度の文書およびチャート分析などの主要な AI アプリケーションを進歩させることを約束しています。
GitHub の公式ドキュメントによると、「DeepSeek-VL2 は、視覚的な質問への回答、文書/表/グラフの理解、視覚的な基礎付けを含むがこれらに限定されない、さまざまなタスクにわたって優れた機能を実証します。」
このリリースのタイミングにより、DeepSeek AI は OpenAI や Google などの大手企業と直接競合することになります。両社は独自の技術でビジョン言語 AI ドメインを支配しています。 GPT-4V や Gemini-Exp などのモデル
DeepSeek が重視している点オープンソースのコラボレーションは、VL2 ファミリの高度な技術機能と組み合わされて、研究者にとって無料のオプションとして位置付けられます。
ダイナミック タイル: 高度な高解像度画像処理
DeepSeek-VL2 の最も注目すべき進歩の 1 つは、モデルが高解像度のビジュアル データを処理する方法に革命をもたらす、ダイナミック タイリング ビジョン エンコーディング戦略です。
従来の固定解像度とは異なります。動的タイリングでは、画像をさまざまなアスペクト比に適応する小さな柔軟なタイルに分割します。この方法により、計算効率を維持しながら詳細な特徴抽出が保証されます。
DeepSeek は、GitHub リポジトリで、これを「さまざまなアスペクト比の高解像度画像を効率的に処理し、画像解像度の増加に通常伴う計算によるスケーリングを回避する」方法であると説明しています。
この機能により、DeepSeek-VL2 は、複雑な画像内のオブジェクトを識別するために高精度が不可欠な視覚的グラウンディングや、詳細な文書や文書内のテキストを処理する必要がある高密度 OCR タスクなどのアプリケーションで優れた性能を発揮します。
モデルは、さまざまな画像解像度とアスペクト比に動的に調整することで、静的エンコード方式の制限を克服し、柔軟性と精度の両方を必要とするユースケースに適しています。
効率性に対する専門家の混合とマルチヘッドの潜在的な注意
DeepSeek-VL2 のパフォーマンスの向上は、 Mixture-of-Experts (MoE) フレームワークとマルチヘッド潜在注意 (MLA) メカニズム
MoE アーキテクチャは、タスクをより効率的に処理するために、モデル内の特定のサブセット、つまり「エキスパート」を選択的にアクティブ化します。この設計は、各操作に必要なパラメータのみを使用することで計算オーバーヘッドを削減します。これは、リソースに制約のある環境で特に役立つ機能です。
MLA メカニズムは、Key-Value キャッシュを潜在キャッシュに圧縮することで MoE フレームワークを補完します。推論中のベクトル。この最適化により、モデルの精度を犠牲にすることなくメモリ使用量が最小限に抑えられ、処理速度が向上します。
技術文書によると、「MoE アーキテクチャを MLA と組み合わせることで、DeepSeek-VL2 は、有効化されたパラメータが少ない高密度モデルと競合するか、より優れたパフォーマンスを達成できます。」
3 段階のトレーニング パイプライン
