TL;DR
Il succo: Google Research ha presentato Titans, una nuova architettura neurale che utilizza l’addestramento in fase di test per consentire ai modelli di apprendere e memorizzare i dati in tempo reale durante l’inferenza. Specifiche principali: l’architettura raggiunge un richiamo efficace in finestre di contesto superiori a 2 milioni di token, superando significativamente GPT-4 sul benchmark BABILong per le attività di recupero. Perché è importante: Titans risolve il catastrofico oblio delle reti neurali ricorrenti (RNN) e i costi quadratici dei trasformatori aggiornando attivamente i parametri per ridurre al minimo le sorprese nei nuovi dati. Il compromesso: pur essendo più pesante dal punto di vista computazionale rispetto ai modelli di inferenza statici come IBM Granite, Titans offre un’espressività superiore per attività complesse come la scoperta legale o l’analisi genomica.
Google Research ha svelato“Titans”, una nuova architettura neurale che sfida la rigidità fondamentale degli attuali modelli di intelligenza artificiale consentendo loro di”imparare a memorizzare”in tempo reale durante l’inferenza.
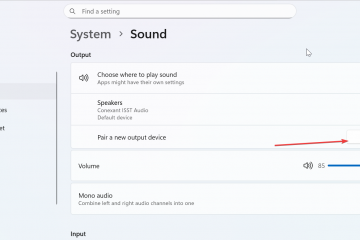
A differenza dei tradizionali Transformer che si basano su pesi statici o ricorrenti Reti neurali (RNN) che utilizzano il decadimento a stato fisso, Titans utilizza un modulo”Memoria neurale”. Questo componente aggiorna attivamente i propri parametri man mano che entrano i flussi di dati, trattando efficacemente la finestra di contesto come un ciclo di addestramento continuo anziché un buffer statico.
Dimostrazione di un richiamo efficace nel contesto windows che superano i 2 milioni di token, l’architettura supera significativamente GPT-4 sul benchmark BABILong. Questo test”dell’ago nel pagliaio”sfida i modelli a recuperare punti dati specifici da documenti estesi, un compito in cui i modelli standard spesso falliscono.
Promo
Il cambiamento del paradigma della”memoria neurale”
Le attuali architetture di intelligenza artificiale si trovano ad affrontare un compromesso fondamentale tra lunghezza del contesto ed efficienza computazionale. Transformers, l’architettura dominante dietro modelli come GPT-4 e Claude, si basa su un meccanismo di attenzione che si ridimensiona quadraticamente con la lunghezza della sequenza. Ciò rende i contesti estremamente lunghi computazionalmente proibitivi.
Al contrario, gli RNN lineari come Mamba comprimono il contesto in un vettore a stato fisso. Sebbene ciò consenta una lunghezza infinita, spesso si traduce in un”dimenticamento catastrofico”poiché i nuovi dati sovrascrivono le vecchie informazioni. Titans introduce un terzo percorso:”Test-Time Training”(TTT).
Invece di congelare i pesi del modello dopo la fase di training iniziale, l’architettura di Titans consente al modulo di memoria di continuare ad apprendere durante l’inferenza. Trattando la finestra di contesto come un set di dati, il modello esegue un ciclo di discesa a mini-gradiente sui token in entrata. Questo aggiorna i suoi parametri interni per rappresentare meglio il documento specifico che sta elaborando.
Come spiega il team di ricerca di Google,”invece di comprimere le informazioni in uno stato statico, questa architettura apprende e aggiorna attivamente i propri parametri come flussi di dati.”
Attraverso questo processo di apprendimento attivo, il modello adatta dinamicamente la sua strategia di compressione, dando priorità alle informazioni rilevanti per l’attività corrente anziché applicare una funzione di decadimento valida per tutti.
