Il nuovo modello di ragionamento di DeepSeek chiamato R1 sfida le prestazioni di Openai’s Chatgpt O1, anche se si basa su GPU a valle e un budget relativamente piccolo.
In un ambiente modellato da controlli di esportazione statunitensi che limitano i chip avanzati, la startup di intelligenza artificiale cinese fondata dal gestore di hedge fund Liang Wenfeng, ha mostrato come l’efficienza e la condivisione delle risorse possano spingere in avanti lo sviluppo dell’IA.
L’ascesa dell’azienda ha catturato l’attenzione dei circoli tecnologici sia in Cina che negli Stati Uniti.
correlato : perché le sanzioni statunitensi possono lottare per frenare la crescita tecnologica della Cina
Rise rapido di Deepseek
Il viaggio di DeepSeek iniziò nel 2021, quando Liang, noto per il suo Fondo di trading quant-flyer , ha iniziato ad acquistare migliaia di GPU Nvidia.
All’epoca, questa mossa sembrava insolita. Come uno dei partner commerciali di Liang ha detto The Financial Times,”Quando lo abbiamo incontrato per la prima volta, Era questo ragazzo molto nerd con un’acconciatura terribile che parlava di costruire un cluster da 10.000 chip per addestrare i suoi modelli. Non l’abbiamo preso sul serio.”
secondo la stessa fonte,”Non poteva articolare la sua visione oltre a dire: voglio costruirlo, e sarà un cambio di gioco. Abbiamo pensato Ciò era possibile solo da giganti come Bytedance e Alibaba”.
Nonostante lo scetticismo iniziale, Liang è rimasto concentrato sulla preparazione di potenziali controlli di esportazione statunitensi. Questa lungimiranza ha consentito a DeepEek di garantire una grande scorta di hardware Nvidia, tra cui GPU A100 e H800, prima che entrassero in vigore le restrizioni di ampio. Modelli
DeepSeek ha fatto notizia rivelando che aveva addestrato il suo modello R1 da 671 miliardi di parametri per soli $ 5,6 milioni utilizzando 2.048 GPU NVIDIA H800.
Sebbene le prestazioni dell’H800 siano deliberatamente ridotte per Il mercato cinese, gli ingegneri di Deepseek hanno ottimizzato la procedura di formazione per ottenere risultati di alto livello a una frazione del costo tipicamente associato a modelli di lingua su larga scala.
in un Intervista Pubblicato da MIT Technology Review, Zihan Wang, ex ricercatore di Deepseek, descrive come il team è riuscito a ridurre l’utilizzo della memoria e le spese generali computazionali mentre si preserva la precisione.
ha affermato che i limiti tecnici li hanno spinti a esplorare nuove strategie di ingegneria, aiutandole in definitiva a rimanere competitive contro i laboratori tecnologici statunitensi meglio finanziati.
correlato : China’s’s Il modello di ragionamento di DeepSeek R1 e OpenAI O1 Contender sono fortemente censurati
Risultati eccezionali sui benchmark di matematica e codifica
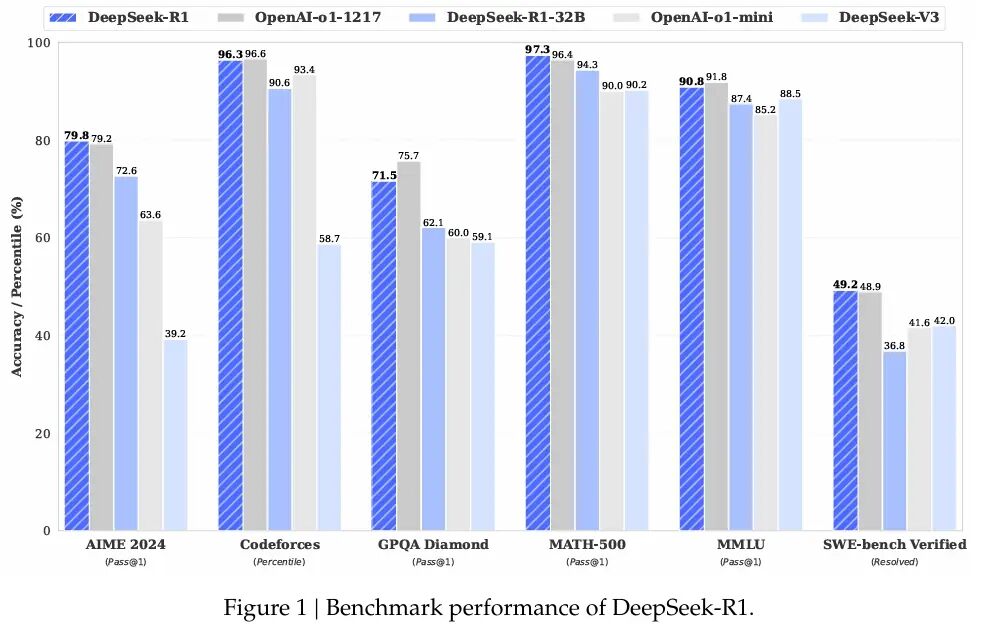
R1 dimostra eccellenti capacità attraverso vari benchmark matematici e codificanti. DeepSeek ha rivelato che R1 ha segnato il 97,3% (Pass@1) su Math-500 e il 79,8% su AIME 2024.
