Un ricercatore di intelligenza artificiale di Samsung a Montreal ha creato un piccolo modello di intelligenza artificiale che va ben oltre le sue potenzialità, sfidando l’attenzione del settore sulla scala massiccia. Rilasciato questa settimana, il Tiny Recursive Model (TRM) da 7 milioni di parametri supera modelli giganteschi come Gemini 2.5 Pro di Google nei puzzle di ragionamento difficili.
Il modello, sviluppato da Alexia Jolicoeur-Martineau e dettagliato in un articolo pubblicato su arXiv, mira a dimostrare che un design intelligente può essere più importante delle dimensioni. Utilizza un semplice processo”ricorsivo”per pensare in loop e migliorare le proprie risposte, offrendo un percorso più efficiente per l’innovazione.
Questo approccio mette in discussione la necessità di modelli enormi e costosi per risolvere problemi complessi di intelligenza artificiale. Come ha affermato Jolicoeur-Martineau, “l’idea che per risolvere compiti difficili sia necessario fare affidamento su enormi modelli fondativi formati per milioni di dollari da qualche grande azienda” è una trappola”. Il rilascio segnala un movimento crescente verso modelli più piccoli e specializzati.
Dalla gerarchia complessa alla ricorsiva Semplicità
TRM si evolve dal Modello di ragionamento gerarchico (HRM), ma ne semplifica radicalmente la progettazione. Introdotto all’inizio di quest’anno, l’HRM utilizzava due reti separate che operavano a frequenze diverse, un concetto che i suoi creatori giustificavano con complesse argomentazioni biologiche sul cervello umano.
Questo approccio si basava anche su principi matematici avanzati come il Teorema della funzione implicita per gestire il suo processo di apprendimento, rendendolo difficile da analizzare. Il lavoro di Jolicoeur-Martineau elimina questi strati di astrazione.
TRM utilizza solo un’unica, minuscola rete a due strati. Si rinuncia alle analogie biologiche e alle dipendenze a punti fissi, rendendo l’architettura più trasparente. L’obiettivo era isolare il meccanismo principale: il miglioramento ricorsivo.
L’innovazione principale è il suo processo di ragionamento. Il modello inizia con una risposta approssimativa e la perfeziona in modo iterativo. In ogni ciclo, aggiorna innanzitutto il suo”processo di pensiero”interno prima di aggiornare la risposta finale, simulando efficacemente una rete molto più profonda senza costi elevati.
Questo ciclo di auto-miglioramento è una forma di”supervisione profonda”, in cui il modello viene addestrato in ogni passaggio per avvicinarsi alla soluzione corretta. Ciò gli consente di apprendere complesse catene di ragionamento in più fasi che normalmente richiederebbero un modello molto più grande.
Come spiega il documento di ricerca,”questo processo ricorsivo consente al modello di migliorare progressivamente la sua risposta… in modo estremamente efficiente in termini di parametri, riducendo al minimo l’overfitting.”Questo metodo migliora le prestazioni ed evita i problemi che i modelli più grandi devono affrontare su set di dati di piccole dimensioni.
