頻繁ではありませんが、PDF ドキュメントから画像を抽出する必要がある状況が発生することがあります。たとえば、プレゼンテーションに取り組んでいて、研究論文からの画像が必要になる場合があります。あなたはグラフィック デザイナーで、クライアントの PDF パンフレットのロゴや画像を再利用する必要があるかもしれません。あるいは、カスタム ノートを作成している学生で、教科書の画像が必要な場合もあります。
ケースや状況が何であれ、PDF ドキュメントからすべての画像を保存するのは簡単な作業です。このチュートリアルでは、無料のオープンソース ツールである pdfcpu を使用して PDF ドキュメントから画像を抽出する方法を説明します。始めましょう。
PDF から画像を抽出する手順
Windows にはネイティブ オプションがないため、pdfcpu と呼ばれる無料のオープンソース PDF ツールを使用します。これは PDF 処理用の強力なコマンドライン ツールです。その方法は次のとおりです。
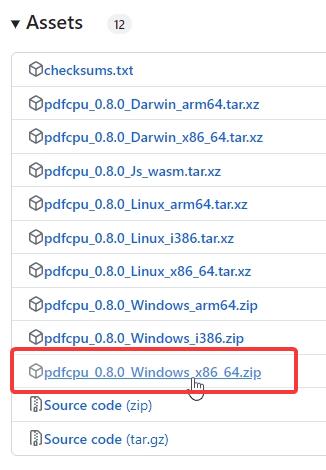
ステップ 1: pdfcpu をダウンロード
まず、公式の pdfcpu の GitHub ページ。 [アセット] セクションまで下にスクロールし、64 ビット Windows システム用の最新の「Windows_x86_64.zip」ファイルをダウンロードします。
ステップ 2: ダウンロードした pdfcpu ファイルを抽出します
ダウンロードした zip ファイルを見つけますダウンロード フォルダー内のファイルを右クリックし、[すべて展開] を選択します。
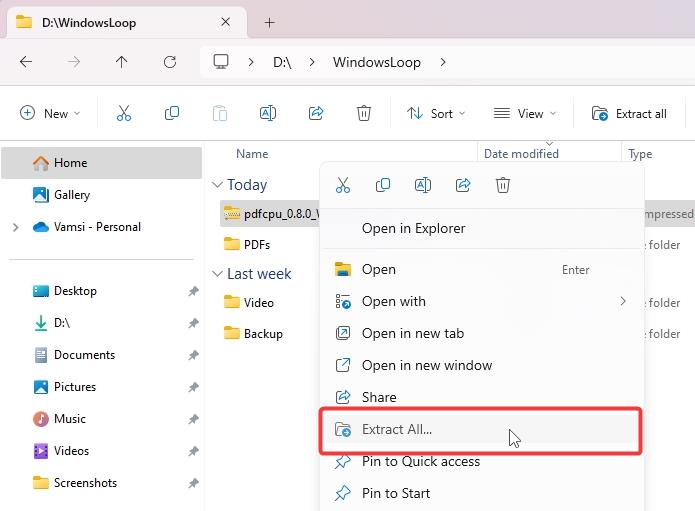
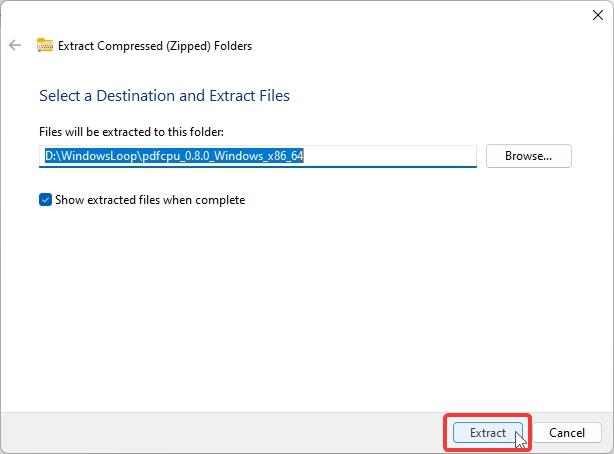
プロンプトが表示されたら、「抽出」ボタンをクリックします。これにより、zip が別のフォルダーに抽出されます。
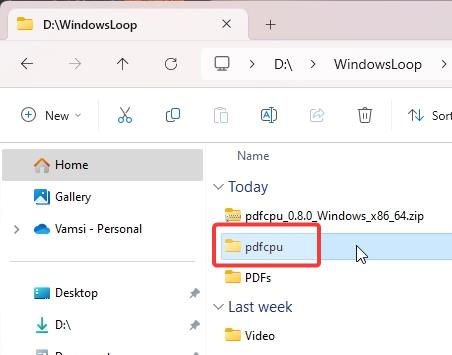
(オプション) 使いやすくするために、抽出したフォルダーの名前を「pdfcpu」に変更します。これは必須の手順ではありませんが、コマンド プロンプトでの移動が簡単になります。
ステップ 3: コマンド プロンプトを開く
スタート ボタンを押して、「コマンド プロンプト」を検索します