DeepSeek-VL2 の開発には、モデルのマルチモーダル機能を最適化するように設計された厳密な 3 段階のトレーニング パイプラインが含まれていました。視覚と言語の位置合わせについては、視覚的特徴とテキスト情報を統合するようにモデルがトレーニングされました。
これは、初期位置合わせ用の画像とテキストのペアの例を提供する ShareGPT4V のようなデータセットを使用して実現されました。-言語事前トレーニング。WIT、WikiHow、多言語 OCR データなど、さまざまなデータセットを組み込んで、複数のドメインにわたるモデルの汎化能力を強化します。
最後の第 3 段階。教師あり微調整 (SFT) で構成され、タスク固有のデータセットを使用して、視覚的なグラウンディング、グラフィカル ユーザー インターフェイス (GUI) の理解、緻密なキャプションなどの領域でモデルのパフォーマンスを調整しました。
これらのトレーニング ステージDeepSeek-VL2 により、モデルが特殊なタスクに適応できるようにしながら、マルチモーダルな理解のための強固な基盤を構築することができました。多言語データセットの組み込みにより、世界的な研究や産業環境におけるモデルの適用性がさらに強化されました。
関連: 中国の DeepSeek R1-Lite-Preview モデルは、自動推論における OpenAI のリードをターゲットにしています
p>
ベンチマーク結果
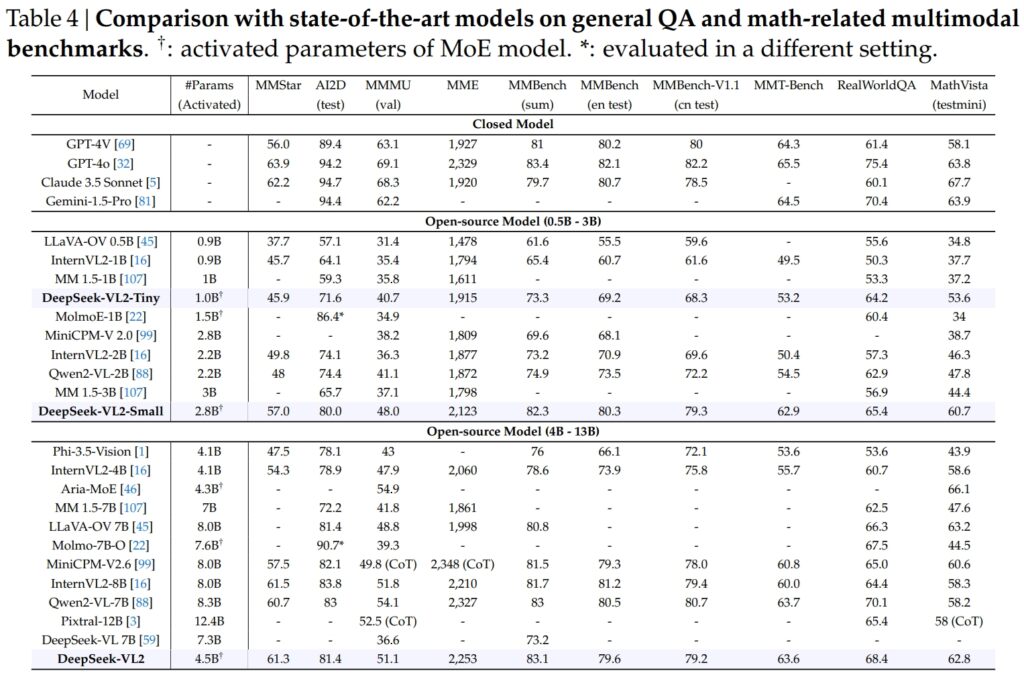
Tiny、Small、standard バリアントを含む DeepSeek-VL2 モデル、一般的な質問応答 (QA) および数学関連のマルチモーダル タスクの重要なベンチマークで優れています。
DeepSeek-VL2-Small は 28 億のアクティブ化パラメータを備え、MMStar スコア 57.0 を達成し、InternVL2-2B (49.8) や Qwen2-VL-2B (48.0) などの同様のサイズのモデルを上回りました。また、4.1B InternVL2-4B (54.3) や 8.3B Qwen2-VL-7B (60.7) などのはるかに大きなモデルともほぼ匹敵し、その競争力の効率性を実証しました。
ビジュアルの AI2D テストについてその結果、DeepSeek-VL2-Small は 80.0 のスコアを達成し、InternVL2-2B (74.1) および MM を上回りました。 1.5-3B (報告されていません)。 InternVL2-4B (78.9) や MiniCPM-V2.6 (82.1) などの大規模な競合他社に対しても、DeepSeek-VL2 は有効化されたパラメータが少ないにもかかわらず強力な結果を示しました。
 出典: DeepSeek
出典: DeepSeek
フラッグシップDeepSeek-VL2 モデル (45 億の有効化パラメータ) は、MMStar で 61.3 点、MMStar で 81.4 点という優れた結果をもたらしました。 AI2D。 Molmo-7B-O (7.6B 活性化パラメータ、39.3) や MiniCPM-V2.6 (8.0B、57.5) などの競合製品を上回り、その技術的優位性がさらに実証されました。
OCR における卓越性-関連ベンチマーク
