Microsoft は、以前の rStar フレームワーク。数学的推論における小規模言語モデル (SLM) の限界を押し広げます。
OpenAI の o1-preview などの大規模システムに匹敵するように設計された rStar-Math は、問題解決において優れたベンチマークを達成しながら、コンパクトなモデルが競争力のあるレベルでどのようにパフォーマンスできるかを実証します。この開発は、スケールアップから特定のタスクのパフォーマンスの最適化へと移行する、AI の優先順位の変化を示しています。
rStar から rStar-Math への進化
rStar昨年夏のフレームワークは、モンテカルロ ツリー検索 (MCTS) というアルゴリズムを通じて SLM 推論を強化するための基礎を築きました。複数のパスをシミュレートおよび検証することでソリューションを改良します。
rStar は、より小さなモデルでも複雑なタスクを処理できることを実証しましたが、そのアプリケーションは依然として一般的でした。 rStar-Math は、この基盤の上に、数学的推論に合わせて調整された的を絞ったイノベーションで構築されています。
rStar-Math の成功の中心は、コード拡張された思考連鎖 (CoT) 方法論であり、モデルは両方のソリューションを生成します。自然言語と実行可能な Python コード。
この二重出力構造により、中間推論ステップが検証可能になり、エラーが減少し、論理的一貫性が維持されます。研究者らは、このアプローチの重要性を強調し、「相互の一貫性は、監督がない場合の人間の一般的な習慣を反映しており、導き出された答えについて仲間の間で合意があれば、正しさの可能性が高いことが示唆されます。」
関連: 中国の DeepSeek R1-Lite-Preview モデル、自動推論における OpenAI のリードを狙う
CoT に加えて、rStar-Math はプロセス優先モデル (PPM) を導入しています。品質に基づいて中間ステップを評価し、ランク付けします。ノイズの多いデータに依存することが多い従来の報酬システムとは異なり、PPM は論理的な一貫性と精度を優先し、モデルの信頼性をさらに高めています。
「PPM は次のように述べています。」広範な MCTS ロールアウトを使用したにもかかわらず、Q 値はまだ各推論ステップをスコアリングできるほど正確ではありませんが、Q 値は肯定的な (正しい) ステップと否定的なステップを確実に区別できるという事実
したがって、トレーニング メソッドは、Q 値に基づいて各ステップの好みのペアを構築し、ペアごとのランキング損失を使用して各推論ステップの PPM のスコア予測を最適化し、信頼性の高いラベル付けを実現します。このアプローチは、Q 値を報酬ラベルとして直接使用する従来の方法を回避します。この方法は本質的にノイズが多く、段階的な報酬の割り当てが不正確です。」
最後に、両方のフロンティアを段階的に構築する 4 ラウンドの自己進化レシピです。ポリシー モデルと PPM を最初から作成します。
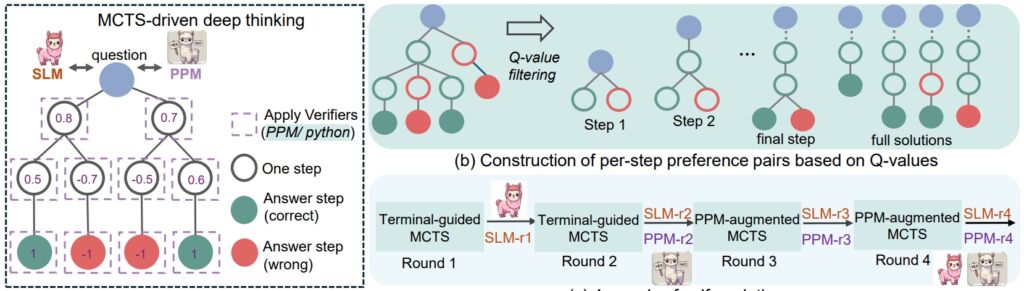 rSTar-Math 推論手順 (出典: 研究論文)
rSTar-Math 推論手順 (出典: 研究論文)
大規模なモデルに挑戦するパフォーマンス
rStar-Math は数学的推論の新しい標準を確立します
GSM8K データセットで、大規模な AI システムに匹敵する、場合によってはそれを上回る結果を達成します。 (数学的推論のテスト) では、rStar-Math を統合した後、70 億のパラメーター モデルの精度が 12.51% から 63.91% に向上しました。 href=”https://en.wikipedia.org/wiki/American_Invitational_Mathematics_Examination”>米国招待数学試験 (AIME)では、このモデルは問題の 53.3% を解決し、高校参加者の上位 20% にランクされました。
