Google は、Google の Gemini AI とスマートフォンのカメラを利用してユーザーの日常活動を支援する新しいアプリケーションである Project Astra を発表しました。 Google I/O 2024 の基調講演中に発表されたこの取り組みは、実用的な支援を提供できる多用途 AI エージェントを開発する Google の継続的な取り組みを強調するものです。
この機能は、マルチモーダル GPT-4o で実行される ChatGPT のバージョンと非常によく似ています。 OpenAI によって昨日発表されたばかりのモデルです。 Project Astra は、Google I/O 2024 での Gemini の広範な発表の一部です。これには、タスクを高速化する Gemini 1.5 Flash、テキスト プロンプトからビデオを生成する Veo、ローカル デバイスで使用する Gemini Nano などの新しいモデルが含まれます。 Gemini Pro のコンテキスト ウィンドウは 200 万トークンに倍増し、指示に従う能力が強化されています。
AI を活用した視覚支援
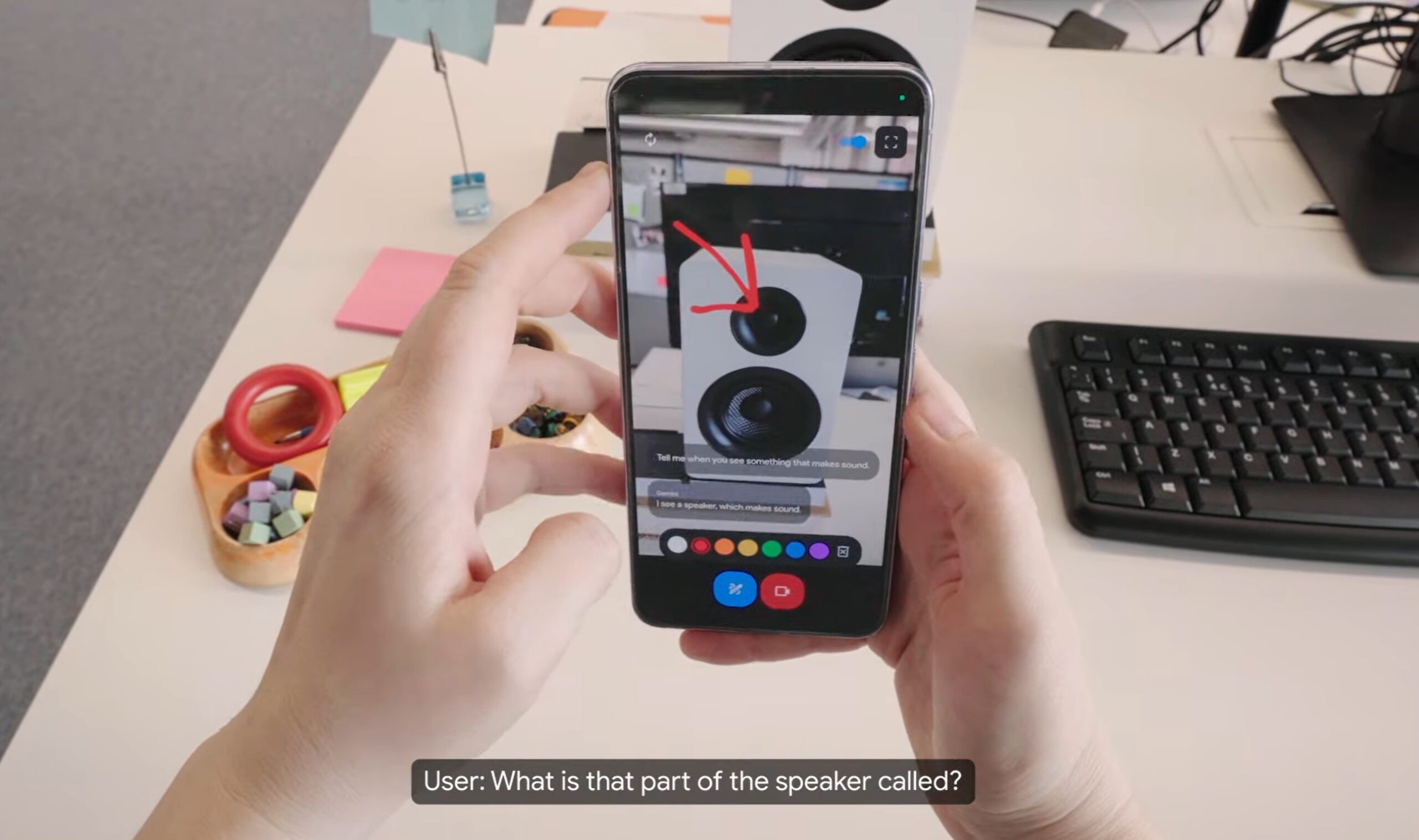
Project Astra は次のように動作します。カメラベースの AI アプリケーション。主にビューファインダーをインターフェースとして使用します。ユーザーは携帯電話のカメラをさまざまな物体に向けて、Gemini という名前の AI と口頭で対話できます。たとえば、ユーザーが AI にオフィス内で音を発する物体を特定するよう依頼すると、Gemini はスピーカーを認識し、ツイーターの特定やその機能の説明など、そのコンポーネントに関する詳細情報を提供しました。
アプリクリエイティブな能力も発揮します。クレヨンのカップの頭韻を作成するよう促されたとき、ジェミニは「創造的なクレヨンは陽気な色をします。彼らは確かにカラフルな作品を作り出します。」
ウェアラブルの統合と記憶の呼び出し
デモンストレーションには、AI がなくなったアイテムの位置を記憶するセグメントが含まれていました。置き忘れたメガネの場所について尋ねられたとき、ジェミニは、メガネが赤いリンゴの近くの机の上にあったことを正確に思い出しました。その後、ユーザーは Google Glass の進化版であるように見え、視点が変わりました。メガネは周囲をスキャンし、ホワイトボード上のシステム図に対する技術的な改善の提案などのコンテキスト情報を提供しました。
[埋め込みコンテンツ]
リアルタイムで視覚データを処理し、過去の観察を思い出す AI の機能これは、ビデオ フレームを継続的にエンコードし、ビデオ入力と音声入力をイベントのタイムラインに結合し、この情報をキャッシュして効率的に呼び出すことで実現されます。この技術の進歩により、AI は迅速かつ正確に応答できるようになり、実用性が向上します。
マルチモーダル インタラクション
Astra はマルチモーダルになるように設計されており、ユーザーは次のことを行うことができます。会話、タイピング、描画、写真、ビデオを通じて対話します。 Google はまた、往復会話のための音声のみのアシスタントである Gemini Live と、ビデオ ナレーションによるウェブ検索のための Google レンズの新機能も導入します。
Google は現在、旅行計画、 Gemini が旅程の作成と編集をお手伝いします。 DeepMind チームは、マルチモーダル モデルを最適に統合し、大規模な一般モデルと小規模で焦点を絞ったモデルのバランスを取る方法をまだ研究中です。
将来の可用性と拡張機能
プロジェクト中Astraはまだ初期段階にあり、具体的な発売日は決まっていないが、GoogleのDeepMind CEOであるDemis Hassabis氏は、AIの一部の機能がGeminiアプリなどのGoogle製品に年内に統合される予定であると示唆した。同社は、対話をより自然で会話的なものにすることを目指して、AI の音声表現力の向上にも取り組んでいます。このようなテクノロジーの潜在的なアプリケーションは、スマートフォンや高度なウェアラブルを通じて、ユーザー エクスペリエンスと生産性を大幅に向上させる可能性があります。