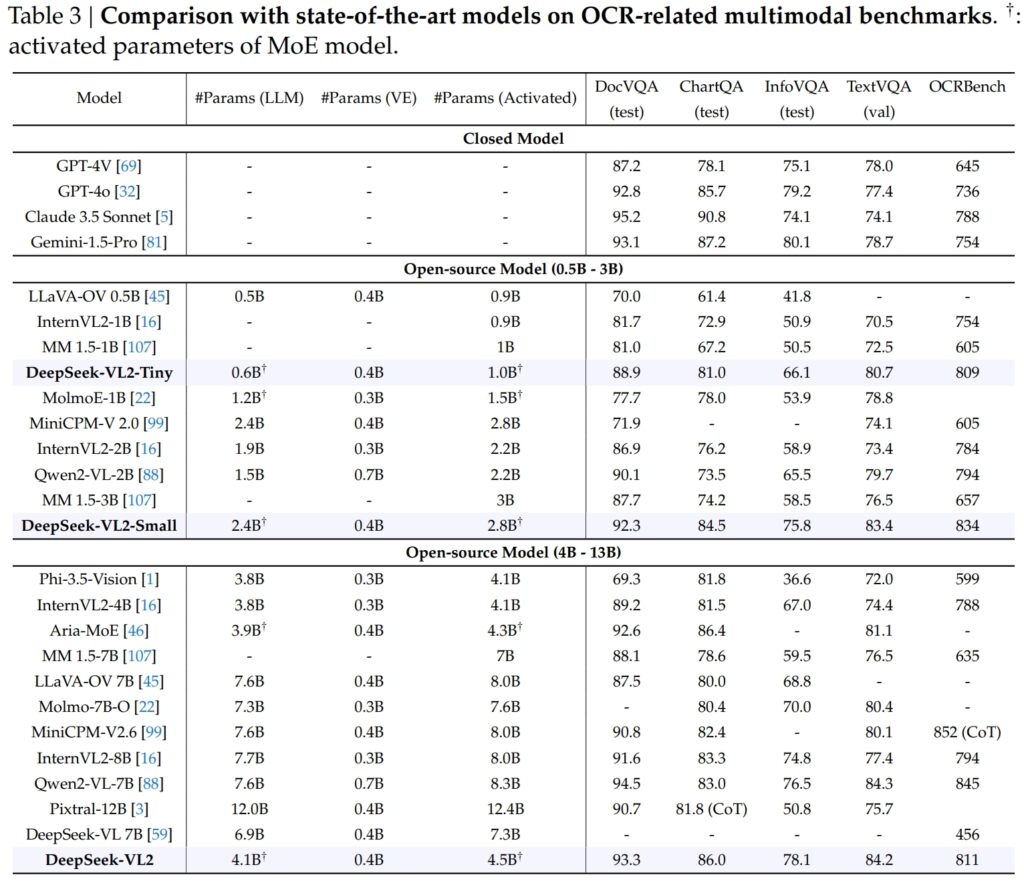
DeepSeek-VL2 の機能は OCR (光学文字) まで顕著に拡張されています。認識)関連タスクは、AI における文書理解とテキスト抽出にとって重要な領域です。 DocVQA テストでは、DeepSeek-VL2-Small は 92.3% という驚異的な精度を達成し、InternVL2-4B (89.2%) や MiniCPM-V2.6 (90.8%) など、同様の規模の他のすべてのオープンソース モデルを上回りました。その精度は、GPT-4o (92.8) や Claude 3.5 Sonnet (95.2) などのクローズド モデルに次ぐものでした。
DeepSeek-VL2 モデルは、ChartQA テストでも 86.0 のスコアでトップとなり、InternVL2 を上回りました。 4B (81.5) および MiniCPM-V2.6 (82.4)。この結果は、チャートを処理し、複雑な視覚データから洞察を抽出する DeepSeek-VL2 の高度な機能を反映しています。
 出典: DeepSeek
出典: DeepSeek
OCRBench では、競争力の高い詳細なテキスト認識のメトリックでは、DeepSeek-VL2 は 7.6B を上回る 811 を達成しました。 Qwen2-VL-7B (845) および MiniCPM-V2.6 (852 with CoT) を紹介し、高密度 OCR タスクにおけるその強みを強調します。
主要なビジョン言語モデルとの比較
OpenAI の GPT-4V や Google の Gemini-1.5-Pro などの業界リーダーと並べると、DeepSeek-VL2 モデルは、パフォーマンスと効率の魅力的なバランス。たとえば、GPT-4V は DocVQA で 87.2 のスコアを獲得しましたが、DeepSeek-VL2 (93.3) は有効化されたパラメータが少ないオープンソース フレームワークで動作しているにもかかわらず、DeepSeek-VL2 (93.3) をわずかに上回っています。
TextVQA では、DeepSeek-VL2-Small は 83.4 を達成し、InternVL2-2B (73.4) や InternVL2-2B (73.4) などの同様のオープンソース モデルを大幅に上回りました。 MiniCPM-V2.0 (74.1)。はるかに大きい MiniCPM-V2.6 (8.0B) でさえ 80.4 に達するに過ぎず、DeepSeek-VL2 のアーキテクチャの拡張性と効率性がさらに強調されました。
ChartQA の場合、DeepSeek-VL2 のスコア 86.0 は Pixtral のスコアを上回りました。 12B (81.8) および InternVL2-8B (83.3)、特殊なタスクで優れた能力を実証
関連: Mistral AI、テキストおよび画像処理用の Pixtral 12B をデビュー
アプリケーションの拡大: 根拠のある会話からビジュアル ストーリーテリング
DeepSeek-VL2 モデルの注目すべき機能の 1 つは、根拠のある会話を行う機能であり、モデルは画像内のオブジェクトを識別し、それらをコンテキストに統合できます。議論。