ステップ 4: コマンド プロンプトで pdfcpu ディレクトリに移動します
コマンド プロンプトで次のコマンドを実行して、次のコマンドを実行します。 pdfcpu ディレクトリにコピーします。ダミーのパスを実際のフォルダーのパスに置き換えてください。これにより、次のステップでコマンドを簡単に実行できます。
cd/d “C:\path\to\pdfcpu\folder”
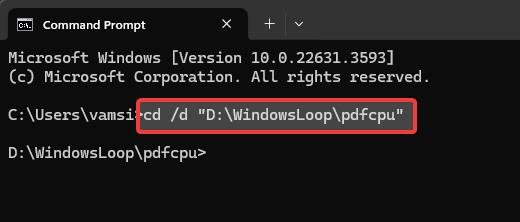
ステップ 5: 実行PDF から画像を抽出する pdfcpu コマンド
次に、次のコマンドを実行して、ダミー PDF パスとダミー出力ディレクトリ パスを実際のパスに置き換えます。
pdfcpu extract-mode image “C:\path\to\file.pdf”“C:\path\to\output\folder”
たとえば、両方のダミー パスを置き換えた後のコマンドは次のようになります。
pdfcpu extract-mode image”D:\WindowsLoop\PDFs\catalogue.pdf”
“D:\WindowsLoop\PDFs\PDF Images”
コマンドを実行するとすぐに, pdfcpu は、指定された PDF ファイルから画像を抽出し、出力ディレクトリに保存します。
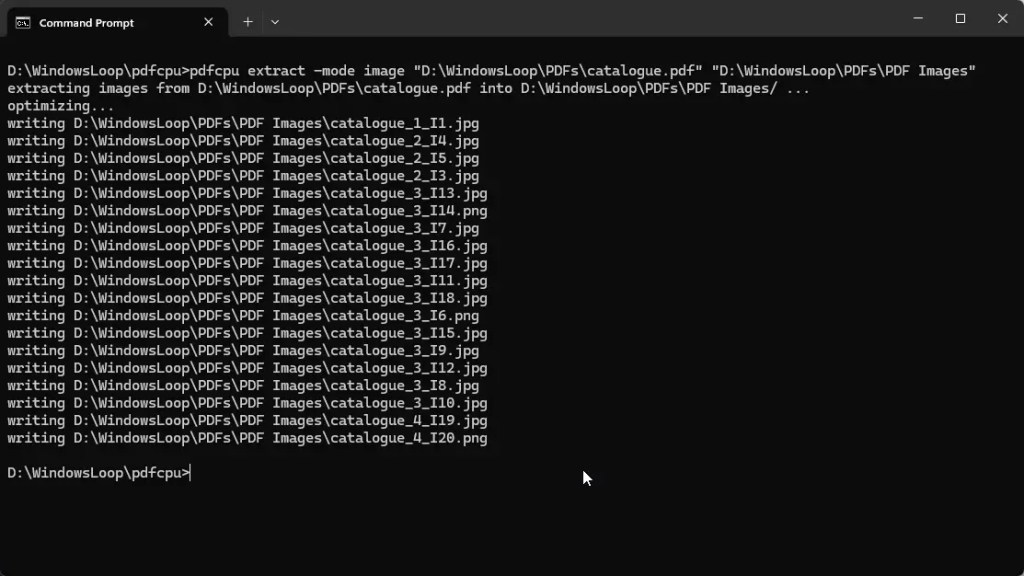
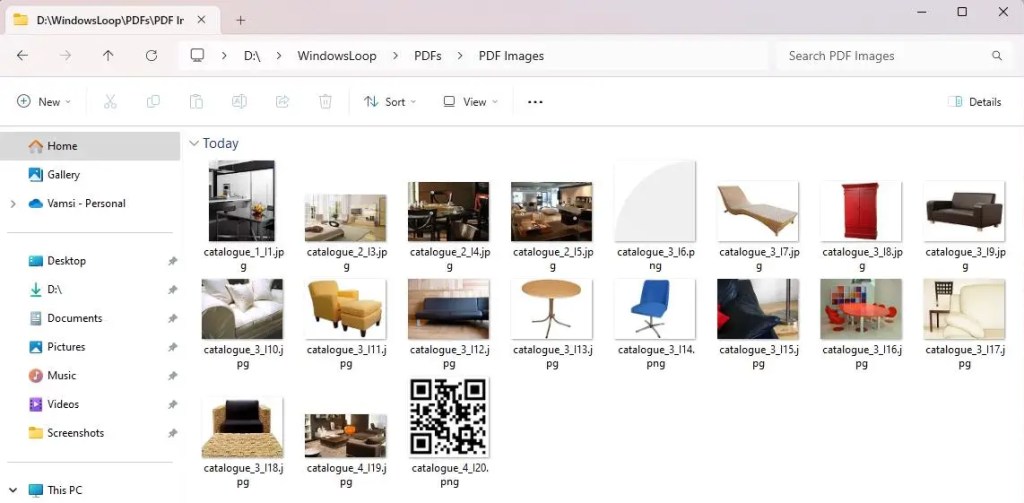
ステップ 6: 抽出された画像を確認する
抽出された画像を確認するには画像を保存するには、ファイル エクスプローラーを開き (Start + E キーを押します)、出力ディレクトリに移動します。 PDF ファイルから抽出されたすべての画像が含まれているはずです。
トラブルシューティングの手順
ここでは、pdfcpu ツールの使用中に発生する可能性のある一般的なエラーとその解決方法を示します。
エラー:’pdfcpu’は内部コマンド、外部コマンド、操作可能なプログラム、またはバッチ ファイルとして認識されません
このエラーが表示された場合は、ディレクトリ パスが次の場所にあることを確認してください。抽出した「pdfcpu」は正しく、「pdfcpu.exe」ファイルが含まれています。確認するには、エクスプローラーを開き、フォルダーに移動します。その中に pdfcpu.exe ファイルが表示されるはずです。
