TL;DR
要点: Google Research は、テスト時のトレーニングを使用してモデルが推論中にリアルタイムでデータを学習し記憶できるようにする新しいニューラル アーキテクチャである Titans を発表しました。主な仕様: このアーキテクチャは、200 万トークンを超えるコンテキスト ウィンドウで効果的なリコールを実現し、検索タスクの BABILong ベンチマークで GPT-4 を大幅に上回ります。重要な理由: Titans は、パラメータを積極的に更新して新しいデータの驚きを最小限に抑えることで、リカレント ニューラル ネットワーク (RNN) の壊滅的な忘却とトランスフォーマーの二次コストを解決します。トレードオフ: Titans は、IBM Granite のような静的推論モデルよりも計算量が重いものの、法的証拠開示やゲノム分析などの複雑なタスクに対して優れた表現力を提供します。
Google Research は、推論中にリアルタイムで「記憶することを学習」できるようにすることで、現在の AI モデルの基本的な硬直性に挑戦する新しいニューラル アーキテクチャである「Titans」を発表しました。
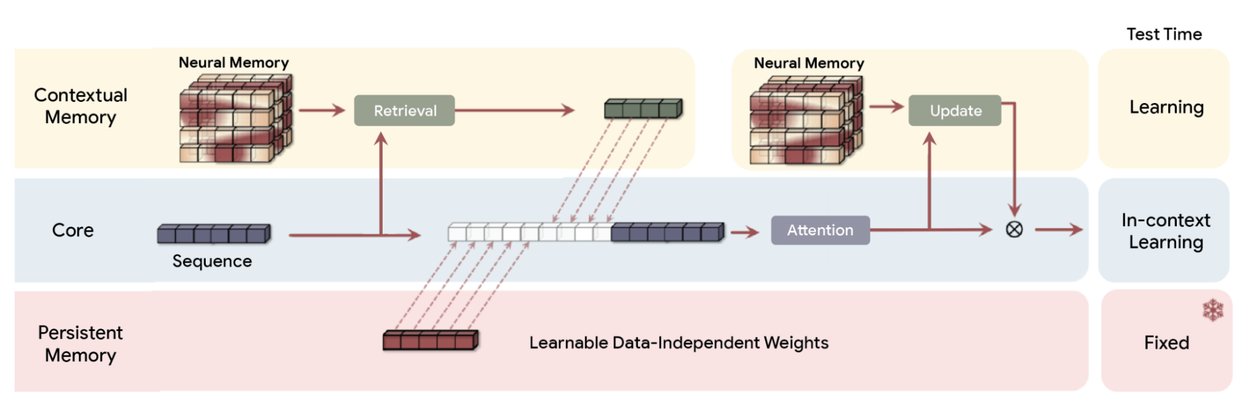
静的な重みやリカレントに依存する従来の Transformer とは異なります。固定状態減衰を使用するニューラル ネットワーク (RNN)、Titans は「ニューラル メモリ」モジュールを採用しています。このコンポーネントは、データ ストリームが入力されると独自のパラメータをアクティブに更新し、コンテキスト ウィンドウを静的バッファではなく継続的なトレーニング ループとして効果的に扱います。
コンテキストでの効果的なリコールを実証します。ウィンドウ数が 200 万トークンを超えると、このアーキテクチャは BABILong ベンチマークで GPT-4 を大幅に上回ります。この「干し草の中に針を入れる」テストでは、広範なドキュメントから特定のデータ ポイントを取得するモデルに挑戦します。このタスクは標準モデルでは失敗することがよくあります。
プロモーション
「ニューラル メモリ」のパラダイム シフト
現在の AI アーキテクチャは、コンテキストの長さと計算効率の間の根本的なトレードオフに直面しています。 GPT-4 や Claude などのモデルの背後にある主要なアーキテクチャであるトランスフォーマーは、シーケンスの長さに応じて二次的にスケールするアテンション メカニズムに依存しています。これにより、非常に長いコンテキストの計算が法外になります。
逆に、Mamba のような線形 RNN はコンテキストを固定状態ベクトルに圧縮します。これにより無限の長さが可能になりますが、新しいデータが古い情報を上書きするため、多くの場合「壊滅的な忘却」が発生します。 Titans では、3 番目のパス「テストタイム トレーニング」(TTT)を導入しています。
初期トレーニング フェーズ後にモデルの重みをフリーズするのではなく、Titans アーキテクチャにより、メモリ モジュールは推論中に学習を継続できます。コンテキスト ウィンドウをデータセットとして扱うことにより、モデルは受信トークンに対してミニ勾配降下ループを実行します。これにより、内部パラメータが更新され、処理中の特定のドキュメントをより適切に表現できるようになります。
Google Research チームが説明しているように、「情報を静的な状態に圧縮するのではなく、このアーキテクチャは、データ ストリームが入力されると積極的に学習して独自のパラメータを更新します。」
