DeepSeek は、最新のオープンソース AI モデルである DeepSeek-R1 および DeepSeek-R1-Zero を発表し、強化学習 (RL) を通じて推論機能を実現する方法を再定義しました。
新しいモデルは、教師あり微調整 (SFT) が必須ではないことを証明することで、従来の AI 開発に挑戦します。高度な問題解決能力を養います。 OpenAI の o1 シリーズなどの独自システムに匹敵するベンチマーク結果により、DeepSeek のモデルは、競争力のある高性能ツールを提供する上でオープンソース AI の潜在力が増大していることを示しています。
これらのモデルの成功は、強化に対する独自のアプローチにあります。学習 (RL)、コールドスタート データの導入、および効果的な蒸留プロセス。これらのイノベーションにより、コーディング、数学、および一般的な論理タスクにおける推論機能が生み出され、主要な独自モデルの競合相手としてのオープンソース AI の存続可能性が強調されました。
関連: DeepSeek AI オープンソース VL2 シリーズのビジョン言語モデル
ベンチマーク結果がオープンソースの可能性を浮き彫りにする
広く評価されているベンチマークにおける DeepSeek-R1 のパフォーマンスは、その機能を裏付けています。
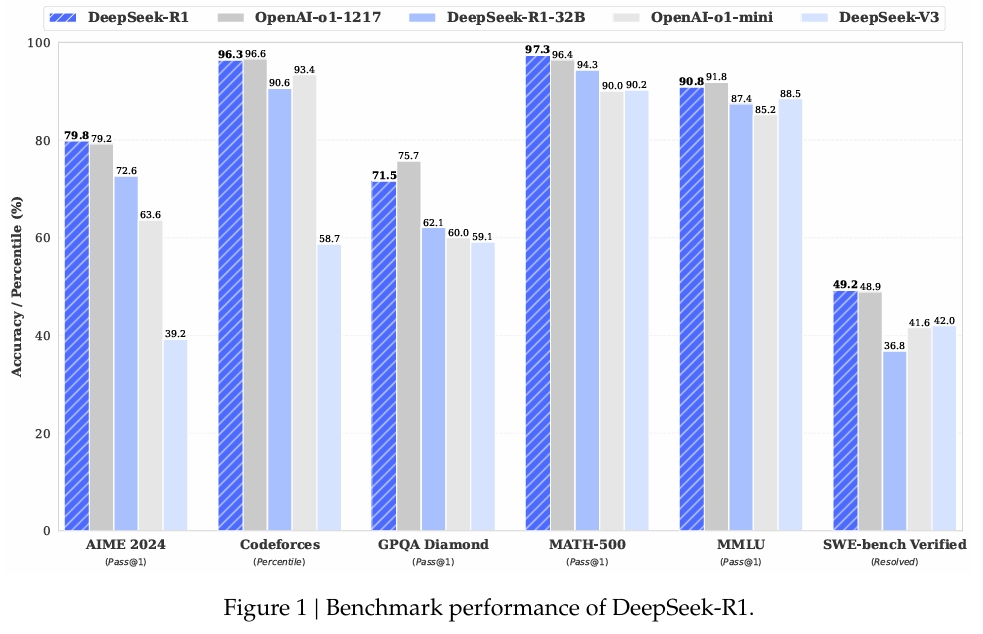
数学的問題解決を評価するために設計されたデータセットである MATH-500 において、DeepSeek-R1 はPass@1 スコアは 97.3% で、OpenAI の o1-1217 モデルと一致します。高度な推論タスクに焦点を当てた AIME 2024 ベンチマークでは、モデルのスコアは 79.8% で、OpenAI の結果をわずかに上回りました。
コーディングおよびロジック タスクのベンチマークである LiveCodeBench でのモデルのパフォーマンスも同様に注目に値します。 Pass@1-CoT スコアは 65.9%。 DeepSeek の調査によると、このカテゴリのオープンソース モデルの中でトップパフォーマンスを誇るモデルの 1 つとなっています。
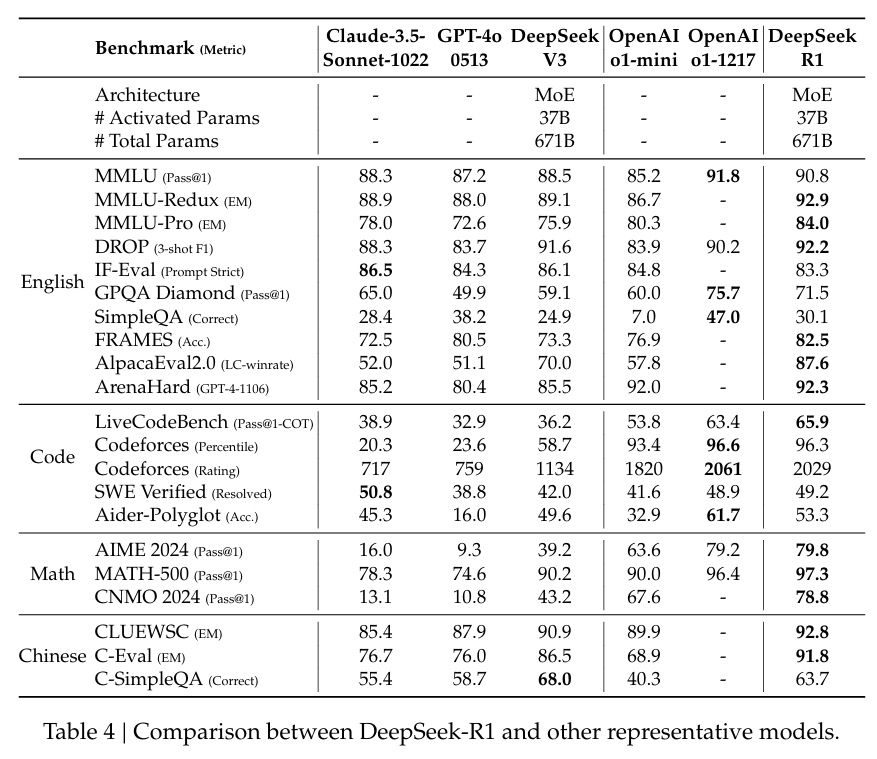