Panoramica dei Titani architettura (MAC). Utilizza una memoria a lungo termine per comprimere i dati passati e quindi incorporare il riassunto nel contesto e passarlo all’attenzione. L’attenzione può allora decidere se ha bisogno di occuparsi della sintesi del passato oppure no. (Fonte: Google)
Per gestire il sovraccarico computazionale, Titans utilizza una”metrica a sorpresa”basata sull’errore del gradiente. Durante l’elaborazione di un nuovo token, il modello calcola la differenza tra la sua previsione e l’input effettivo. Un errore elevato indica”sorpresa”, il che significa che l’informazione è nuova e dovrebbe essere memorizzata. Un errore basso suggerisce che l’informazione è ridondante o già nota.
Utilizzando un esempio concreto, i ricercatori notano che”se la nuova parola è’gatto’e lo stato di memoria del modello prevede già una parola animale, il gradiente (sorpresa) è basso. Può tranquillamente saltare la memorizzazione.”
Tale memorizzazione selettiva imita l’efficienza biologica, consentendo al sistema di scartare dati di routine conservando anomalie critiche o fatti nuovi.
Complementare questo apprendimento attivo è un “meccanismo dell’oblio” adattivo. Agendo come un cancello, questa funzione applica un decadimento di peso ai parametri della memoria quando il contesto narrativo cambia in modo significativo. Bilanciando l’assunzione di nuovi dati sorprendenti con il rilascio controllato di informazioni obsolete, Titans mantiene una rappresentazione ad alta fedeltà del contesto.
Ciò impedisce al modello di soccombere al rumore che affligge i modelli a stato fisso. Il paradigma Nested Learning definisce le basi teoriche per questo approccio:
“Il Nested Learning rivela che un modello ML complesso è in realtà un insieme di problemi di ottimizzazione coerenti e interconnessi annidati l’uno nell’altro o eseguiti in parallelo.”
“Ciascuno di questi problemi interni ha il proprio flusso di contesto, un proprio insieme distinto di informazioni da cui sta cercando di apprendere.”
Questa base teorica presuppone che architettura e ottimizzazione siano due facce della stessa medaglia. Considerando il modello come una gerarchia di problemi di ottimizzazione, Titans può sfruttare la profondità computazionale del suo modulo di memoria. Ciò risolve il problema della”dimenticanza catastrofica”che ha a lungo limitato l’utilità delle reti ricorrenti.
Contesto e benchmark estremi
In particolare, questo sistema di memoria attiva gestisce finestre di contesto che rompono le architetture tradizionali. I benchmark di Google mostrano che Titans mantiene un richiamo efficace a lunghezze di contesto superiori a 2.000.000 di token. Per fare un confronto, gli attuali modelli di produzione come GPT-4o hanno in genere un limite di 128.000 token.
Negli impegnativi test”Needle-in-a-Haystack”(NIAH), che misurano la capacità di un modello di recuperare un fatto specifico sepolto in un grande volume di testo non correlato, Titans ha dimostrato una significativa superiorità rispetto alle linee di base RNN lineari. Nell’attività”Ago singolo”con rumore sintetico (S-NIAH-PK) con una lunghezza del token di 8k, la variante MAC di Titans ha raggiunto una precisione del 98,8%, rispetto al solo 31,0% di Mamba2.
Le prestazioni sui dati in linguaggio naturale sono state altrettanto robuste. Nella versione WikiText del test (S-NIAH-W), Titans MAC ha ottenuto l’88,2%, mentre Mamba2 ha faticato al 4,2%. Tali risultati suggeriscono che, sebbene le RNN lineari siano efficienti, la loro compressione a stato fisso perde fedeltà critica quando si gestiscono i dati complessi e rumorosi presenti nei documenti del mondo reale.
Prestazioni di riferimento: Titani contro linee di base all’avanguardia
Sottolineando le capacità oltre la semplice ricerca di parole chiave, il team di ricerca di Google osserva che”il modello non si limita a prendere appunti; sta comprendendo e sintetizzando l’intera storia”. Aggiornando i suoi pesi per ridurre al minimo la sorpresa dell’intera sequenza, il modello costruisce una comprensione strutturale dell’arco narrativo. Ciò gli consente di recuperare informazioni in base alle relazioni semantiche anziché alla semplice corrispondenza dei token.
