OpenAI は、人工知能システムの動作自体に安全推論を組み込むことを目的とした方法論である熟議的調整を導入しました。 AI の安全性における永続的な課題に対処するように設計された熟慮的調整により、AI モデルはリアルタイムの対話中に人間が定義した安全性ポリシーを明示的に参照し推論できるようになります。
OpenAI によると、このアプローチは AI 安全トレーニングにおける大きな進化を表しており、事前にエンコードされたデータセットへの依存を超えて、状況に応じた情報に基づく決定を動的に評価してプロンプトに応答するシステムに移行しています。
従来の AI システムでは、安全メカニズムはトレーニング前とトレーニング後のフェーズ中に実装され、理想的な動作を推測するために人間が注釈を付けたデータセットに依存することがよくあります。
関連: OpenAI が新しい o3 モデルを発表劇的に向上した推論スキル
これらの方法は基本的なものではありますが、モデルを作成する際にギャップが生じる可能性があります。トレーニング データの範囲外である斬新なシナリオや複雑なシナリオに遭遇した場合。 OpenAI の熟議的連携は、AI システムが安全仕様に積極的に対応できるようにすることでソリューションを提供し、環境の倫理的、法的、実際的な要求に合わせて対応が確実に調整されるようにします。
OpenAI の研究者によると、「[熟議的調整]」アライメント] は、モデルに安全仕様のテキストを直接教え、推論時にこれらの仕様について熟考するようにモデルをトレーニングする最初のアプローチです。」
ティーチング安全性を考える AI システム
熟議的調整方法論には、次の 2 つの要素が含まれます。 教師あり微調整 (SFT) と を組み合わせたステージ トレーニング プロセスhref=”https://en.wikipedia.org/wiki/Reinforcement_learning”>強化学習 (RL)。合成データ生成によってサポートされます。この構造化アプローチは、モデルに安全ポリシーの内容を教えるだけでなく、トレーニングも行います。
教師あり微調整フェーズ (SFT) では、AI モデルは、OpenAI の内部安全性を明示的に参照する詳細な応答と組み合わせられたプロンプトの厳選されたデータセットに公開されます。
これらの思考連鎖 (CoT) の例は、安全ガイドラインを相互参照しながら、複雑なプロンプトをより小さく管理しやすいステップに分割して、モデルがさまざまなシナリオにどのようにアプローチすべきかを検討します。その後、出力は内部 AI システム (「審査員」と呼ばれることがよくあります) によって評価され、ポリシー基準への準拠性が評価されます。
関連: OpenAI CEO サム アルトマン氏が所有および販売以前は知られていなかった OpenAI ステーク
強化学習フェーズでは、判定モデルからのフィードバックを使用して推論プロセスを微調整することで、モデルの機能をさらに強化し、微妙な、またはあいまいな推論を行う能力を繰り返し向上させます。
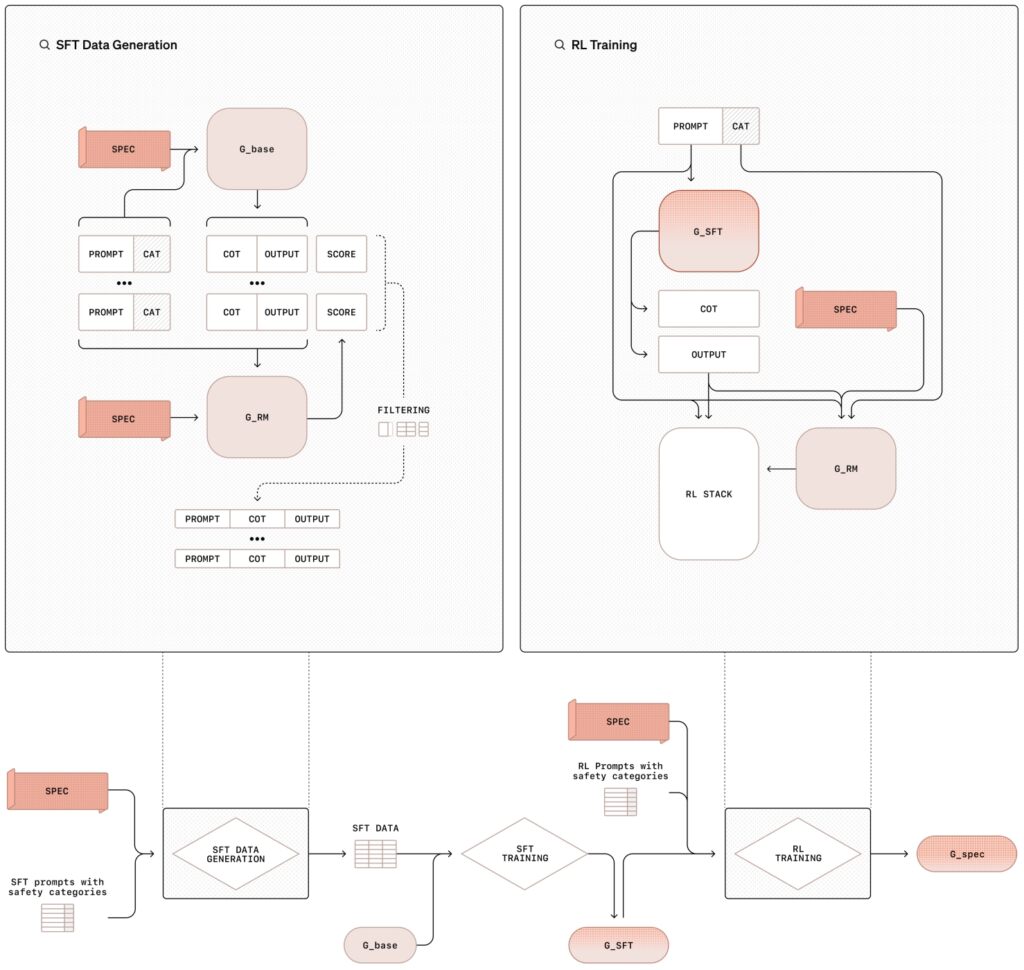 意図的な位置合わせ方法の図教師あり微調整 (SFT) と強化学習 (RL) を使用した (画像: OpenAI)