このアクティブな学習プロセスを通じて、モデルは圧縮戦略を動的に適応させ、画一的な減衰関数を適用するのではなく、現在のタスクに関連する情報を優先します。
タイタンズの概要(MAC) アーキテクチャ。長期記憶を使用して過去のデータを圧縮し、その概要をコンテキストに組み込んで注意を引きます。その後、アテンションは過去の要約に注目する必要があるかどうかを決定できます。 (出典: Google)
計算オーバーヘッドを管理するために、Titans は勾配誤差に基づく「サプライズ メトリック」を採用しています。新しいトークンを処理するとき、モデルはその予測と実際の入力の差を計算します。誤差が大きい場合は「驚き」を示し、その情報が新規であり、記憶する必要があることを意味します。誤差が低いということは、その情報が冗長であるか、すでに知られている情報であることを示しています。
具体的な例を用いて、研究者らは「新しい単語が『猫』で、モデルの記憶状態がすでに動物の単語を予期している場合、勾配(驚き)は低い。安全に記憶をスキップできる。」
このような選択的記憶は生物学的効率を模倣し、システムが重大な異常や新しい事実を保持しながら日常的なデータを破棄できるようにする。
この能動的な学習を補完するのが、適応的な「忘却メカニズム」です。この関数はゲートとして機能し、物語のコンテキストが大幅に変化するときに重み減衰をメモリ パラメーターに適用します。 Titans は、驚くべき新しいデータの取り込みと古い情報の制御されたリリースのバランスを取ることで、コンテキストの忠実度の高い表現を維持します。
これにより、モデルが固定状態モデルを悩ませるノイズに屈することがなくなります。入れ子学習パラダイムは、このアプローチの理論的基礎を定義します。
「入れ子学習は、複雑な ML モデルが実際には、相互に入れ子になっている、または並行して実行されている一貫した相互接続された最適化問題のセットであることを明らかにします。」
「これらの内部問題のそれぞれには、独自のコンテキスト フローと、そこから学習しようとしている独自の個別の情報セットがあります。」
この理論的基礎は、アーキテクチャと最適化が次のようなものであることを前提としています。同じコインの表裏。モデルを最適化問題の階層として見ることで、Titans はメモリ モジュールの深い計算深さを活用できます。これにより、リカレント ネットワークの有用性を長い間制限してきた「壊滅的な忘却」の問題が解決されます。
エクストリーム コンテキストとベンチマーク
最も注目すべき点は、このアクティブ メモリ システムが、従来のアーキテクチャを打ち破るコンテキスト ウィンドウを処理することです。 Google のベンチマークは、Titans が 2,000,000 トークンを超えるコンテキスト長でも効果的なリコールを維持していることを示しています。比較のために、GPT-4o などの現在の運用モデルは、通常 128,000 トークンに制限されています。
大量の無関係なテキストに埋もれた特定の事実を取得するモデルの能力を測定する、挑戦的な「干し草の中の針」 (NIAH) テストでは、Titans は線形 RNN ベースラインよりも大幅な優位性を実証しました。 8k トークン長の合成ノイズ (S-NIAH-PK) を使用した「シングル ニードル」タスクでは、Titans MAC バリアントは 98.8% の精度を達成しましたが、Mamba2 ではわずか 31.0% でした。