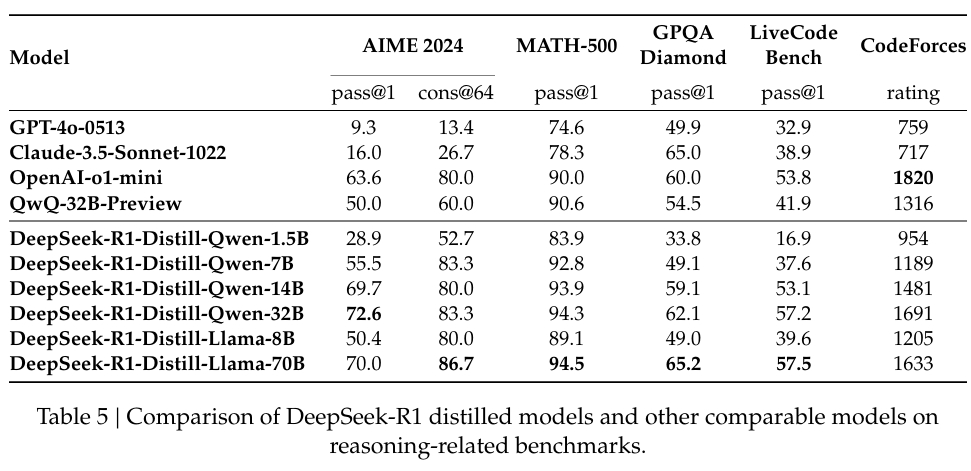
同社は蒸留にも多額の投資を行っており、 DeepSeek-R1 の小規模バージョンは、より大きなモデルの推論機能の多くを保持しています。特に、320 億のパラメータ モデルである DeepSeek-R1-Distill-Qwen-32B は、計算的にアクセスしやすいと同時に、いくつかのカテゴリで OpenAI の o1-mini を上回りました。
教師なしの強化学習: DeepSeek-R1-Zero
DeepSeek-R1-Zero は、同社の大胆な試みです。 RLのみのトレーニング。独自のアルゴリズムであるグループ相対ポリシー最適化 (GRPO) を採用しており、個別の批評家モデルの必要性を排除することで RL トレーニングを合理化します。
代わりに、グループ化されたスコアを使用してベースラインを推定し、計算コストを大幅に削減します。トレーニングの質を維持します。このアプローチにより、モデルは思考連鎖 (CoT) 推論や内省などの推論動作を開発できるようになります。
研究論文、DeepSeek チーム述べた:
「DeepSeek-R1-Zero は、自己検証、リフレクション、長い CoT の生成などの機能を実証します。ただし、反復、可読性、言語の混合に問題があり、現実世界のユースケースにはあまり適していません。」
これらの新たな動作は有望ですが、モデルの限界により改良の必要性が浮き彫りになりました。たとえば、その出力は時々繰り返したり、混合言語の問題が表示されたりして、実際のシナリオでの使いやすさを低下させていました。
RL のみからハイブリッド トレーニングへ: DeepSeek-R1
これらの課題に対処するために、DeepSeek は、RL と教師付き微調整を組み合わせた DeepSeek-R1 を開発しました。このプロセスは、ベースラインの一貫性と可読性を向上させるために設計された、人間が判読できる厳選されたコールドスタート データセットから始まりました。この基盤により、このモデルは、明瞭さと関連性に対する人間の期待に応える能力が向上して RL に入りました。
関連: LLaMA AI Under Fire: What Meta 「オープンソース」モデルについては伝えていない