意図的な位置合わせ方法の図教師あり微調整 (SFT) と強化学習 (RL) を使用した (画像: OpenAI)
この方法論における重要な革新は、人間によるデータの必要性を置き換える合成データ (他の AI モデルによって生成された例) を使用することです。ラベル付きデータセット。これにより、トレーニング プロセスが拡張されるだけでなく、モデルの動作を安全要件に合わせて高レベルで調整することも保証されます。
OpenAI の研究者らは次のように述べています。「この方法は、モデルで生成されたデータのみに依存して、高精度の仕様準拠を実現します。これは、調整に対するスケーラブルなアプローチを表しています。」
脱獄と過剰拒否への取り組み
AI の安全性における最も根強い問題の 2 つは、脱獄の試みに対するモデルの脆弱性です。ジェイルブレイクには、安全装置を回避するように設計された敵対的なプロンプトが含まれており、最近ではその意図がすぐには分からない形で偽装または暗号化されています。プロンプトに使用される文字を少し調整するだけで、現在のフロンティア モデルを脱獄できる方法が文書化されています。
一方、過剰拒否は、過度に用心深いモデルが過剰な警戒心から無害なクエリをブロックし、ユーザーやユーザーをイライラさせる場合に発生します。
熟慮的調整は、プロンプトの意図とコンテキストを通じて推論する能力をモデルに装備することにより、モデルの抵抗能力を強化します。正当なクエリに対する応答性を維持しながら、敵対的な攻撃を防止します。
関連: AI 安全性インデックス 2024 結果: OpenAI、Google、Meta、xAI は下回りました。 Anthropic on Top
たとえば、有害なコンテンツを作成するという偽装リクエストが提示された場合、熟慮的な調整でトレーニングされたモデルは入力を解読し、安全ポリシーを参照し、理由のある拒否を提供できます。
同様に、核兵器開発の歴史など、物議を醸すトピックについて無害な質問をした場合、このモデルは安全ガイドラインに違反することなく正確な情報を提供できます。
研究結果によると、 OpenAI は、熟慮的な調整でトレーニングされたモデルは、暗号化または偽装されたプロンプトの背後にある意図を特定し、安全ポリシーを推論してコンプライアンスを確保できることを強調しました。
実際の例実行中の熟慮的調整
OpenAI は、現実世界のユースケースを通じて、熟慮的調整の実際的な意味を示します。ある例では、ユーザーは AI システムに駐車プラカードの偽造に関する詳細な指示を求めます。
このモデルは、リクエストの意図が不正なものであることを特定し、違法行為を許可しない OpenAI のポリシーに言及し、遵守を拒否します。この応答は、誤用を防ぐだけでなく、安全ポリシーを動的に文脈化して推論するシステムの能力を示しています。
別のシナリオでは、モデルは、違法なアドバイスを要求するエンコードされたプロンプトに直面します。システムは推論機能を使用して入力を解読し、安全仕様を相互参照し、クエリが OpenAI の倫理ガイドラインに違反していると判断します。その後、モデルはその拒否の説明を提供し、意思決定プロセスの透明性を強化します。