自然言語データのパフォーマンスも同様に堅牢でした。 WikiText バージョンのテスト (S-NIAH-W) では、タイタンズ MAC のスコアは 88.2% でしたが、Mamba2 は 4.2% と苦戦しました。このような結果は、線形 RNN は効率的ではあるものの、実世界の文書に含まれる複雑でノイズの多いデータを処理する場合、その固定状態圧縮が重要な忠実度を失うことを示唆しています。
ベンチマーク パフォーマンス: Titans vs. 最先端のベースライン
Google Research チームは、単純なキーワード検索を超えた機能を強調して、「モデルは単にメモを取るだけではなく、全体を理解し、合成している」と述べています。話。」重みを更新してシーケンス全体の驚きを最小限に抑えることで、モデルは物語の弧の構造的な理解を構築します。これにより、単なるトークンの一致ではなく、セマンティックな関係に基づいて情報を取得できるようになります。
Google は、アーキテクチャの特徴であるメモリ モジュールの詳細な内訳を提供しています。従来のリカレント ニューラル ネットワーク (RNN) は通常、固定サイズのベクトル メモリまたは行列メモリ (基本的にはデータが蓄積するにつれて簡単に過密になったりノイズが増えたりする静的なコンテナ) によって制約されるのですが、Titans では新しいニューラル長期メモリ モジュールを導入しています。
このモジュールは、特に多層パーセプトロン (MLP) を利用して、それ自体でディープ ニューラル ネットワークとして機能します。 Titans は、メモリを静的ストアではなく学習可能なネットワークとして構造化することで、大幅に高い表現力を実現します。このアーキテクチャの変更により、モデルは膨大な量の情報を動的に取り込んで要約できるようになります。
新しい入力用のスペースを確保するために古いデータを単純に切り捨てたり、忠実度の低い状態に圧縮したりするのではなく、MLP メモリ モジュールはコンテキストを合成し、コンテキスト ウィンドウが数百万のトークンに拡張しても重要な詳細とセマンティックな関係が確実に保持されるようにします。
Titans は、検索精度を超えて、一般言語でも有望です。モデリング効率。 3 億 4,000 万のパラメーター スケールで、Titans MAC varianbencht は WikiText データセットで 25.43 のパープレキシティを達成しました。このようなパフォーマンスは、Transformer++ ベースライン (31.52) と元の Mamba アーキテクチャ (30.83) の両方を上回っています。
これは、アクティブなメモリの更新により、静的な重みだけよりも言語の確率分布をより適切に表現できることがわかります。このプロジェクトの主任研究員である Ali Behrouz 氏は、この設計の理論的意味を強調し、「Titans は TC0 を超える問題を解決できる。つまり、状態追跡タスクにおいて、Titans は理論的にはトランスフォーマーや最新の線形リカレント モデルよりも表現力が高いことを意味する。」
このような表現力により、Titans は、長いコード ファイル内の変化する変数を追跡したり、小説のプロット ポイントを追跡したりするなど、単純なリカレントを混乱させることが多い状態追跡タスクを処理できるようになります。
効率: MIRAS 対 マーケット
これらのアーキテクチャ上の革新を形式化するために、Google は MIRAS フレームワークを導入しました。トランスフォーマー、RNN、タイタンなどのさまざまなシーケンス モデリング アプローチを統合することで、このモデルは「連想メモリ」の傘下で動作します。