Questi numeri rivaleggiano sulla serie O1 di Openai, mostrando come l’ottimizzazione deliberata può sfidare i modelli addestrati su chip più potenti.
Dimitris Papailiopoulos, un ricercatore principale del laboratorio di AI Frontiers di Microsoft, ha dichiarato al MIT Technology Review:”DeepSeek mirava a risposte accurate piuttosto che in dettaglio ogni passo logico, riducendo significativamente i tempi di calcolo mantenendo un alto livello di efficacia.”
Il modello principale, DeepSeek ha rilasciato versioni più piccole di R1 che possono funzionare su hardware di livello consumer.
DeepSeek ha replicato in gran parte O1-Mini e lo ha aperto. ;/Aravsrinivas/status/188137286140503673?
Oltre all’addestramento standard di R1, DeepSeek si è avventurato nell’apprendimento di rinforzo puro con una variante chiamata R1-Zero. Questo approccio, dettagliato nella documentazione di ricerca dell’azienda, scarta la messa a punto controllata a favore dell’ottimizzazione delle politiche relative di gruppo (GRPO).
Rimuovendo un modello di critico separato e basandosi su punteggi di base raggruppati, R1-Zero ha mostrato comportamenti di ragionamento a catena e autoriflessione. Tuttavia, il team ha riconosciuto che R1-Zero ha prodotto output ripetitivi o di lingua mista, indicando la necessità di una supervisione parziale prima che potesse essere utilizzato nelle applicazioni quotidiane.
L’etica open-source dietro Deepseek lo distingue Molti laboratori proprietari. Mentre le aziende statunitensi come Openai, Meta e Google DeepMind spesso mantengono nascosti i loro metodi di formazione, DeepSeek rende disponibili il suo codice, i pesi del modello e le ricette di formazione.
correlato : debutta AI Mistral Pixtral 12b per l’elaborazione di testi e immagini
Secondo Liang, questo approccio deriva dal desiderio di costruire una cultura della ricerca che favorisce trasparenza e progresso collettivo. In un intervista Con il media cinese 36kr, ha spiegato che molte iniziative di intelligenza artificiale cinesi lottano con efficienza rispetto ai loro peer occidentali, E questo colmare questo divario richiede una collaborazione sia su strategie hardware che di formazione.
Il suo punto di vista si allinea con gli altri nella scena AI della Cina, dove le versioni open-source sono in aumento. Alibaba Cloud ha introdotto oltre 100 modelli open source e 01.AI, fondato da Kai-Fu Lee, ha recentemente collaborato con Alibaba Cloud per stabilire un laboratorio di AI industriale.
La comunità tecnologica globale ha risposto con un Mix di timore reverenziale e cautela. Su X, Marc Andreessen, co-inventore del browser Web Mosaic e ora un investitore di spicco di Andreessen Horowitz, ha scritto: “Deepseek R1 è una delle scoperte più sorprendenti e impressionanti che abbia mai visto-e come open source, una profonda fonte, profonda regalo al mondo.”