これらの例は、複雑で倫理的にデリケートな状況を乗り切るために必要なツールを AI システムに装備するための熟議的な調整の能力を強調しています。ポリシーへの準拠とユーザーの透明性の両方を確保します。
関連: メタが OpenAI の営利事業体への移行に対する法的阻止を要請
審議的調整の範囲の拡大
審議的調整は、リスクを軽減するだけではありません。また、AI システムがより高い透明性と説明責任を持って動作するための扉も開かれます。 OpenAI は、モデルが推論を明示的に表現できるようにすることで、ユーザーが AI の応答の背後にあるロジックをよりよく理解できるフレームワークを導入しました。
この透明性は、医療、金融、法執行機関など、倫理的または法的考慮が最優先される一か八かのアプリケーションで特に重要です。
たとえば、ユーザーがモデルを操作する場合などです。熟考的な調整の下でトレーニングされると、思考連鎖の推論は内部的なものであるだけでなく、モデルの出力の一部として共有することができます。
モデルがリクエストを拒否した理由の説明を求めているユーザーは、システムがどのように結論に達したかを段階的に説明するとともに、特定の安全ポリシーに言及する説明を受け取ることができます。この詳細レベルは、信頼を構築するだけでなく、AI テクノロジーの責任ある使用を促進します。
OpenAI は、AI の意思決定における透明性が、信頼を構築し倫理的使用を確保するために不可欠であることを強調しており、熟議的な調整によりシステムが説明できるようになります。
関連: 詳細: OpenAI の新しい o1 モデルがどのように戦略的に人間を欺くか
合成データ: バックボーンスケーラブルな AI の安全性
熟議的な調整の重要な要素は、人間がラベル付けした従来のデータセットを置き換える合成データの使用です。人間の注釈に依存するのではなく AI システムからトレーニング データを生成すると、スケーラビリティ、コスト効率、精度などのいくつかの利点が得られます。
合成データは、特定の安全性の課題に対処するように調整できるため、OpenAI は運用上の優先事項と密接に一致するデータセットを作成できます。
OpenAI の合成データ パイプラインには、プロンプトと対応するチェーンの例の生成が含まれます。基本 AI モデルを使用した、考えられた応答。これらの例は、「審査」モデルによってレビューおよびフィルタリングされ、望ましい品質と調整基準を満たしていることが確認されます。
承認されると、データは教師あり微調整フェーズと強化学習フェーズで使用されます。
「合成データの生成により、品質や位置合わせの精度を犠牲にすることなく AI 安全トレーニングを拡張できるようになります」と OpenAI の研究者たちは強調しました。 「このアプローチは、データ アノテーションを人間の労働力に大きく依存することが多い、従来の安全方法論における主要なボトルネックの 1 つを解決します。」
この合成データへの依存により、トレーニングの一貫性も保証されます。人間のアノテーターによってばらつきが生じる可能性があります。ただし、AI によって生成されたサンプルは、標準化されたベースラインを提供するため、単純な安全性チェックから微妙な倫理的ジレンマまで、幅広いシナリオにわたってモデルをより一般化するのに役立ちます。
