Hugging Face ha presentato due modelli di intelligenza artificiale leggeri, SmolVLM-256M-Instruct e SmolVLM-500M-Instruct, volti a ridefinire il modo in cui l’intelligenza artificiale può funzionare su dispositivi con potenza di calcolo limitata.
I modelli, che utilizzano rispettivamente 256 milioni e 500 milioni di parametri, sono progettati per affrontare le sfide affrontate dagli sviluppatori che lavorano con hardware limitato o analisi di dati su larga scala a costi minimi.
Il rilascio rappresenta una svolta in termini di efficienza e accessibilità per l’elaborazione dell’intelligenza artificiale. I modelli SmolVLM offrono funzionalità multimodali avanzate, consentendo attività come la descrizione di immagini, l’analisi di brevi video e la risposta a domande su PDF o grafici scientifici.
Come spiega Hugging Face,”SmolVLM rende più veloce ed economico creare contenuti ricercabili database, con velocità che competono con modelli 10 volte più grandi.”
Ridefinire l’intelligenza artificiale multimodale con modelli più piccoli
SmolVLM-256M-Istruire e SmolVLM-500M-Instruct sono progettati per massimizzare le prestazioni riducendo al minimo il consumo di risorse. I modelli multimodali come questi elaborano e interpretano più forme di dati, come testo e immagini, contemporaneamente, rendendoli versatili per diverse applicazioni.
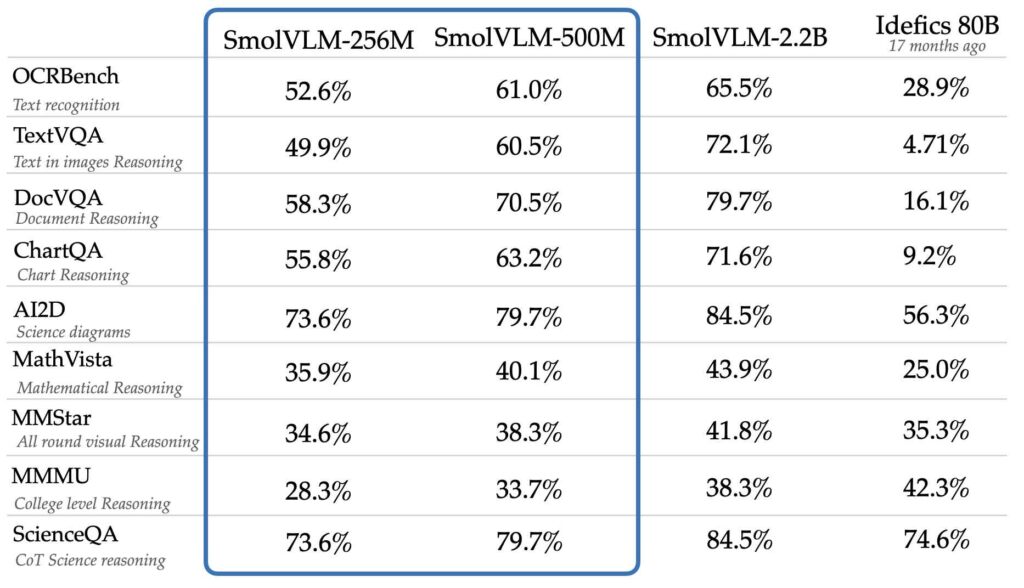
Nonostante le loro dimensioni ridotte, i modelli raggiungono livelli di prestazioni paragonabili o migliori modelli molto più grandi come Idefics 80B, secondo benchmark come AI2D, che valuta la capacità di comprendere e ragionare con diagrammi scientifici.
Idefics 80B è una riproduzione ad accesso libero di modello di linguaggio visivo Flamingo closed-source di DeepMind, sviluppato da Hugging Face, in grado di elaborare sia immagini che input di testo.
 Fonte: Hugging Face
Fonte: Hugging Face
Lo sviluppo di questi modelli si basava su due set di dati proprietari: The Cauldron e Docmatix. The Cauldron è una raccolta curata di 50 set di dati di immagini e testo di alta qualità che enfatizza l’apprendimento multimodale, mentre Docmatix è progettato su misura per la comprensione dei documenti, abbinando file scansionati a didascalie dettagliate per migliorare la comprensione.