エラー: 指定されたパスが見つかりません
「システムは指定されたパスが見つかりません」というエラーが表示される場合」というメッセージは通常、PDF ファイルまたは出力ディレクトリのパスに問題があることを意味します。これを修正するには、次の手順に従います。
まず、PDF ファイルへのパスが正しいことを確認してください。ファイルはそこに存在します。次に、出力ディレクトリのパスが正しいかどうか、またディレクトリがすでに存在しているかどうかを確認します。「pdfcpu」では自動的に作成されないためです。
暗号化された PDF
PDF の場合画像を抽出しようとしているドキュメントは暗号化されているため、最初にそれを復号化する必要があります。復号化せずに画像を抽出しようとすると、「pdfcpu: 正しいパスワードを入力してください」というエラー メッセージが表示されます。PDF ファイルを復号化するには、次のコマンドを実行します。
pdfcpu decrypt-upw
復号化した後、チュートリアルに記載されている手順に従って画像を抽出します。
pdfcpu は画像を抽出できません
pdfcpu が PDF ファイルから画像を抽出できないシナリオは次のとおりです。
サポートされていない画像形式: 一部の PDF には、ベクター グラフィックとして埋め込まれた画像が含まれている場合があります。 (SVG など)、または pdfcpu などの PDF ツールでサポートされていない可能性がある、JBIG2 や JPEG2000 などの特殊な形式のファイル。埋め込みオブジェクト: 画像がインタラクティブ コンテンツなどの他のオブジェクトに埋め込まれている場合、マルチメディア コンテンツ、フォーム XObject、インライン イメージなど、pdfcpu はそれらを無視したり、誤って抽出したりする場合があります。
まとめ-PDF からのイメージの保存
ご覧のとおり、PDF ファイルからイメージを抽出して保存します。 pdfcpu のおかげで、思ったよりも簡単です。ツールを使用するときは、パスが正しいことと、PDF ファイルが暗号化されていないことを確認してください。エラーが発生した場合は、上記のトラブルシューティング セクションを参照してください。一般的なエラーを修正し、一般的な問題に答えるのに役立ちます。
ご質問がある場合やサポートが必要な場合は、以下にコメントしてください。お答えします。
関連チュートリアル:

