Google DeepMind ha lanciato FACTS Grounding, un nuovo benchmark progettato per testare i modelli linguistici di grandi dimensioni (LLM) sulla loro capacità di generare risposte basate su documenti accurate e basate sui fatti.
Il benchmark, ospitato su Kaggle, mira ad affrontare una delle sfide più urgenti in intelligenza artificiale: garantire che i risultati dell’intelligenza artificiale siano fondati sui dati forniti, piuttosto che fare affidamento su conoscenze esterne o introdurre allucinazioni, informazioni plausibili ma errate.
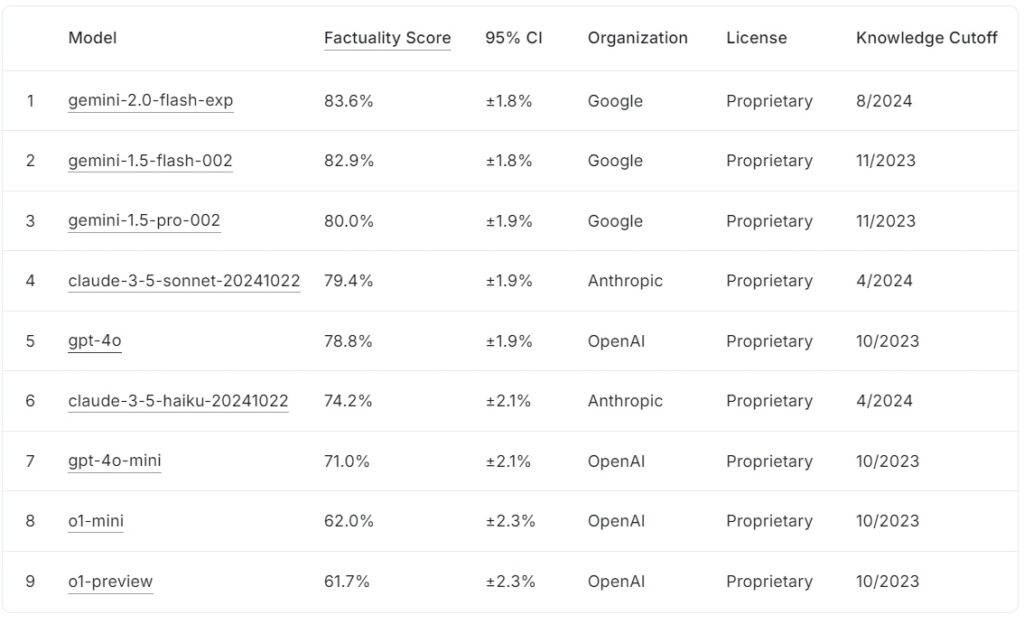
L’attuale classifica FACTS Grounding classifica i modelli linguistici di grandi dimensioni in base ai loro punteggi di fattualità, con quelli di Google gemini-2.0-flash-exp in testa all’83,6% seguito da vicino da gemini-1.5-flash-002 all’82,9% e gemini-1.5-pro-002 all’80,0%.
claude-3.5-sonnet-20241022 di Anthropic è al quarto posto con il 79,4%, mentre OpenAI gpt-4o raggiunge il 78,8%, posizionandosi al quinto posto. Più in basso nella lista, claude-3.5-haiku-20241022 di Anthropic ottiene un punteggio del 74,2%, seguito da gpt-4o-mini al 71,0%.
I modelli più piccoli di OpenAI, o1-mini e o1-preview, completano la classifica con 62,0% e 61,7%, rispettivamente.
 Fonte: Kaggle
Fonte: Kaggle
FACTS Grounding si distingue perché richiede risposte di lunga durata che sintetizzano documenti di input dettagliati, rendendolo uno dei metodi più rigorosi parametri di riferimento per Fattualità dell’intelligenza artificiale fino ad oggi.
FACTS Il grounding rappresenta uno sviluppo fondamentale per il settore dell’intelligenza artificiale, in particolare nelle applicazioni in cui la fiducia e l’accuratezza sono essenziali. Valutando gli LLM in settori quali medicina, diritto, finanza, vendita al dettaglio e tecnologia, il benchmark pone le basi per una migliore affidabilità dell’intelligenza artificiale negli scenari del mondo reale.
Secondo il gruppo di ricerca di DeepMind, il”benchmark misura la capacità dei LLM di generare risposte basate esclusivamente sul contesto fornito… anche quando il contesto è in conflitto con la conoscenza pre-formazione.”
Set di dati per la complessità del mondo reale
FACTS Grounding è costituito da 1.719 esempi, curati da annotatori umani per garantire rilevanza e diversità da cui sono tratti questi esempi documenti dettagliati che coprono fino a 32.000 token, equivalenti a circa 20.000 parole.
