Microsoft ha introdotto rStar-Math, una continuazione e un perfezionamento del suo precedente rStar framework, per ampliare i confini dei modelli linguistici piccoli (SLM) nel ragionamento matematico.
Progettato per competere con sistemi più grandi come o1-preview di OpenAI, rStar-Math raggiunge notevoli parametri di riferimento nella risoluzione dei problemi, dimostrando al tempo stesso come i modelli compatti possano funzionare a livelli competitivi. Questo sviluppo mostra un cambiamento nelle priorità dell’IA, passando dall’incremento all’ottimizzazione delle prestazioni per attività specifiche.
Avanzando da rStar a rStar-Math
The rStar quadro della scorsa estate ha gettato le basi per migliorare il ragionamento SLM attraverso Monte Carlo Tree Search (MCTS), un algoritmo che perfeziona le soluzioni simulando e convalidando più percorsi.
rStar ha dimostrato che i modelli più piccoli potevano gestire compiti complessi, ma la sua applicazione rimaneva generale. rStar-Math si basa su queste basi con innovazioni mirate su misura per il ragionamento matematico.
Un elemento centrale del successo di rStar-Math è la sua metodologia di catena di pensiero (CoT) potenziata dal codice, in cui il modello produce soluzioni in entrambi linguaggio naturale e codice eseguibile Python.
Questa struttura a doppio output garantisce che i passaggi intermedi del ragionamento siano verificabili, riducendo gli errori e mantenendo la coerenza logica. I ricercatori hanno sottolineato l’importanza di questo approccio, affermando:”La coerenza reciproca rispecchia la pratica umana comune in assenza di supervisione, dove l’accordo tra pari sulle risposte derivate suggerisce una maggiore probabilità di correttezza.”
Correlato: Il modello cinese DeepSeek R1-Lite-Preview punta al vantaggio di OpenAI nel ragionamento automatizzato
Oltre a CoT, rStar-Math introduce un modello di preferenza di processo (PPM), che valuta e classifica i passaggi intermedi in base alla qualità. A differenza dei tradizionali sistemi di ricompensa che spesso si basano su dati rumorosi, il PPM dà priorità alla coerenza logica e all’accuratezza, migliorando ulteriormente l’affidabilità del modello. I ricercatori scrivono:
“Il PPM sfrutta il fatto che, sebbene i valori Q non siano ancora sufficientemente precisi per valutare ogni passaggio del ragionamento nonostante l’utilizzo di ampie implementazioni MCTS, i valori Q possono distinguere in modo affidabile i passaggi positivi (corretti) da quelli negativi (irrilevanti/errati)
Pertanto, il metodo di training costruisce coppie di preferenze per ogni passaggio in base ai valori Q e utilizza una perdita di ranking a coppie per ottimizzare la previsione del punteggio PPM per ogni passaggio di ragionamento, ottenendo un’etichettatura affidabile. Questo approccio evita i metodi convenzionali che utilizzano direttamente i valori Q come etichette di ricompensa, che sono intrinsecamente rumorosi e imprecisi nell’assegnazione graduale della ricompensa.”
Infine, una ricetta di autoevoluzione in quattro round che costruisce progressivamente sia una frontiera modello di policy e PPM da zero.
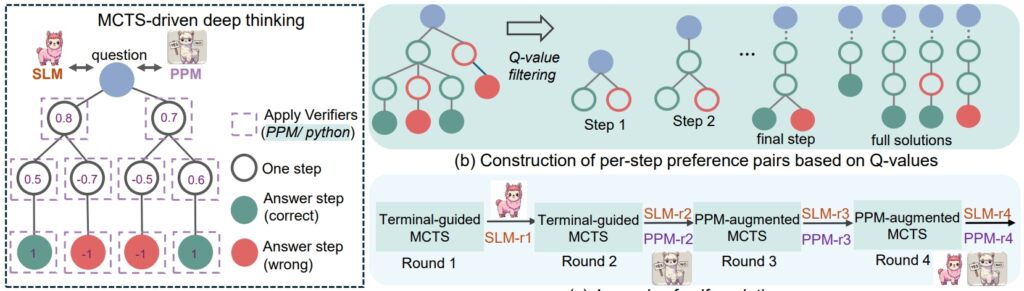 Procedura di ragionamento rSTar-Math (Fonte: documento di ricerca)
Procedura di ragionamento rSTar-Math (Fonte: documento di ricerca)
Prestazioni che mettono alla prova i modelli più grandi
rStar-Math stabilisce nuovi standard nei benchmark del ragionamento matematico, ottenendo risultati che competono, e in alcuni casi superano, quelli dei sistemi IA più grandi
Sul set di dati GSM8K, un test per il ragionamento matematico, la precisione di un modello da 7 miliardi di parametri è migliorata dal 12,51% al 63,91% dopo aver integrato rStar-Math nel American Invitational Mathematics Examination (AIME), il modello ha risolto il 53,3% dei problemi, collocandolo tra il 20% dei migliori partecipanti alle scuole superiori.