Il team M4 di Hugging Face, noto per la sua esperienza nell’intelligenza artificiale multimodale, ha guidato la creazione di questi set di dati.
Nel loro annuncio, Hugging Face ha sottolineato l’importanza di rendere l’intelligenza artificiale più accessibile.”Gli sviluppatori ci hanno detto che avevano bisogno di modelli per laptop o anche browser, e quel feedback ha guidato la creazione di questi modelli”, ha affermato il team. Questi modelli risolvono i limiti pratici che molti sviluppatori devono affrontare, soprattutto quando lavorano con dispositivi consumer o operazioni attente al budget.
Innovazioni tecniche nei modelli SmolVLM
Un fattore critico nel successo dei modelli risiede nelle decisioni strategiche prese da Hugging Face per migliorare sia l’efficienza che la progettazione di base precisione. Una di queste decisioni è stata la adozione di un codificatore di visione più piccolo, SigLIP base patch-16/512, invece del più grande SigLIP 400M SO utilizzato in modelli precedenti come SmolVLM 2B.
Questo codificatore più piccolo elabora le immagini a risoluzioni più elevate senza aumentare significativamente il sovraccarico computazionale.
Un’altra innovazione riguarda la tokenizzazione, un processo chiave nei modelli di intelligenza artificiale in cui i dati sono divisi in unità più piccole (token ) per l’analisi. Ottimizzando il modo in cui vengono elaborati i token immagine, Hugging Face ha ridotto la ridondanza e migliorato la capacità dei modelli di gestire dati complessi.
Ad esempio, i separatori delle immagini secondarie, precedentemente mappati su più token, sono ora rappresentati con un singolo token, migliorando sia la stabilità dell’addestramento che la qualità dell’inferenza.”Con SmolVLM, stiamo ridefinendo ciò che i modelli IA più piccoli possono ottenere”, ha spiegato il team nel loro annuncio.
Queste scelte di progettazione consentono ai modelli SmolVLM di codificare immagini a una velocità di 4.096 pixel per token, un valore significativo miglioramento rispetto ai 1.820 pixel per token visti nelle versioni precedenti. Il risultato è una comprensione visiva più nitida e velocità di elaborazione più elevate.
SmolVLM Perspective for. Applicazioni
I vantaggi pratici di SmolVLM vanno oltre i tipici casi d’uso dell’intelligenza artificiale. Gli sviluppatori possono integrare perfettamente questi modelli nei flussi di lavoro esistenti utilizzando strumenti come Transformers, MLX e ONNX che ha fornito anche istruzioni dettagliate punti di controllo ottimizzati per entrambi i modelli, consentendo una facile personalizzazione per attività specifiche.
I modelli sono particolarmente adatti per l’analisi e il recupero dei documenti. In collaborazione con IBM, Hugging Face ha applicato SmolVLM-256M al loro sistema di documentazione, dimostrando il suo potenziale nell’automazione dei flussi di lavoro e nell’estrazione di informazioni dettagliate dai file scansionati. I primi risultati di questa partnership si sono mostrati promettenti, evidenziando la versatilità del modello.
Inoltre, i modelli SmolVLM sono disponibili sotto licenza Apache Licenza 2.0, che garantisce accesso aperto agli sviluppatori di tutto il mondo. Questo impegno per lo sviluppo open source è in linea con la missione di Hugging Face di democratizzare l’intelligenza artificiale, consentendo a più organizzazioni di adottare tecnologie avanzate senza affrontare costi proibitivi.
Bilanciare costi e prestazioni
L’introduzione di SmolVLM-256M e SmolVLM-500M completa la famiglia SmolVLM, che ora include una gamma completa di modelli di linguaggio di visione più piccoli progettati per varie applicazioni.
Questi modelli sono particolarmente efficaci per ambienti con risorse limitate, come laptop consumer o applicazioni basate su browser. La variante 256M, il modello Vision Language più piccolo mai rilasciato, si distingue per la sua capacità di fornire prestazioni robuste su dispositivi con meno di 1 GB di RAM.
Hugging Face prevede che SmolVLM diventi una soluzione pratica per gli sviluppatori che affrontano grandi sfide-elaborazione dei dati su vasta scala con un budget limitato.