Bytedance ha svelato Omnihuman-1, un sistema in grado di creare contenuti video umani credibili da una sola immagine di riferimento e audio di accompagnamento.
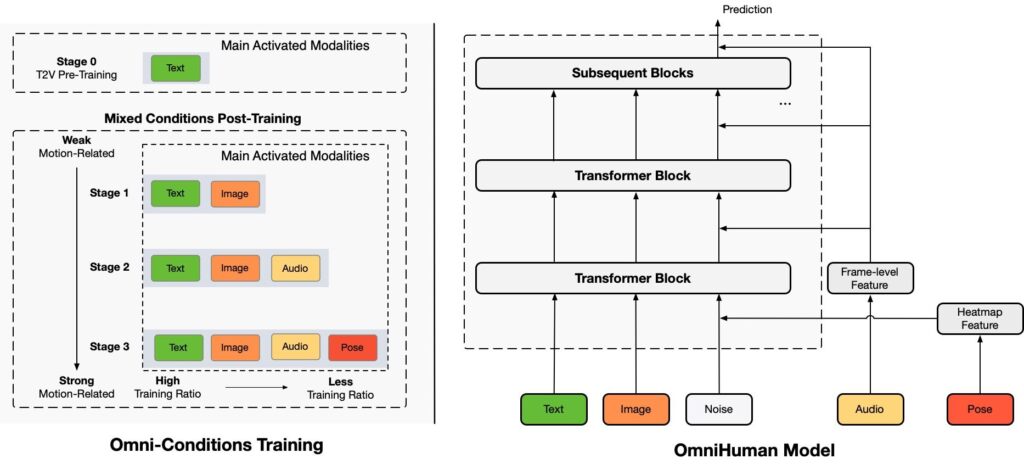
Il modello unisce più segnali di condizionamento: text, audio e posa Sintetizzare una vasta gamma di uscite video. Gli autori spiegano il loro approccio nel documento di ricerca omnihuman-1: ripensando il ridimensionamento dei modelli di animazione umana condizionati a uno stadio , chiarire come oltre 19.000 ore di allenamento si nutrono del suo nucleo di trasformatore di diffusione.
Dati di miscelazione ed esempi notevoli
Omnihuman-1 è costruito su un’architettura di trasformatore di diffusione (DIT), un modello che combina le capacità di denoizzazione dei modelli di diffusione con l’efficienza di gestione della sequenza dei trasformatori.
Un processo di formazione a più stadi che affina progressivamente la generazione di movimento umano. Utilizza un causale Autoencoder variazionale 3D (3D VAE) Per codificare le sequenze video in uno spazio latente compresso, consentendo un’elaborazione efficiente durante la conservazione della coerenza temporale.
Il modello integra più segnali di condizionamento: text, audio e posa-Levaging classifier-GRATUITA GRATUITA (CFG) Per bilanciare il realismo e l’adesione ai segnali di input. L’architettura include anche un guider posa che codifica per il controllo del movimento per il controllo a grana fine, mentre un encoder di aspetto estrae l’identità e i dettagli di sfondo da un’immagine di riferimento usando un MMDIT modificato (trasformatore di diffusione di modellazione mascherata).
 fonte: bytedance
fonte: bytedance
eNlETike I modelli precedenti che si basavano sul rigoroso filtraggio dei dati, la strategia di addestramento omni-condizioni di Omnihuman garantisce che diversi dati di addestramento contribuiscano alla sintesi dei gesti naturalistici, alle interazioni degli oggetti e ai rapporti di aspetto adattabile, distinguendolo da precedenti modelli di animazione umana a base di posa e audio.
Omnihuman adotta una”strategia di formazione Omni-condizioni”per fondere i segnali di testo, audio e posa in un singolo flusso di lavoro. L’audio è preelaborato con WAV2Vec, mentre le immagini di riferimento viaggiano attraverso un autoencoder auto-variazionale (VAE)./p>
Nell’articolo, gli autori affermano: “Omnihuman genera video altamente realistici con qualsiasi proporzione di proporzione e corpo e migliora significativamente la generazione dei gesti e l’interazione degli oggetti sui metodi esistenti, a causa del ridimensionamento dei dati abilitati da onni-Condizioni di allenamento.”