I risultati del set di dati MATH sono stati altrettanto impressionanti, con rStar-Math che ha raggiunto un tasso di precisione del 90%, superando o1-preview di OpenAI.
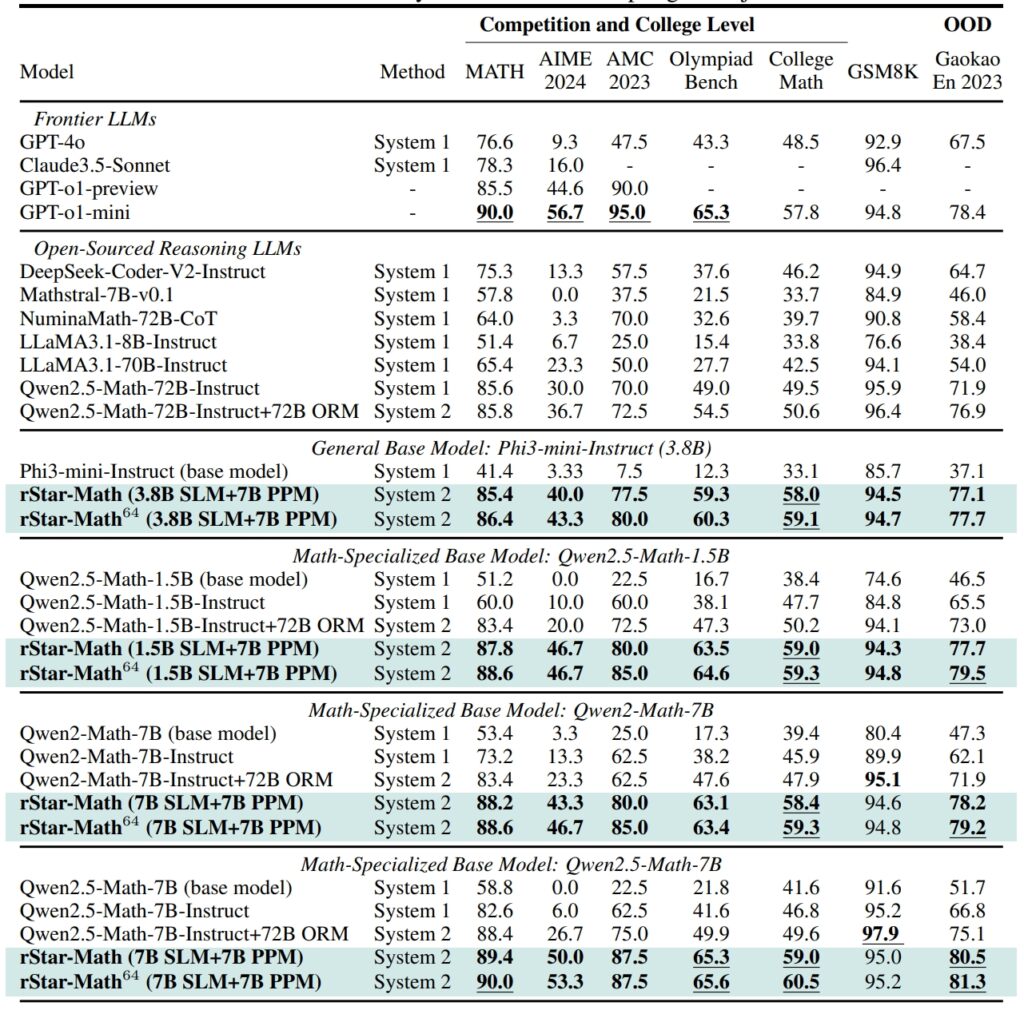 Prestazioni di rStar-Math e altri LLM di frontiera nella maggior parte dei casi benchmark matematici impegnativi (Fonte: documento di ricerca)
Prestazioni di rStar-Math e altri LLM di frontiera nella maggior parte dei casi benchmark matematici impegnativi (Fonte: documento di ricerca)
Questi risultati evidenziano la capacità del quadro di consentire agli SLM di gestire attività precedentemente dominate da modelli di grandi dimensioni ad alta intensità di risorse. Sottolineando la coerenza logica e i passaggi intermedi verificabili, rStar-Math affronta una delle sfide più persistenti dell’intelligenza artificiale: garantire un ragionamento affidabile in spazi problematici complessi.