Ogni attività sfida i LLM a eseguire riepiloghi, generazione di domande e risposte o riscrittura dei contenuti, con istruzioni rigorose per fare riferimento solo ai dati forniti compiti che richiedono creatività, ragionamento matematico o interpretazione esperta, concentrandosi invece sul test della capacità di un modello di sintetizzare e articolare informazioni complesse.
Per mantenere la trasparenza e prevenire l’adattamento eccessivo, DeepMind ha suddiviso il set di dati in due segmenti: 860 esempi pubblici disponibili per uso esterno e 859 esempi privati riservati per le valutazioni della classifica.
Questa doppia struttura salvaguarda l’integrità del benchmark incoraggiando al tempo stesso la collaborazione da parte degli sviluppatori di intelligenza artificiale di tutto il mondo.”Valutiamo rigorosamente i nostri valutatori automatici sui dati dei test disponibili per convalidare le loro prestazioni nel nostro compito”, osserva il team di ricerca, evidenziando l’attenta progettazione che è alla base di FACTS Grounding.
Giudicare l’accuratezza con i pari Modelli AI
A differenza dei benchmark convenzionali, FACTS Grounding utilizza un processo di revisione tra pari che coinvolge tre LLM avanzati: Gemini 1.5 Pro, GPT-4o e Claude 3.5 Sonetto. Questi modelli fungono da giudici, assegnando un punteggio alle risposte in base a due criteri critici: ammissibilità e accuratezza fattuale.
Le risposte devono prima superare un controllo di idoneità per confermare che rispondano in modo significativo alla domanda dell’utente poi valutati in base alla loro base nel materiale originale, con punteggi aggregati tra i tre modelli per ridurre al minimo i pregiudizi.
I ricercatori di DeepMind sottolineano l’importanza di questa valutazione a più livelli, affermando: “Le metriche incentrate sulla valutazione della fattualità del testo generato… possono essere aggirate ignorando l’intento dietro la richiesta dell’utente. Fornendo risposte più brevi che eludono la trasmissione di informazioni complete… è possibile ottenere un punteggio elevato di fattualità senza fornire una risposta utile.”
L’uso di più modelli di punteggio, inclusi approcci a livello di span e basati su JSON , garantisce ulteriormente l’allineamento con il giudizio umano e l’adattabilità a diversi compiti.
Affrontare la sfida delle allucinazioni legate all’intelligenza artificiale
Le allucinazioni legate all’intelligenza artificiale sono tra gli ostacoli più significativi alla diffusione adozione di LLM in campi critici. Questi errori, in cui i modelli generano risultati che appaiono plausibili ma di fatto errati, pongono seri rischi in settori come l’assistenza sanitaria, l’analisi legale e il reporting finanziario.
FATTI Grounding affronta direttamente questo problema applicando una rigorosa aderenza ai dati di input forniti, questo approccio non solo valuta la capacità di un modello di evitare l’introduzione di falsità, ma garantisce anche che gli output rimangano allineati con le intenzioni dell’utente.
A differenza di benchmark come. SimpleQA di OpenAI, che misura la fattualità nell’addestramento al recupero dei dati, FACTS Grounding verifica la capacità dei modelli di sintetizzare nuove informazioni.
Il documento di ricerca sottolinea questa distinzione: “Garantire l’accuratezza fattuale durante la generazione di risposte LLM è impegnativo. Le principali sfide nella fattualità LLM sono la modellazione (ovvero architettura, formazione e inferenza) e la misurazione (ovvero metodologia di valutazione, dati e metriche).”
Sfide tecniche e progettazione di benchmark
La complessità degli input di lunga durata introduce sfide tecniche uniche, in particolare nella progettazione di metodi di valutazione automatizzati in grado di valutare accuratamente tali risposte.
FATTI su cui si basa Grounding processi computazionalmente intensivi per convalidare le risposte, utilizzando criteri rigorosi per garantire l’affidabilità. L’inclusione di modelli di giudici multipli mitiga potenziali pregiudizi e rafforza il quadro di valutazione generale.
Il team di ricerca sottolinea l’importanza di squalificare risposte vaghe o irrilevanti. sottolineando:”La squalifica delle risposte non idonee porta a una riduzione… poiché queste risposte vengono trattate come imprecise.”
Questa rigorosa applicazione della pertinenza garantisce che i modelli non vengano ricompensati per aver eluso lo spirito del compito.
Incoraggiare la collaborazione attraverso la trasparenza
La decisione di DeepMind di ospitare FACTS Grounding su Kaggle riflette il suo impegno nel promuovere la collaborazione nel settore dell’intelligenza artificiale. Rendendo accessibile il segmento pubblico del set di dati, il progetto invita i ricercatori e gli sviluppatori di intelligenza artificiale a valutare i loro modelli rispetto a uno standard solido e a contribuire a far avanzare i parametri di fattualità.