Google fornisce un’analisi dettagliata della caratteristica che definisce l’architettura: il suo modulo di memoria. A differenza delle tradizionali reti neurali ricorrenti (RNN), che sono tipicamente vincolate da un vettore di dimensione fissa o da una memoria a matrice, essenzialmente un contenitore statico che può facilmente diventare sovraffollato o rumoroso man mano che i dati si accumulano, Titans introduce un nuovo modulo di memoria neurale a lungo termine.
Questo modulo funziona come una rete neurale profonda a sé stante, utilizzando specificamente un percettrone multistrato (MLP). Strutturando la memoria come una rete apprendibile piuttosto che come un archivio statico, Titans raggiunge una potenza espressiva significativamente più elevata. Questo cambiamento architetturale consente al modello di acquisire e riepilogare dinamicamente grandi volumi di informazioni.
Invece di limitarsi a troncare i dati più vecchi o a comprimerli in uno stato a bassa fedeltà per fare spazio a nuovi input, il modulo di memoria MLP sintetizza il contesto, garantendo che i dettagli critici e le relazioni semantiche siano preservati anche quando la finestra di contesto si espande in milioni di token.
Oltre alla precisione del recupero, Titans mostra anche promesse in termini di efficienza generale della modellazione del linguaggio. Alla scala di 340 milioni di parametri, il varianbencht MAC di Titans ha raggiunto una perplessità di 25,43 sul set di dati WikiText. Tali prestazioni superano sia la baseline di Transformer++ (31.52) che l’architettura originale Mamba (30.83).
Ciò indica che gli aggiornamenti della memoria attiva forniscono una migliore rappresentazione delle distribuzioni di probabilità del linguaggio rispetto ai soli pesi statici. Ali Behrouz, ricercatore capo del progetto, evidenzia le implicazioni teoriche di questo progetto, affermando che”I Titani sono in grado di risolvere problemi oltre TC0, il che significa che i Titani sono teoricamente più espressivi dei Transformers e dei modelli ricorrenti lineari più moderni nelle attività di monitoraggio dello stato.”
Tale espressività consente ai Titani di gestire attività di monitoraggio dello stato, come seguire le variabili che cambiano in un lungo file di codice o tracciare i punti della trama di un romanzo, che spesso confondono modelli ricorrenti più semplici.
Efficienza: MIRAS contro il mercato
Per formalizzare queste innovazioni architetturali, Google ha introdotto il framework MIRAS. Unificando vari approcci di modellazione di sequenze, tra cui Transformers, RNN e Titans, il modello opera sotto l’ombrello della”memoria associativa”.
Secondo Google, il framework MIRAS decostruisce la modellazione di sequenze in quattro scelte di progettazione fondamentali. La prima è l’Architettura della Memoria, che detta la forma strutturale utilizzata per archiviare le informazioni, che va dai semplici vettori e matrici ai profondi percettroni multistrato presenti su Titani. Questo è abbinato al bias attentivo, un obiettivo di apprendimento interno che regola il modo in cui il modello dà la priorità ai dati in entrata, decidendo effettivamente cosa è sufficientemente significativo da memorizzare.
Per gestire la capacità, il framework utilizza un Retention Gate. MIRAS reinterpreta i tradizionali “meccanismi dell’oblio” come forme specifiche di regolarizzazione, garantendo un equilibrio stabile tra l’apprendimento di nuovi concetti e il mantenimento del contesto storico. Infine, l’algoritmo della memoria determina le regole di ottimizzazione specifiche utilizzate per aggiornare lo stato della memoria, completando il ciclo di apprendimento attivo.