Innovazioni tecniche che guidano rStar-Math
L’evoluzione da rStar a rStar-Math introduce diversi progressi chiave. L’integrazione di MCTS rimane centrale nel quadro, consentendo al modello di esplorare diversi percorsi di ragionamento e dare priorità a quelli più promettenti.
L’aggiunta del ragionamento CoT, incentrato sulla verifica del codice, garantisce che i risultati siano interpretabili e accurati.
Correlato: QwQ-32B di Alibaba-Preview si unisce alla battaglia sul ragionamento del modello AI con OpenAI
Forse la cosa più trasformativa è il processo di formazione autoevolutiva di rStar-Math. Nel corso di quattro cicli iterativi, il quadro perfeziona il suo modello politico e il PPM, incorporando dati di ragionamento di qualità superiore in ogni fase.
Questo approccio iterativo consente al modello di migliorare continuamente le sue prestazioni, ottenendo risultati all’avanguardia senza fare affidamento sulla distillazione di modelli più grandi.
Confronto tra rStar-Math all’o1 di OpenAI
Mentre Microsoft si concentra sull’ottimizzazione dei modelli più piccoli, OpenAI continua a dare priorità all’ampliamento dei propri sistemi.
La modalità o1 Pro, introdotta nel dicembre 2024 come parte del piano ChatGPT Pro, offre funzionalità di ragionamento avanzate su misura per applicazioni ad alto rischio come la codifica e la ricerca scientifica. OpenAI ha riferito che o1 Pro Mode ha raggiunto un tasso di precisione dell’86% su AIME e un tasso di successo del 90% nei benchmark di codifica come Codeforces.
rStar-Math rappresenta un cambiamento nell’innovazione dell’intelligenza artificiale, sfidando l’attenzione del settore su modelli più grandi come mezzo principale per raggiungere un ragionamento avanzato. Migliorando gli SLM con ottimizzazioni specifiche del dominio, Microsoft offre un’alternativa sostenibile che riduce i costi computazionali e l’impatto ambientale.
Correlato: Allineamento deliberativo: la strategia di sicurezza di OpenAI per i suoi modelli di pensiero o1 e o3
Il successo del framework nel ragionamento matematico apre le porte ad applicazioni più ampie, dall’istruzione alla ricerca scientifica.
I ricercatori intendono rilasciare il codice e i dati di rStar-Math su GitHub, aprendo la strada a ulteriore collaborazione e sviluppo. Questa trasparenza riflette l’approccio di Microsoft volto a rendere gli strumenti di intelligenza artificiale ad alte prestazioni accessibili a un pubblico più ampio, comprese le istituzioni accademiche e le organizzazioni di medie dimensioni.
Correlato: SemiAnalysis: No, AI Scaling Isn non rallentare
Con l’intensificarsi della concorrenza tra Microsoft e OpenAI, i progressi introdotti da rStar-Math evidenziano il potenziale dei modelli più piccoli per sfidare il dominio dei sistemi più grandi. Dando priorità all’efficienza e alla precisione, rStar-Math stabilisce un nuovo punto di riferimento per ciò che i sistemi IA compatti possono ottenere.