Questo approccio è in linea con gli obiettivi più ampi di trasparenza e progresso condiviso nell’intelligenza artificiale, garantendo che i miglioramenti in termini di precisione e radicamento non siano limitati a una singola organizzazione.
Differenziarsi dagli altri Benchmark
FATTI Il Grounding si distingue dagli altri benchmark per la sua attenzione al radicamento in input appena introdotti piuttosto che in conoscenze pre-addestrate.
Mentre benchmark come SimpleQA di OpenAI valutano la capacità di un modello di recuperare e utilizzare le informazioni dal suo corpus di addestramento, FACTS Grounding valuta i modelli in base alla loro capacità di sintetizzare e articolare risposte basate esclusivamente sui dati forniti.
Questa distinzione è fondamentale per affrontare le sfide poste dai preconcetti del modello o dai pregiudizi intrinseci. Isolando il compito di elaborare input esterni, FACTS Grounding garantisce che i parametri prestazionali riflettano la capacità di un modello di operare in scenari dinamici e reali piuttosto che semplicemente rigurgitare informazioni pre-appresi.
Come spiega DeepMind nel suo documento di ricerca, il benchmark è progettato per valutare gli LLM sulla loro capacità di gestire query complesse e di lunga durata con basi fattuali, simulando attività rilevanti per le applicazioni del mondo reale.
Metodi alternativi per il grounding LLM
Diversi metodi offrono funzionalità di grounding simili al FACTS Grounding, ciascuno con i suoi punti di forza e di debolezza. Questi metodi mirano a migliorare i risultati del LLM migliorando l’accesso a informazioni accurate o perfezionando i processi di formazione e allineamento.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) migliora la precisione degli output LLM recuperando dinamicamente le informazioni pertinenti da basi di conoscenza o database esterni e incorporandoli nelle risposte del modello. Invece di riqualificare l’intero LLM, RAG funziona intercettando le richieste degli utenti e arricchendole con informazioni aggiornate.
Le implementazioni RAG avanzate spesso sfruttano il recupero basato su entità, in cui i dati associati a entità specifiche vengono unificati fornire un contesto altamente pertinente per le risposte LLM.
RAG utilizza in genere tecniche di ricerca semantica per recuperare informazioni. I documenti o i loro frammenti vengono indicizzati in base ai loro incorporamenti semantici, consentendo al sistema di abbinare la query dell’utente con le voci contestualmente più rilevanti. Questo approccio garantisce che i LLM generino risposte informate sui dati più recenti e pertinenti.
L’efficacia di RAG dipende in larga misura dalla qualità e dall’organizzazione della base di conoscenza, nonché dalla precisione degli algoritmi di recupero. Mentre FACTS Grounding valuta la capacità di un LLM di rimanere ancorato a un documento di contesto fornito, RAG lo integra consentendo ai LLM di estendere le proprie conoscenze in modo dinamico, attingendo da fonti esterne per migliorare la fattualità e la pertinenza.
Distillazione della conoscenza
La distillazione della conoscenza implica il trasferimento le capacità di un modello ampio e complesso (denominato insegnante) a un modello più piccolo e specifico per un compito (lo studente). Questo metodo migliora l’efficienza pur mantenendo gran parte della precisione del modello originale. Nella distillazione della conoscenza vengono utilizzati due approcci principali:
Distillazione della conoscenza basata sulla risposta: si concentra sulla replica degli output del modello dell’insegnante, garantendo che il modello dello studente produca risultati simili per determinati input.
Distillazione della conoscenza basata sulle funzionalità: estrae rappresentazioni e funzionalità interne dal modello dell’insegnante, consentendo al modello dello studente di replicare approfondimenti più profondi.
Perfezionando modelli più piccoli , conoscenza la distillazione consente l’implementazione di LLM in ambienti con risorse limitate senza perdite significative di prestazioni. A differenza di FACTS Grounding, che valuta la fedeltà del grounding, la distillazione della conoscenza è più interessata a scalare le capacità LLM e a ottimizzarle per attività specifiche.
Perfezionamento con set di dati Grounded
La messa a punto implica l’adattamento di LLM pre-addestrati a specifici domini o attività formandoli su set di dati selezionati in cui la base fattuale è fondamentale. Ad esempio, i set di dati che comprendono letteratura scientifica o documenti storici possono essere utilizzati per migliorare la capacità del modello di produrre risultati accurati e specifici per dominio. Questa tecnica migliora le prestazioni LLM per applicazioni specializzate, come l’analisi di documenti medici o legali.
Tuttavia, la messa a punto richiede molte risorse e rischia un dimenticatoio catastrofico, in cui il modello perde la conoscenza acquisita durante la sua formazione iniziale. FATTI Il grounding si concentra sulla verifica della fattualità in contesti isolati, mentre il fine tuning cerca di migliorare le prestazioni di base degli LLM in aree specifiche.