たとえば、特殊なトークンを使用することで、モデルは場所や説明などのオブジェクト固有の詳細を提供して、画像に関するクエリに答えることができます。これにより、正確な視覚的推論が必要とされるロボット工学、拡張現実、デジタル アシスタントでの応用の可能性が広がります。
もう 1 つの応用分野は、視覚的なストーリーテリングです。 DeepSeek-VL2 は、高度な視覚認識と言語機能を組み合わせて、一連の画像に基づいて一貫した物語を生成できます。
これは、動的なコンテンツ作成が優先される教育、メディア、エンターテイメントなどの分野で特に価値があります。モデルは、強力なマルチモーダル理解を活用して、詳細かつ状況に応じて適切なストーリーを作成し、ランドマークやテキストなどの視覚要素を物語にシームレスに統合します。
視覚的な基盤におけるモデルの能力も同様に強力です。複雑な画像を含むテストにおいて、DeepSeek-VL2 は、説明プロンプトに基づいてオブジェクトを正確に特定し、説明する能力を実証しました。
たとえば、「道路の左側に駐車している車」を識別するように求められた場合、モデルは画像内の正確なオブジェクトを特定し、その応答を示す境界ボックス座標を生成できます。これらの機能により、詳細な視覚分析が重要な自律システムや監視に非常に応用可能です。
オープンソースのアクセシビリティとスケーラビリティ
DeepSeek AI のリリース決定オープンソースとしての DeepSeek-VL2 は、OpenAI の GPT-4V や Google の Gemini-Exp などの競合他社の独自の性質とは顕著に対照的であり、これらは制限されたパブリック アクセス向けに設計されたクローズド システムです。
技術文書によると、 「事前トレーニングされたモデルとコードを一般公開することで、ビジョン言語モデリングの進歩を加速し、研究コミュニティ全体での共同イノベーションを促進することを目指しています。」
DeepSeek-VL2 の拡張性は、その魅力をさらに高めます。これらのモデルは、10GB メモリを搭載したシングル GPU から大規模なワークロードを処理できるマルチ GPU セットアップまで、幅広いハードウェア構成に導入できるように最適化されています。
この柔軟性により、DeepSeek-VL2 は、特殊なインフラストラクチャを必要とせずに、新興企業から大企業まで、あらゆる規模の組織で使用できるようになります。
データとイノベーションのイノベーショントレーニング
DeepSeek-VL2 の成功の主な要因は、その広範で多様なトレーニング データです。事前トレーニング フェーズには、WIT、WikiHow、OBELICS などのデータセットが組み込まれ、一般化のためにインターリーブされた画像とテキストのペアの組み合わせが提供されました。
OCR や視覚的な質問応答などの特定のタスクの追加データは、LaTeX OCR や PubTabNet などのソースから取得され、モデルが一般的なタスクと特殊なタスクの両方を高精度で処理できることが保証されています。
多言語データセットの包含は、世界的な適用性という DeepSeek AI の目標も反映しています。 Wanjuan のような中国語のデータセットは英語のデータセットと統合され、モデルが多言語環境で効果的に動作できるようになりました。