DeepSeek R1 è una delle scoperte più sorprendenti e impressionanti che abbia mai visto-e come open source, un dono profondo per il mondo. 🤖🫡
-Marc Andreessen 🇺🇸 (@pmarca) 24 gennaio 2025
Yann Lecun, capo scienziato di AI di Meta, ha osservato su LinkedIn che mentre il risultato di Deepseek potrebbe sembrare indicare che la Cina supera gli Stati Uniti, sarebbe più accurato affermare che i modelli open-source stanno raggiungendo collettivamente le alternative proprietarie.
“DeepSeek ha profitto da una ricerca aperta e open source (ad esempio Pytorch e Llama di Meta)”, ha spiegato.”Hanno inventato nuove idee e le hanno costruite sopra il lavoro di altre persone. Poiché il loro lavoro è pubblicato e open source, tutti possono trarne profitto. Questa è il potere della ricerca aperta e dell’open source.”
Visualizza su thread
Anche Mark Zuckerberg, fondatore e CEO di Meta, ha accennato a un percorso diverso annunciando enormi investimenti in data center e infrastrutture GPU > Su Facebook, ha scritto: “Questo sarà un anno determinante per l’IA.”Costruire un ingegnere AI che inizierà a contribuire con quantità crescenti di codice ai nostri sforzi di ricerca e sviluppo”Porta online ~ 1GW di calcolo nel’25 e finiremo l’anno con oltre 1,3 milioni di GPU. Capitale per continuare a investire negli anni a venire. Questo è uno sforzo enorme e nei prossimi anni guiderà i nostri prodotti principali e le nostre attività, sbloccherà l’innovazione storica ed estenderà la leadership tecnologica americana. Let’s Go Build!”
Le osservazioni di Zuckerberg suggeriscono che le strategie ad alta intensità di risorse rimangono una forza importante nel modellare il settore dell’IA.-Ciò che Meta non ti sta dicendo sui modelli”open source”
ampliamento di impatto e prospettive future
per DeepSeek, la combinazione di talenti locali, presto Lo stoccaggio della GPU e un’enfasi sui metodi open source lo hanno spinto a un riflettore tipicamente riservato ai grandi giganti della tecnologia. Nel luglio 2024, Liang dichiarò che il suo team mirava ad affrontare quello che chiamava un divario di efficienza nell’intelligenza artificiale cinese.
Ha descritto molte aziende di intelligenza artificiale locali che richiedono il doppio del potere di calcolo di abbinare i risultati all’estero, aggravandoti che ulteriormente quando l’utilizzo dei dati è preso in considerazione. Gli hedge fund dai profitti dell’alta fryer danno a DeepEek un buffer contro le pressioni commerciali immediate, permettendo a Liang e ai suoi ingegneri di concentrarsi sulle priorità di ricerca. Liang ha dichiarato:
“Stimiamo che i migliori modelli domestici e stranieri possano avere un divario di una volta nella struttura dei modelli e nelle dinamiche di allenamento. Solo per questo motivo, dobbiamo consumare il doppio della potenza di calcolo per ottenere lo stesso effetto.
Inoltre, potrebbe esserci anche un divario di un’efficienza dei dati, ovvero dobbiamo consumare il doppio dei dati di addestramento e la potenza di calcolo per ottenere lo stesso effetto. Insieme, dobbiamo consumare quattro volte più potenza di calcolo. Quello che dobbiamo fare è restringere continuamente queste lacune.”
La reputazione di Deepseek in Cina ha anche ricevuto una spinta quando Liang è diventato l’unico leader di intelligenza artificiale invitato a un incontro di alto profilo con Li Qiang, il secondo-del paese Il più potente ufficiale, in cui è stato invitato a concentrarsi sulla costruzione di tecnologie di base.
Mentre il futuro rimane incerto, specialmente in quanto le restrizioni statunitensi possono stringere ulteriormente: Deepseek si distingue per aver affrontato le sfide in modi che trasformano i vincoli in strade per la rapida risoluzione dei problemi.-Incellate di allenamento, la startup ha motivato discussioni più ampie sul fatto che l’efficienza delle risorse possa seriamente competere con cluster di supercompleting enormi. I risultati di questo modello possono aprire un percorso sostenibile per i progressi dell’IA in un’era di restrizioni in evoluzione.