Superare il suo peso sui benchmark di ragionamento
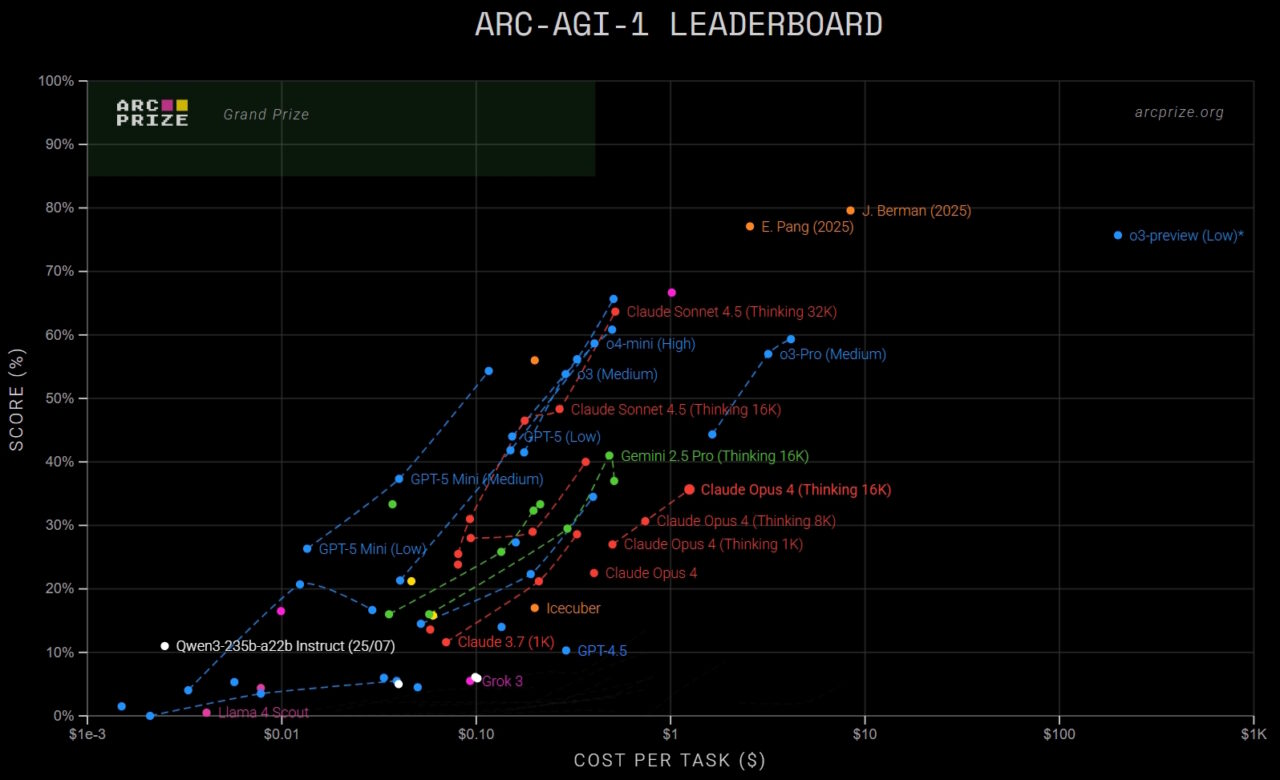
La potenza di TRM è più evidente sui benchmark progettati per testare il ragionamento astratto dell’IA, un dominio in cui anche i modelli più grandi spesso hanno difficoltà. Il suo risultato straordinario arriva con l’Abstract and Reasoning Corpus (ARC-AGI), un’avvincente suite di puzzle visivi semplici per gli esseri umani ma notoriamente difficili per l’intelligenza artificiale.
Nella prima versione del test, ARC-AGI-1, TRM ha raggiunto una precisione del 45%. Questo punteggio supera molti dei pesi massimi del settore, tra cui Gemini 2.5 Pro di Google (37,0%), o3-mini-high di OpenAI (34,5%) e DeepSeek R1 (15,8%), nonostante TRM abbia meno dello 0,01% dei loro parametri.
Il vantaggio del modello si basa sull’ancora più difficile benchmark ARC-AGI-2. Qui, TRM ha ottenuto il 7,8%, battendo ancora una volta il 4,9% di Gemini 2.5 Pro e il 3,0% di o3-mini-high. Sebbene questi punteggi assoluti possano sembrare bassi, rappresentano un significativo passo avanti rispetto a un benchmark in cui i progressi sono stati notoriamente lenti.
Per il contesto, la classifica attuale è sormontata da enormi modelli di frontiera come Grok 4 di xAI, ma le prestazioni di TRM con soli 7 milioni di parametri lo rendono un un valore anomalo drammatico, che evidenzia l’efficienza della sua architettura.
Il dominio del modello si estende ad altri domini logici dove i modelli di grandi dimensioni spesso vacillano. Su Sudoku-Extreme, un set di dati di puzzle difficili con solo 1.000 esempi di allenamento, TRM ha stabilito un nuovo record all’avanguardia raggiungendo una precisione dell’87,4%. Ciò rappresenta un enorme miglioramento rispetto al 55% ottenuto dal suo predecessore, HRM.
