Il team di ricerca Qwen di Alibaba ha introdotto QVQ-72B, un modello di intelligenza artificiale multimodale open source progettato per combinare ragionamento visivo e testuale. Con la sua capacità di elaborare immagini e testo passo dopo passo, il modello offre un nuovo approccio alla risoluzione dei problemi che sfida il predominio di sistemi proprietari come GPT-4 di OpenAI.
Il team Qwen di Alibaba descrive QVQ-72B come un passo verso il loro obiettivo a lungo termine di creare un’intelligenza artificiale più completa in grado di affrontare sfide scientifiche e analitiche.
Rendendo il modello apertamente disponibile con la licenza Qwen, Alibaba mira a promuovere la collaborazione nella comunità dell’intelligenza artificiale, promuovendo al contempo lo sviluppo dell’intelligenza generale artificiale (AGI). Posizionato sia come strumento di ricerca che come applicazione pratica, QVQ-72B rappresenta una nuova pietra miliare nell’evoluzione dell’intelligenza artificiale multimodale.
Visivo e testuale Ragionamento
I modelli di intelligenza artificiale multimodale come QVQ-72B sono progettati per analizzare e integrare più tipi di input, visivi e testuali, in un processo di ragionamento coeso. Questa funzionalità è particolarmente utile per attività che richiedono l’interpretazione di dati in diversi formati, come ricerca scientifica, istruzione e analisi avanzata.
Sostanzialmente, QVQ-72B è un’estensione di Qwen2-VL-72B, il precedente modello di linguaggio visivo di Alibaba. Introduce funzionalità di ragionamento avanzate che gli consentono di elaborare immagini e relativi suggerimenti testuali con un approccio logico e strutturato. A differenza di molti sistemi closed-source, QVQ-72B è progettato per essere trasparente e accessibile, fornendo il codice sorgente e i pesi del modello a sviluppatori e ricercatori.
“Immagina un’intelligenza artificiale in grado di esaminare un problema di fisica complesso, e ragionare metodicamente verso una soluzione con la sicurezza di un esperto fisico,”il team di Qwen descrive le sue ambizioni con il nuovo modello di eccellere nei settori in cui il ragionamento e la comprensione multimodale sono fondamentali.
Prestazioni e benchmark
Le prestazioni del modello sono state valutate utilizzando diversi benchmark rigorosi, ciascuno dei quali ha testato aspetti diversi delle sue capacità di ragionamento multimodale:
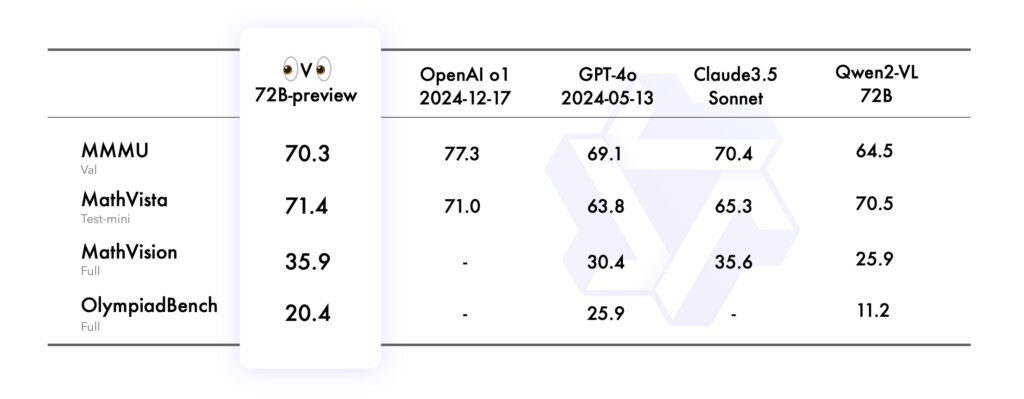
Nel MMMU (Multimodal Multidisciplinary University), che ne ha valutato la capacità di operare a livello universitario, combinando ragionamento basato su testo e immagini, QVQ-72B ha ottenuto un punteggio impressionante di 70,3, superando il suo predecessore Qwen2-VL-72B-Instruct.
Il benchmark MathVista ha testato la competenza del modello nella risoluzione di problemi matematici utilizzando grafici e ausili visivi, evidenziandone i punti di forza analitici. Allo stesso modo, MathVision, derivato da competizioni matematiche del mondo reale, ha valutato la sua capacità di ragionamento in diversi domini matematici.
