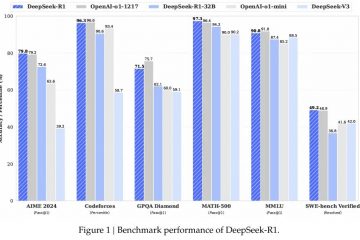
La Federation of Indian Publishers (FIP), che rappresenta oltre l’80% del settore editoriale indiano, ha intentato una causa per violazione del copyright contro OpenAI presso l’Alta Corte di Delhi.
La causa accusa OpenAI di addestrare il suo modello ChatGPT su opere letterarie protette da copyright senza autorizzazione, una mossa che secondo gli editori mina i diritti di proprietà intellettuale e interrompe le vendite di libri.
Pranav Gupta, segretario generale di la FIP, ha sottolineato le potenziali conseguenze delle pratiche di OpenAI. “Se gli strumenti gratuiti forniscono riassunti ed estratti dettagliati dei libri, perché i lettori dovrebbero acquistare libri? Ciò ha un impatto diretto sulle vendite e minaccia la creatività”, ha affermato Gupta in un annuncio del dicembre 2024.

Il caso richiede un’ordinanza del tribunale per obbligare OpenAI a eliminare set di dati contenenti materiale non autorizzato e a negoziare accordi di licenza con gli editori.
Correlato: OpenAI non rispetta la scadenza chiave per lo strumento di copyright dei contenuti promesso
La causa evidenzia la capacità di ChatGPT di generare riepiloghi dettagliati di libri protetti da copyright, ad esempio, quando viene chiesto di riassumere il primo volume di Harry Potter, ChatGPT ha fornito suddivisioni capitolo per capitolo ed eventi chiave.
Sebbene l’intelligenza artificiale abbia evitato di riprodurre il testo letterale, gli editori sostengono che questa funzionalità scoraggia i lettori dall’acquistare libri.
Una sfida globale crescente per l’intelligenza artificiale generativa
La causa FIP rispecchia una tendenza più ampia di azioni legali rivolte a strumenti di intelligenza artificiale generativa come ChatGPT, che si basano su modelli linguistici di grandi dimensioni (LLM).
I LLM sono formati su vasti set di dati, inclusi testi disponibili al pubblico, per generare risposte simili a quelle umane. I critici sostengono che l’uso di materiale protetto da copyright in questi set di dati di formazione viola le leggi sulla proprietà intellettuale.
Sfide legali simili sono emerse in tutto il mondo. A novembre Nel 2024, l’agenzia di stampa indiana ANI ha intentato una causa contro OpenAI, sostenendo l’uso non autorizzato dei suoi contenuti di notizie e citando danni alla reputazione causati da falsificazioni citazioni attribuite all’ANI.
A livello globale, entità come il New York Times hanno intrapreso azioni legali contro società di intelligenza artificiale per ragioni simili.
Correlati: Microsoft, OpenAI Push to Dismiss Publisher Copyright Affermazioni sullo scraping dell’intelligenza artificiale nel caso NYT
L’avvocato di Mumbai Siddharth Chandrashekhar ha commentato le implicazioni più ampie di questi casi.”Le sentenze metteranno alla prova l’equilibrio tra la tutela della proprietà intellettuale e l’incoraggiamento del progresso tecnologico”, ha affermato in un’intervista ai media locali.
Risposte degli editori e OpenAI
OpenAI ha costantemente negato le accuse di violazione del copyright, affermando che i suoi modelli si basano su dati disponibili al pubblico e operano nel rispetto dei principi del fair use.
In risposta alla causa di ANI, la società ha sostenuto che i tribunali indiani non hanno giurisdizione poiché i suoi server si trovano fuori dall’India. Tuttavia, la FIP ribatte che i servizi attivi di OpenAI in India lo collocano nel quadro giuridico del paese.
In una dichiarazione che affronta accuse simili, OpenAI ha dichiarato:”Costruiamo i nostri modelli di intelligenza artificiale utilizzando dati disponibili al pubblico, in modo protetto dal fair use e dai principi correlati e supportato da precedenti legali di lunga data e ampiamente accettati.”
La FIP afferma di avere prove credibili che OpenAI abbia utilizzato il lavoro dei suoi membri per addestrare ChatGPT. Ciò è in linea con le preoccupazioni sollevate da altri editori globali.
Nell’ottobre 2024, Penguin Random House ha aggiornato le proprie politiche sul copyright per vietare esplicitamente l’uso dei suoi libri per la formazione sull’intelligenza artificiale. La clausola sul copyright della società afferma:”Nessuna parte di questo libro può essere utilizzata o riprodotta in alcun modo allo scopo di addestrare tecnologie o sistemi di intelligenza artificiale.”
Al contrario, HarperCollins ha proposto un accordo di licenza che consente alle aziende di intelligenza artificiale di utilizzare libri di saggistica per una tariffa fissa di 2.500 dollari per titolo e hanno già firmato un accordo del genere con Microsoft per loro conto. Ciò ha scatenato la reazione negativa degli autori, che hanno criticato la sottovalutazione della proprietà intellettuale e la mancanza di una garanzia a lungo termine risarcimento.
L’Alta Corte di Delhi ha incaricato OpenAI di rispondere entro il 10 gennaio, con un’udienza plenaria prevista per il 28 gennaio. Gli esiti di questo e di casi simili potrebbero stabilire precedenti chiave per la protezione della proprietà intellettuale in India, un mercato in rapida crescita per le tecnologie IA.