このアプローチにより、英語以外のデータが大半を占める地域における DeepSeek-VL2 の使いやすさが向上し、潜在的なユーザー ベースが大幅に拡大します。
監視付き微調整フェーズにより、モデルの精度がさらに向上しました。 GUI の理解やチャート分析などの特定のタスクに焦点を当てて、機能を強化します。社内データセットと高品質のオープンソース リソースを組み合わせることで、DeepSeek-VL2 はいくつかのベンチマークで最先端のパフォーマンスを達成し、そのトレーニング方法論の有効性を検証しました。
DeepSeek AI の慎重なキュレーション大量のデータと革新的なトレーニング パイプラインにより、VL2 モデルは効率と拡張性を維持しながら、幅広いタスクで優れた性能を発揮できるようになりました。これらの要素により、モデルはマルチモーダル AI の分野にとって価値のある追加機能となります。
ビジュアル グラウンディングや高密度 OCR などの複雑な画像処理タスクを処理できるモデルの機能により、モデルは物流やセキュリティなどの業界に最適です。物流では、倉庫在庫の画像を分析し、品目を特定し、結果を在庫管理システムに統合することで、在庫追跡を自動化できます。
セキュリティ ドメインでは、DeepSeek-VL2 は、記述的なクエリに基づいて物体や個人をリアルタイムで識別し、詳細なコンテキスト情報をオペレーターに提供することで監視を支援できます。
DeepSeek-VL2 の地上での会話機能は、ロボット工学や拡張現実の可能性も提供します。たとえば、このモデルを装備したロボットは、環境を視覚的に解釈し、特定のオブジェクトに関する人間の質問に応答し、視覚入力の理解に基づいてアクションを実行できます。
同様に、拡張現実デバイスは、モデルの視覚的な基礎とストーリーテリング機能を活用して、ガイド付きツアーやリアルタイム環境でのコンテキスト オーバーレイなどのインタラクティブで没入型のエクスペリエンスを提供できます。
>課題と今後の展望
DeepSeek-VL2 には数多くの利点があるにもかかわらず、いくつかの課題に直面しています。重要な制限の 1 つはコンテキスト ウィンドウのサイズであり、現在、単一のインタラクション内で処理できる画像の数が制限されています。
今後の反復でこのコンテキスト ウィンドウを拡張すると、より豊富な複数画像のインタラクションが可能になり、より広範なコンテキストの理解を必要とするタスクにおけるモデルの有用性が高まります。
もう 1 つの課題は、外部の処理にあります。ドメインや、トレーニング データに存在しないぼやけた画像やオブジェクトなどの低品質の視覚入力。 DeepSeek-VL2 は顕著な一般化機能を実証していますが、そのような入力に対する堅牢性が向上することで、現実世界のシナリオ全体への適用性がさらに高まります。
今後を見据えて、DeepSeek AI はモデルの推論機能を強化し、ますます複雑になるマルチモーダルなタスクを処理できるようにする予定です。改善されたトレーニング パイプラインを統合し、より多様なシナリオをカバーするデータセットを拡張することで、DeepSeek-VL2 の将来のバージョンでは、視覚言語 AI のパフォーマンスの新しいベンチマークを設定できる可能性があります。