Infine, il benchmark OlympiadBench ha sfidato QVQ-72B con problemi bilingui provenienti da concorsi internazionali di matematica e fisica. Il modello ha dimostrato un’accuratezza paragonabile a quella dei sistemi proprietari come GPT-4 di OpenAI, riducendo il divario prestazionale tra l’intelligenza artificiale open source e quella closed source.
 Fonte: Qwen
Fonte: Qwen
Nonostante questi risultati, permangono delle limitazioni. Il team di Qwen ha notato che i cicli di ragionamento ricorsivi e le allucinazioni durante l’analisi visiva complessa rimangono sfide che devono essere affrontate.
Applicazioni pratiche e strumenti di sviluppo
QVQ-72B non è solo un oggetto di ricerca: è uno strumento accessibile per gli sviluppatori, ospitato su Hugging Face Spaces, consentendo agli utenti di sperimentare le sue capacità in tempo reale. Gli sviluppatori possono anche distribuire QVQ-72B localmente utilizzando framework come MLX, ottimizzato per ambienti macOS e Hugging Face Transformers, rendendo il modello versatile su tutte le piattaforme.
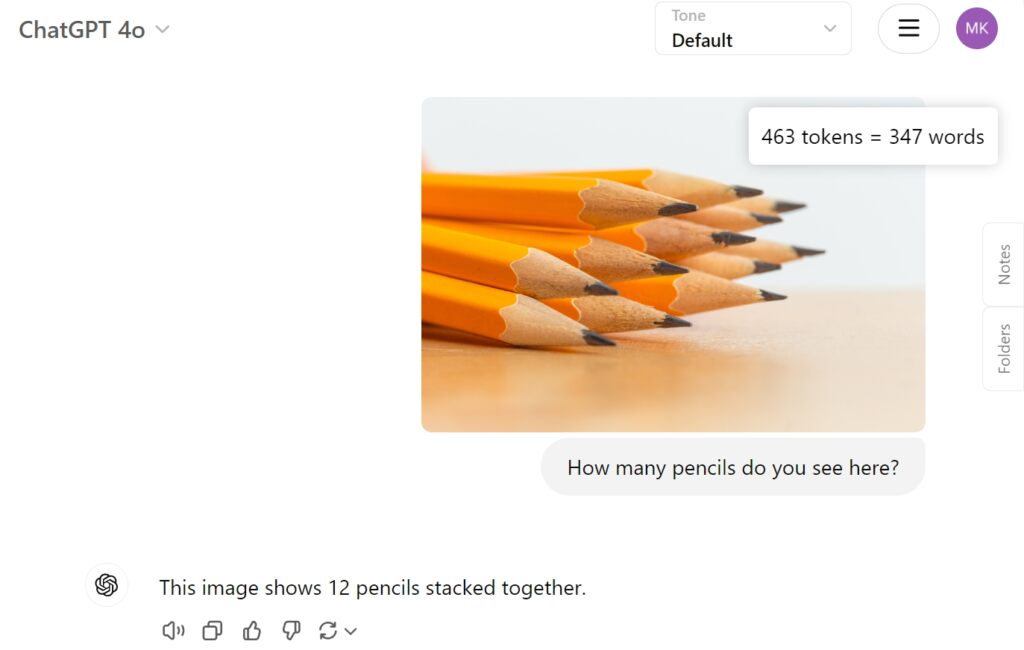
Abbiamo testato l’anteprima di QVQ-72B su Hugging Face con una semplice immagine di dodici matite per vedere come affronterebbe il compito e se riesce a identificare correttamente le matite impilate insieme. Sfortunatamente ha fallito questo semplice compito, ottenendo solo otto.

Come confronto, GPT-4o di OpenAI ha fornito direttamente la risposta corretta:
Affrontare le sfide e le direzioni future
Sebbene QVQ-72B rappresenti un progresso, evidenzia anche le complessità del progresso dell’IA multimodale. Problemi come il cambio di lingua, le allucinazioni e i cicli di ragionamento ricorsivi illustrano le sfide legate allo sviluppo di sistemi robusti e affidabili. L’identificazione di oggetti separati, che è fondamentale per un corretto conteggio e il successivo ragionamento, rimane ancora un problema per il modello.
Tuttavia, l’obiettivo a lungo termine di Qwen va oltre QVQ-72B. Il team immagina un modello unificato che integri modalità aggiuntive, combinando testo, visione, audio e altro, per avvicinarsi all’intelligenza artificiale generale. Sottolineano che QVQ-72B rappresenta un passo verso questa visione, fornendo una piattaforma aperta per ulteriori esplorazioni e innovazioni.