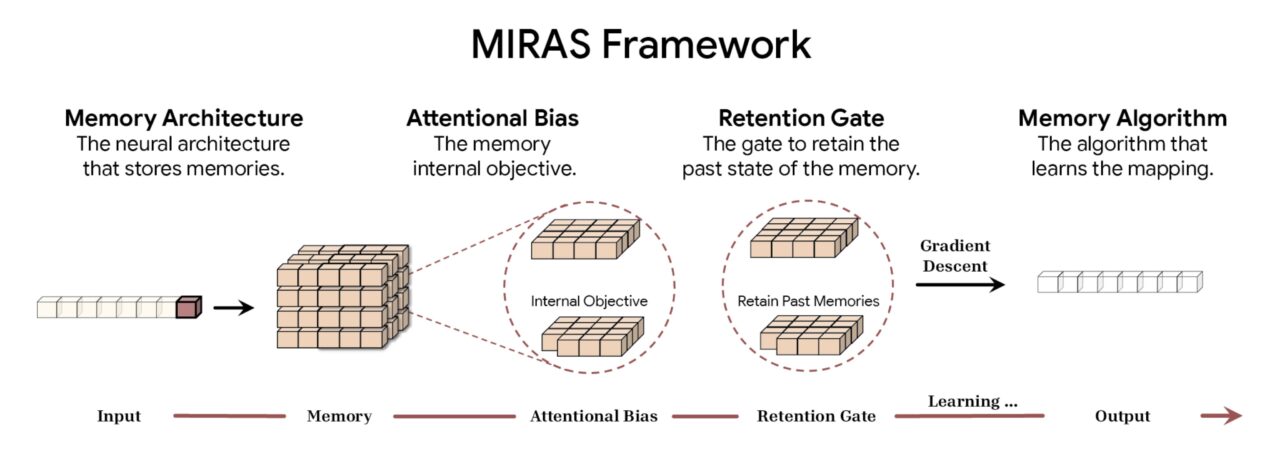 Panoramica del framework MIRAS (Fonte: Google)
Panoramica del framework MIRAS (Fonte: Google)
Scomponendo Modellando sequenze in queste quattro componenti, MIRAS demistifica la “magia” dei meccanismi di attenzione. Li riclassifica come un solo tipo di memoria associativa con impostazioni specifiche di bias e conservazione. I ricercatori possono quindi mescolare e abbinare i componenti, portando potenzialmente ad architetture ibride che combinano la precisione dell’attenzione con l’efficienza della ricorrenza.
Cambiamento del paradigma architettonico: il framework MIRAS
La memoria dinamica e ad alta capacità contrasta nettamente con la tendenza prevalente nell’Edge AI, dove l’obiettivo è spesso quello di ridurre i modelli statici per l’implementazione locale. Ad esempio, il lancio di Granite 4.0 Nano da parte di IBM ha introdotto modelli piccoli, fino a 350 milioni di parametri, progettati per essere eseguiti sui laptop.
Mentre la strategia di IBM si concentra sul rendere l’intelligenza statica onnipresente ed economica, l’approccio di Google Titans mira a rendere il modello stesso più intelligente e più adattabile. Ciò si applica anche se richiede il sovraccarico computazionale dell’aggiornamento dei pesi durante l’inferenza.
Il sovraccarico computazionale, o”Gap di contesto”, rimane l’ostacolo principale per Titans. L’aggiornamento dei parametri di memoria in tempo reale è computazionalmente più costoso dell’inferenza statica utilizzata da modelli come Granite o Llama. Tuttavia, per le applicazioni che richiedono una comprensione approfondita di set di dati su larga scala, come la scoperta legale, l’analisi genomica o il refactoring di basi di codice, la capacità di”imparare”il documento può rivelarsi più preziosa della velocità di inferenza grezza.
Servendo come prima implementazione di questa visione automodificante, l’architettura”Hope”è stata introdotta come prova di concetto nel Documento sull’apprendimento annidato. Mentre il settore continua a spingere per contesti più ampi e ragionamenti più profondi, architetture come Titans, che sfumano il confine tra formazione e inferenza, potrebbero definire la prossima generazione di modelli di base.