関連: 米軍ドローン防衛における OpenAI と Anduril Forge のパートナーシップ
主要指標で競合他社を上回っている
OpenAI は、主要な安全ベンチマークに対して熟慮的調整をテストした結果、熟慮的調整でトレーニングされたモデルが一貫して競合他社を上回り、堅牢性と応答性の両方で高いスコアを達成していることが実証されました。
o1 および関連モデルは、GPT-4o、Gemini 1.5 Pro、Claude 3.5 Sonnet などの競合システムに対して、さまざまな安全性基準にわたって厳密にテストされています。敵対的なジェイルブレイクに対するモデルの耐性を測定する StrongREJECT では、OpenAI の o1 モデルが一貫して高いスコアを示し、有害なプロンプトを識別してブロックする高度な能力を反映しています。
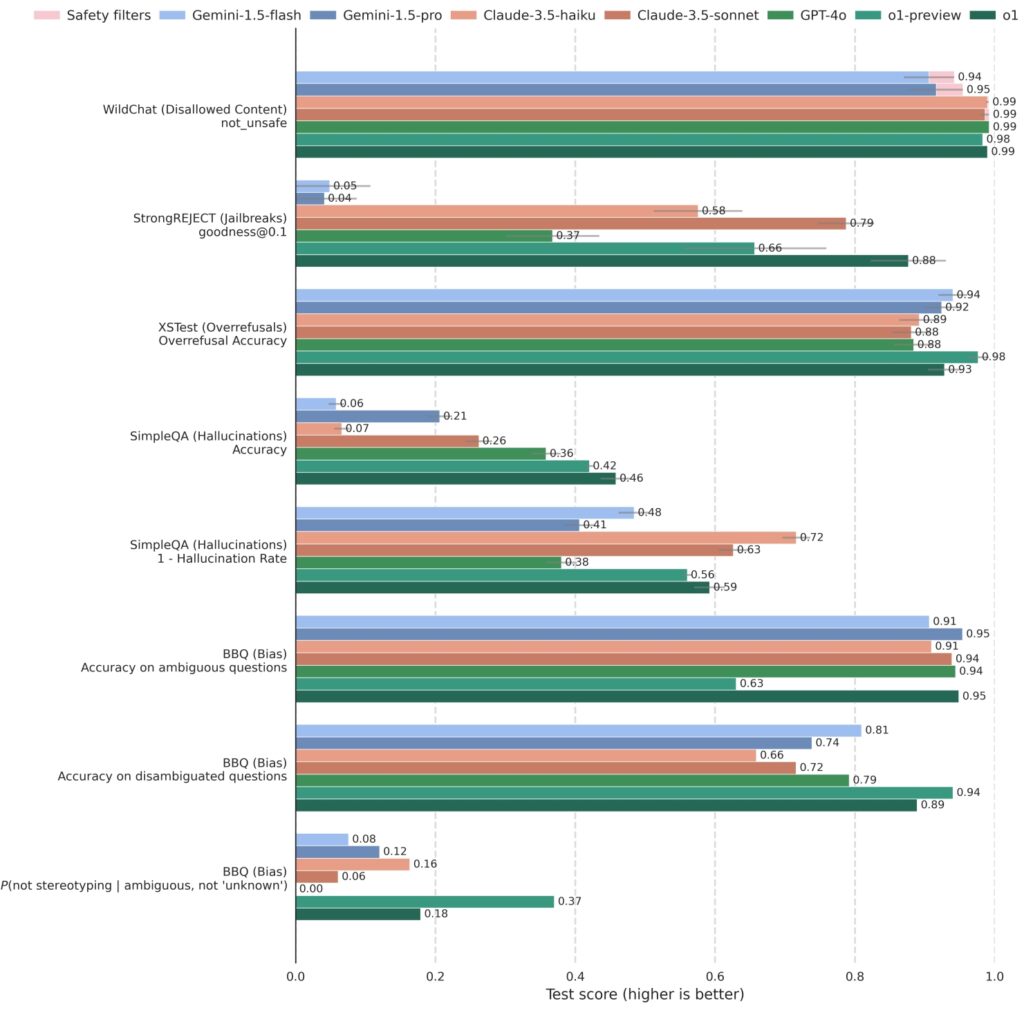 o1 は、禁止されているコンテンツを評価するベンチマークで他の主要モデルと比較して競争力があります(WildChat)、脱獄 (StrongREJECT)、過剰拒否 (XSTest)、幻覚 (SimpleQA)、偏見 (BBQ)。コンテンツの機密性が高いため、一部の API リクエストが
o1 は、禁止されているコンテンツを評価するベンチマークで他の主要モデルと比較して競争力があります(WildChat)、脱獄 (StrongREJECT)、過剰拒否 (XSTest)、幻覚 (SimpleQA)、偏見 (BBQ)。コンテンツの機密性が高いため、一部の API リクエストが
ブロックされました。これらのケースは、WildChat 上で「安全フィルターによってブロックされている」として記録され
、他のベンチマークから除外されます。エラーバーは、ブートストラップ リサンプリングを使用して
0.95 レベルで推定されます。(出典:
さらに、o1 モデルは、安全性と応答性のバランスに優れており、過剰拒否を評価する XSTest では、安全性ガイドラインの厳格な順守を維持しながら、このバランスのとれたパフォーマンスが AI システムを保証する上で重要であることがわかりました。
OpenAI は、慎重な調整により有害な出力を削減し、良性への対応の精度を高めることで AI の安全性を向上させると述べています。
関連: ChatGPT で「停止」を押すと安全装置が無効化される仕組み
AI 開発への広範な影響
熟議的調整の導入は、OpenAI で、そしておそらく将来的には他の企業でも AI システムがどのようにトレーニングおよび展開されるかにおいて転換点を示します。
OpenAI は、明示的な安全推論をモデルの中核機能に組み込むことで、既存の課題に対処するだけでなく、将来のリスクも予測するフレームワークを作成しました。 AI システムの能力が高まるにつれて、誤用や意図しない結果が生じる可能性が高まり、堅牢な安全対策がこれまで以上に重要になっています。
熟議的な連携は、より広範な AI コミュニティのモデルとしても機能します。合成データなどのスケーラブルな技術への依存と透明性の重視は、AI システムを倫理的および社会的価値観に合わせようとしている他の組織に青写真を提供します。