DeepSeek は、ドキュメントでこのアプローチについて次のように説明しています。
「R1-Zero とは異なり、ベース モデルからの RL トレーニングの初期の不安定なコールド スタート フェーズを防ぐため」 、R1 では、初期 RL アクターとしてモデルを微調整するために、少量の長い CoT データを構築および収集します。」
パイプラインには、推論能力と問題解決能力をさらに洗練するための反復 RL も含まれています。モデルを制作するコーディングや数学的証明などの複雑なシナリオを処理できます。
オープンソースのアクセシビリティと今後の課題
DeepSeek は、MIT ライセンスの下でモデルをリリースしました。オープンソース原則への取り組みを強調している。このライセンス モデルにより、研究者や開発者は DeepSeek の成果物を自由に使用、変更、構築できるため、AI コミュニティでのコラボレーションとイノベーションが促進されます。
成功にもかかわらず、チームは課題が残っていることを認めています。混合言語の出力、プロンプトの感度、およびより優れたソフトウェア エンジニアリング能力の必要性は、改善の余地がある領域です。 DeepSeek-R1 の今後のバージョンでは、その機能を新しい領域に拡張しながら、これらの制限に対処することを目指しています。
研究者らは、次のように述べて、その進歩について楽観的な見方を示しています。
「コールドのパターンを慎重に設計することで、人間の事前分布を使用してデータを開始すると、DeepSeek-R1-Zero に対してパフォーマンスが向上することがわかります。私たちは、反復トレーニングが推論モデルにとってより良い方法であると信じています。」
AI 業界への影響
DeepSeek の研究は、AI 研究環境の変化を示唆しています。オープンソース モデルが独自のリーダーと競合できるようになり、RL が SFT なしで高度な推論を達成できることを証明し、アクセシビリティを拡張するための蒸留を強調することで、DeepSeek は将来の AI のベンチマークを設定しました。
オープンソース AI が進化し続ける中、DeepSeek-R1 の進歩は、RL を活用して実用的で高性能なモデルを生成するための青写真を提供します。