Test rafforzano tali affermazioni, tra cui dimostrazioni sorprendenti come A Fictional Taylor Swift Performance e a clip che rivelano strani gesti attorno a un bicchiere di vino , che mostrano sia la natura convincente della produzione sia stranezze che sorgono con alcune pose.
[contenuto incorporato]
benchmark e indicatori di performance
“Omnihuman dimostra prestazioni superiori rispetto a Modelli
principali in entrambe le attività di animazione del ritratto e del corpo usando un singolo modello”, secondo i ricercatori che hanno condiviso la seguente tabella di confronto.
Studi di ablazione indicano Omnihuman-1 superano i metodi precedenti, come sadtalker e hall-3 — In diverse metriche, tra cui FID, FVD, IQA e Sync-C.
Impegni di sicurezza della Casa Bianca Rifletti una spinta più ampia per affrontare l’uso improprio di DeepFake, mentre l’etichettatura obbligatoria di Meta del contenuto AI segnala le principali piattaforme con il problema.
L’anno scorso, L’autorità ampliata dell’FTC per richiedere documenti relativi all’intelligenza artificiale ha aumentato la posta in gioco per la trasparenza. Google ha ampliato la sua tecnologia di filigrana AI, Synthid, per includere testo e video generati dall’IA. E lo scorso dicembre, Meta ha annunciato Meta Video SEAL, un nuovo strumento open source progettato per filtrare i video generati dall’IA. Il sigillo video incorpora filigrane invisibili ma robuste che persistono attraverso modifiche, compressione e condivisione, rendendo possibile tracciare e autenticare il contenuto.
e altre misure come le filigrane C2PA di Openi per Dall-E 3 e Microsoft’s Bing Image Creator La filigrana sottolinea una crescente attenzione sull’autenticità.
Meta già etichetta le immagini generate dall’aria ai”immaginate con AI”per frenare la disinformazione, ma questo funziona solo se i meccanismi di rilevamento sottostanti funzionano o se i video delle immagini generati dall’IA filigrana. v=v_zjvrmhzoi”> un pretendente talk Ted e una lezione Einstein DeepFake Capacità di movimento ad ampio raggio-e stranezze occasionali quando si maneggiano mani o oggetti di scena.
[contenuto incorporato]
Gli osservatori dicono che questo sottolinea perché la discussione più ampia di filigrane di intelligenza artificiale e strumenti di rilevamento è essenziale per mantenere Creazioni sintetiche di causare danni non intenzionali.
offrendo movimenti ad alta fedeltà e rapporti di aspetti flessibili, Omnihuman-1 si distingue dalla precedente dipendenza da set di dati filtrati in stretta. I suoi esperimenti sul rapporto di allenamento confermano che la miscelazione di segnali forti e deboli-usati, audio e testo-si fa una migliore prestazione, che è evidente nei punteggi FID e FVD inferiori rispetto a quelli di Sadtalker o Hal-3.
Sadtalker è Uno strumento guidato dall’intelligenza artificiale progettato per animare immagini statiche generando coefficienti di movimento 3D realistici dagli ingressi audio. Analizzando l’audio fornito, prevede i corrispondenti movimenti facciali, consentendo la creazione di animazioni parlanti di una singola immagine. Questo approccio consente la generazione di animazioni stilizzate e condutture audio, migliorando il realismo e l’espressività dell’output.
HALLO-3 è un modello di animazione di ritratto avanzato che utilizza reti di trasformatori di diffusione per produrre altamente produrre produrre altamente produrre reti di trasformato Animazioni dinamiche e realistiche. Impiega un modello generativo video pre-trasformatore basato sul trasformatore, che dimostra forti capacità di generalizzazione in vari scenari.
Sia che si tratti di gesti di co-discorso realistici o personaggi simili Strumenti che possono spostarsi rapidamente tra intrattenimento, istruzione e contenuti potenzialmente sensibili, mentre i regolatori e i giocatori tecnologici rimangono vigili degli sviluppi di DeepFake.