Apprendimento per rinforzo con feedback umano (RLHF)
L’apprendimento per rinforzo con feedback umano (RLHF) incorpora l’apprendimento umano preferenze nel processo formativo dei LLM. Addestrando in modo iterativo il modello per allineare le sue risposte con il feedback umano, RLHF affina la qualità, la fattualità e l’utilità dei risultati. I valutatori umani valutano i risultati del LLM e questi punteggi vengono utilizzati come segnali per ottimizzare il modello.
RLHF ha avuto particolare successo nel migliorare la soddisfazione degli utenti e nel garantire che le risposte generate siano in linea con le aspettative umane. Mentre FACTS Grounding valuta la base fattuale rispetto a documenti specifici, RLHF enfatizza l’allineamento dei risultati LLM con i valori e le preferenze umane.
Seguire le istruzioni e apprendimento nel contesto
Il seguito delle istruzioni e l’apprendimento in contesto implicano la dimostrazione delle basi dei LLM attraverso esempi attentamente realizzati all’interno del prompt dell’utente. Questi metodi si basano sulla capacità del modello di generalizzare da una dimostrazione di pochi scatti. Sebbene questo approccio possa produrre rapidi miglioramenti, potrebbe non raggiungere lo stesso livello di qualità di base dei metodi di perfezionamento o basati sul recupero.
Strumenti e API esterni
I LLM possono essere integrati con strumenti e API esterni per fornire accesso in tempo reale a dati esterni, migliorando significativamente le loro capacità di base. Gli esempi includono:
Funzionalità di navigazione: consente ai LLM di accedere e recuperare informazioni in tempo reale dal Web per rispondere a domande specifiche o aggiornare le proprie conoscenze.
Chiamate API: consente ai LLM di interagire con database o servizi strutturati, arricchendo le risposte con informazioni precise e aggiornate.
Questi strumenti espandono l’utilità dei LLM collegandoli a realtà-fonti di conoscenza mondiale, in miglioramento la loro capacità di generare risultati accurati e fondati. Mentre FACTS Grounding valuta la fedeltà del grounding interno, gli strumenti esterni forniscono un mezzo alternativo per estendere e verificare la fattualità.
Munding del modello open source Opzioni
Sono disponibili diverse implementazioni open source per i metodi di messa a terra alternativi discussi sopra:
Implicazioni per applicazioni ad alto rischio
L’importanza di risposte IA precise e fondate diventa particolarmente evidente nelle applicazioni ad alto rischio, come la diagnostica medica , revisioni legali e analisi finanziarie. In questi contesti, anche piccole imprecisioni possono portare a conseguenze significative, rendendo l’affidabilità dei risultati generati dall’IA un requisito non negoziabile.
L’enfasi di FACTS Grounding sulla fattualità e l’aderenza al materiale di partenza garantisce che i modelli siano testati in condizioni che rispecchiano da vicino le richieste del mondo reale.
Ad esempio, in contesti medici, un LLM incaricato di il riepilogo delle cartelle cliniche dei pazienti deve evitare di introdurre errori che potrebbero disinformare le decisioni terapeutiche. Allo stesso modo, in ambito giuridico, la produzione di sintesi o analisi della giurisprudenza richiede una base precisa nei documenti forniti.
FACTS Grounding non solo valuta i modelli in base alla loro capacità di soddisfare questi severi requisiti, ma stabilisce anche un punto di riferimento a cui gli sviluppatori possono puntare nella creazione di sistemi adatti a tali applicazioni.
Espansione il set di dati FACTS e le direzioni future
DeepMind ha posizionato FACTS Grounding come un”punto di riferimento vivente”, che si evolverà insieme ai progressi nell’intelligenza artificiale. È probabile che gli aggiornamenti futuri espanderanno il set di dati per includere nuovi domini e tipi di attività, garantendone la continua rilevanza man mano che le capacità LLM crescono.
Inoltre, l’introduzione di modelli di valutazione più diversificati potrebbe migliorare ulteriormente la robustezza del processo di punteggio, affrontando casi limite e riducendo i pregiudizi residui.
Come riconosce il team di ricerca di DeepMind, nessun benchmark può incapsulare completamente le complessità delle applicazioni del mondo reale. Tuttavia, ripetendo FACTS Grounding e coinvolgendo la più ampia comunità di intelligenza artificiale, il progetto mira a migliorare il limite alla fattualità e al radicamento nei sistemi di intelligenza artificiale.
Come afferma il team di DeepMind,”La fattualità e il radicamento sono tra i fattori chiave che daranno forma al futuro successo e all’utilità dei LLM e dei sistemi di intelligenza artificiale più ampi, e miriamo a far crescere e iterare FACTS Grounding man mano che il campo progredisce, alzando continuamente l’asticella.”