MATH データセットの結果も同様に印象的で、rStar-Math は 90% の精度率を達成し、OpenAI の o1-preview を上回りました。
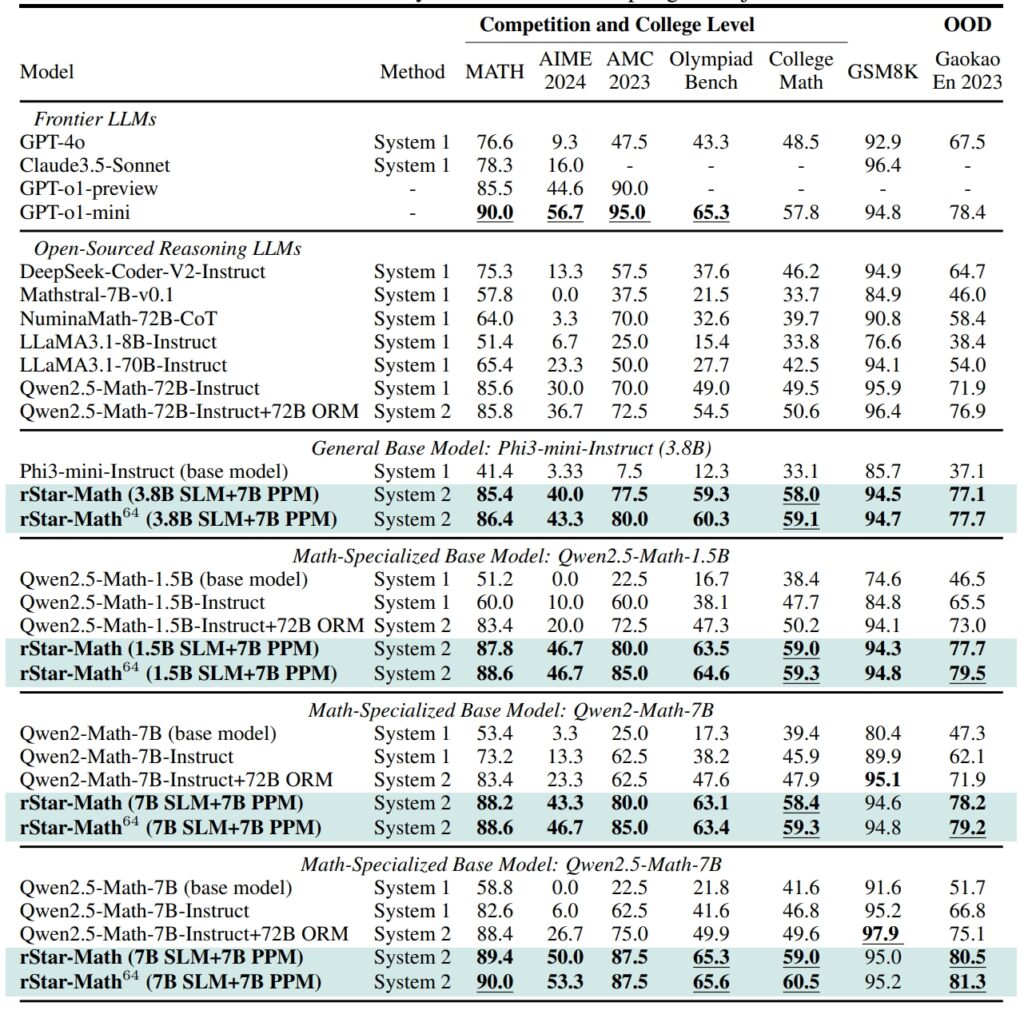 rStar-Math およびその他のフロンティア LLM のパフォーマンス最も困難な数学ベンチマーク (出典: 研究論文)
rStar-Math およびその他のフロンティア LLM のパフォーマンス最も困難な数学ベンチマーク (出典: 研究論文)
これらの成果は、SLM が以前はリソースを大量に消費する大規模モデルによって支配されていたタスクを処理できるようにするフレームワークの能力を強調しています。 rStar-Math は、論理的な一貫性と検証可能な中間ステップを重視することで、AI の最も永続的な課題の 1 つである、複雑な問題空間全体にわたって信頼性の高い推論を保証することに対処します。
rStar-Math を推進する技術革新
rStar から rStar-Math への進化により、いくつかの重要な進歩がもたらされました。 MCTS の統合は依然としてフレームワークの中心であり、モデルが多様な推論パスを探索し、最も有望なものに優先順位を付けることが可能になります。
コード検証に重点を置いた CoT 推論の追加により、出力が解釈可能かつ正確であることが保証されます。
関連: Alibaba の QwQ-32B-プレビューが OpenAI との AI モデル推論バトルに参加
おそらく最も変革的なのは、rStar-Math の自己進化トレーニング プロセスです。このフレームワークは 4 回の反復ラウンドにわたって、各ステップでより質の高い推論データを組み込んで、ポリシー モデルと PPM を改良します。
この反復的なアプローチにより、モデルのパフォーマンスを継続的に向上させ、大規模なモデルからの蒸留に依存せずに最先端の結果を達成できます。
rStar-Math の比較OpenAI の o1 へ
Microsoft は小規模モデルの最適化に重点を置いていますが、OpenAI は引き続きシステムのスケールアップを優先しています。
ChatGPT プロ プランの一部として 2024 年 12 月に導入された o1 プロ モードは、コーディングや科学研究など、一か八かのアプリケーション向けに調整された高度な推論機能を提供します。 OpenAI は、o1 Pro モードが AIME で 86% の精度率を達成し、Codeforces などのコーディング ベンチマークで 90% の成功率を達成したと報告しました。
rStar-Math は AI イノベーションの変化を表しており、業界の大規模モデルへの注目に挑戦します。高度な推論を達成するための主な手段として。 Microsoft は、ドメイン固有の最適化によって SLM を強化することで、計算コストと環境への影響を削減する持続可能な代替手段を提供します。
関連: 熟議的調整: o1 および o3 思考モデルに対する OpenAI の安全戦略
数学的推論におけるフレームワークの成功により、教育から幅広い用途への扉が開かれる
研究者らは、rStar-Math のコードとデータを GitHub でリリースし、さらなるコラボレーションと開発への道を開くことを計画しています。この透明性は、学術機関や中規模組織を含む幅広いユーザーが高性能 AI ツールにアクセスできるようにするための Microsoft のアプローチを反映しています。
関連: 半分析: いいえ、AI スケーリングは問題です。速度を落とすことはありません
Microsoft と OpenAI 間の競争が激化する中、rStar-Math によってもたらされた進歩は、より小さなモデルがより大きなシステムの優位性に挑戦する可能性を浮き彫りにしています。 rStar-Math は、効率と精度を優先することで、コンパクトな AI システムが達成できるものについての新しいベンチマークを設定します。