Allo stesso modo, sul benchmark Maze-Hard, che prevede la ricerca di percorsi lunghi attraverso complesse griglie 30×30, TRM ha ottenuto l’85,3%. Questi risultati su domini logici multipli e distinti dimostrano la potenza del suo approccio ricorsivo per la risoluzione strutturata dei problemi.
‘Less is More’: A New Philosophy for Efficient AI
Forse la maggior parte notevole è l’efficienza del modello. L’intero modello è stato addestrato in soli due giorni su quattro GPU NVIDIA H-100 per meno di 500 dollari, come confermato dal ricercatore. Ciò è in contrasto con i corsi di formazione multimilionari richiesti per i LLM di frontiera di oggi.
<500$, 4 H-100 per circa 2 giorni
— Alexia Jolicoeur-Martineau (@jm_alexia) 7 ottobre 2025
Jolicoeur-Martineau ha sottolineato questo punto affermando: “con ricorsiva ragionando, risulta che “meno è meglio”. Un piccolo modello pre-addestrato da zero… può ottenere molto senza spendere una fortuna.”Questo rapporto costo-efficacia democratizza la ricerca all’avanguardia sull’intelligenza artificiale.
La scoperta che una rete più piccola a due livelli ha sovraperformato le versioni più grandi sfida anche le leggi di scalabilità convenzionali. L’articolo suggerisce che ciò è dovuto al fatto che la profondità ricorsiva aiuta a prevenire l’overfitting, un problema comune quando si addestrano modelli di grandi dimensioni su dati limitati.
L’ingegnere ricercatore AI Sebastian Raschka ha commentato l’efficienza, sottolineando:”sì, è ancora possibile fare cose interessanti senza un data center.”
Dal modello di ragionamento gerarchico (HRM) a un nuovo modello minuscolo ricorsivo (TRM).
Alcuni mesi fa, l’HRM ha fatto scalpore nella comunità di ricerca sull’intelligenza artificiale poiché ha mostrato prestazioni davvero buone nella sfida ARC nonostante le sue dimensioni ridotte di 27 milioni. (È circa 22 volte più piccolo del… pic.twitter.com/YhMpn4hlxi
— Sebastian Raschka (@rasbt) 8 ottobre 2025
Il progetto è su GitHub con una licenza permissiva del MIT, consentendo l’uso commerciale e incoraggiando un’adozione più ampia.
Un risolutore specializzato, non un generalista
È fondamentale comprendere il contesto di TRM. Il modello è un risolutore altamente specializzato, non un chatbot generico come quelli basati su modelli di OpenAI o Google. Le sue prestazioni sono limitate ad attività strutturate e basate su griglia in cui il suo metodo ricorsivo eccelle.
Questa specializzazione è una funzionalità, non un bug. Come ha osservato Deedy Das, partner di Menlo Ventures, “la maggior parte delle aziende di intelligenza artificiale oggi utilizza LLM generici con suggerimenti per le attività. compiti, i modelli più piccoli potrebbero non solo essere più economici, ma di qualità molto più elevata!”
Il documento TRM sembra un significativo passo avanti nell’intelligenza artificiale.
Distrugge la frontiera di Pareto sui benchmark ARC AGI 1 e 2 (e sulla risoluzione di Sudoku e Maze) con un costo estd <$ 0,01 per attività e costa <$ 500 per addestrare il modello 7M su 2 H100 per 2 giorni.
[Specifiche di formazione e test]… pic.twitter.com/9c31HdxiLy
— Deedy (@deedydas) 9 ottobre 2025
Questo focus significa che TRM non scriverà poesie o riassumerà riunioni. Tuttavia, il suo successo fornisce un potente proof-of-concept per le imprese. Ciò suggerisce che una serie di piccoli modelli esperti potrebbe essere più efficace ed efficiente di un singolo modello generalista monolitico.
Mentre la comunità dell’intelligenza artificiale ha elogiato l’innovazione, alcuni hanno notato l’ambito ristretto. Il consenso è che, sebbene il TRM non sia una forma di intelligenza generale, il suo messaggio è ampio: un’attenta ricorsione, non solo un’espansione costante, potrebbe guidare la prossima ondata di ragionamento. ricerca.