Google によると、MIRAS フレームワークはシーケンス モデリングを 4 つの基本的な設計選択肢に分解します。 1 つ目はメモリ アーキテクチャです。これは、単純なベクトルや行列からタイタンに見られる深い多層パーセプトロンに至るまで、情報を保存するために使用される構造形式を決定します。これは、モデルが受信データに優先順位を付ける方法を管理する内部学習目標である注意バイアスと組み合わせて、記憶すべき重要なものを効果的に決定します。
容量を管理するために、フレームワークはリテンション ゲートを採用します。 MIRAS は、伝統的な「忘却メカニズム」を特定の形式の正則化として再解釈し、新しい概念の学習と歴史的コンテキストの保持の間の安定したバランスを確保します。最後に、メモリ アルゴリズムによってメモリ状態の更新に使用される特定の最適化ルールが決定され、アクティブ ラーニングのサイクルが完了します。
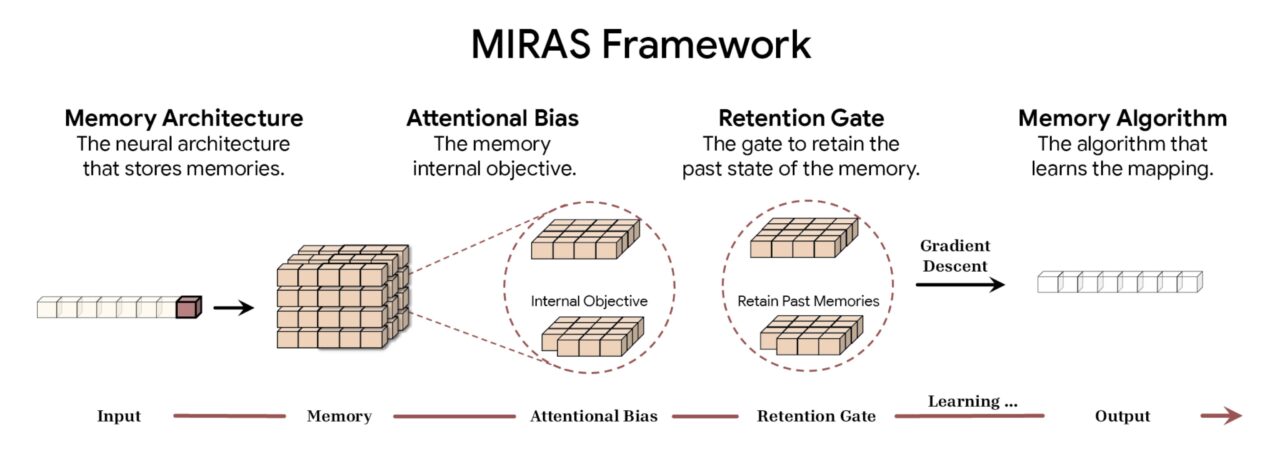 MIRAS フレームワークの概要 (出典: Google)
MIRAS フレームワークの概要 (出典: Google)
これら 4 つのコンポーネントへのダウン シーケンス モデリングにより、MIRAS は注意メカニズムの「魔法」を解明します。それは、それらを特定のバイアスと保持設定を持つ単なる 1 つのタイプの連想記憶として再分類します。このようにして、研究者はコンポーネントを組み合わせて組み合わせることができ、注意の精度と反復の効率性を組み合わせたハイブリッド アーキテクチャにつながる可能性があります。
アーキテクチャ パラダイム シフト: MIRAS フレームワーク
動的な大容量メモリは、多くの場合、ローカル展開用に静的モデルを縮小することが目標となるエッジ AI の一般的なトレンドとははっきりと対照的です。たとえば、IBM による Granite 4.0 Nano の発表では、ラップトップで実行するように設計された 3 億 5,000 万ものパラメータをもつモデルが導入されました。
IBM の戦略は静的インテリジェンスをユビキタスかつ安価にすることに焦点を当てていますが、Google の Titans アプローチはモデル自体をよりスマートで適応性の高いものにすることを目指しています。これは、推論中に重みを更新する計算オーバーヘッドが必要な場合でも当てはまります。
計算オーバーヘッド、つまり「コンテキスト ギャップ」は、依然として Titans にとっての主なハードルです。メモリ パラメーターをリアルタイムで更新すると、Granite や Llama などのモデルで使用される静的推論よりも計算コストが高くなります。ただし、法的証拠開示、ゲノム分析、コードベースのリファクタリングなど、大規模なデータセットの深い理解を必要とするアプリケーションの場合、生の推論速度よりもドキュメントを「学習」する機能の方が価値があることが判明する可能性があります。
この自己修正ビジョンの最初の実装として機能する「Hope」アーキテクチャは、 の概念実証として導入されました。 href=”https://research.google/blog/introducing-nested-learning-a-new-ml-paradigm-for-continual-learning/”target=”_blank”>ネストされた学習の論文。業界がより長いコンテキストとより深い推論を求め続ける中、トレーニングと推論の間の境界線を曖昧にする Titans のようなアーキテクチャが、次世代の基礎モデルを定義する可能性があります。