DeepSeek ha lanciato i suoi ultimi modelli di intelligenza artificiale open source, DeepSeek-R1 e DeepSeek-R1-Zero, ridefinendo il modo in cui le capacità di ragionamento possono essere ottenute attraverso l’apprendimento per rinforzo (RL).
Il nuovi modelli sfidano lo sviluppo dell’intelligenza artificiale convenzionale dimostrando che la messa a punto supervisionata (SFT) non è essenziale per coltivare capacità avanzate di risoluzione dei problemi. Con risultati di riferimento che rivaleggiano con sistemi proprietari come la serie o1 di OpenAI, i modelli di DeepSeek illustrano il potenziale crescente dell’intelligenza artificiale open source nel fornire strumenti competitivi e ad alte prestazioni.
Il successo di questi modelli risiede nei loro approcci unici al rinforzo Learning (RL), l’introduzione dei dati di avviamento a freddo e un processo di distillazione efficace. Queste innovazioni hanno prodotto capacità di ragionamento in compiti di codifica, matematica e logica generale, sottolineando la fattibilità dell’intelligenza artificiale open source come concorrente dei principali modelli proprietari.
Correlato: DeepSeek AI Open Sources VL2 Series of Vision Language Models
I risultati dei benchmark evidenziano il potenziale open source
Le prestazioni di DeepSeek-R1 in benchmark ampiamente rispettati confermano le sue capacità:
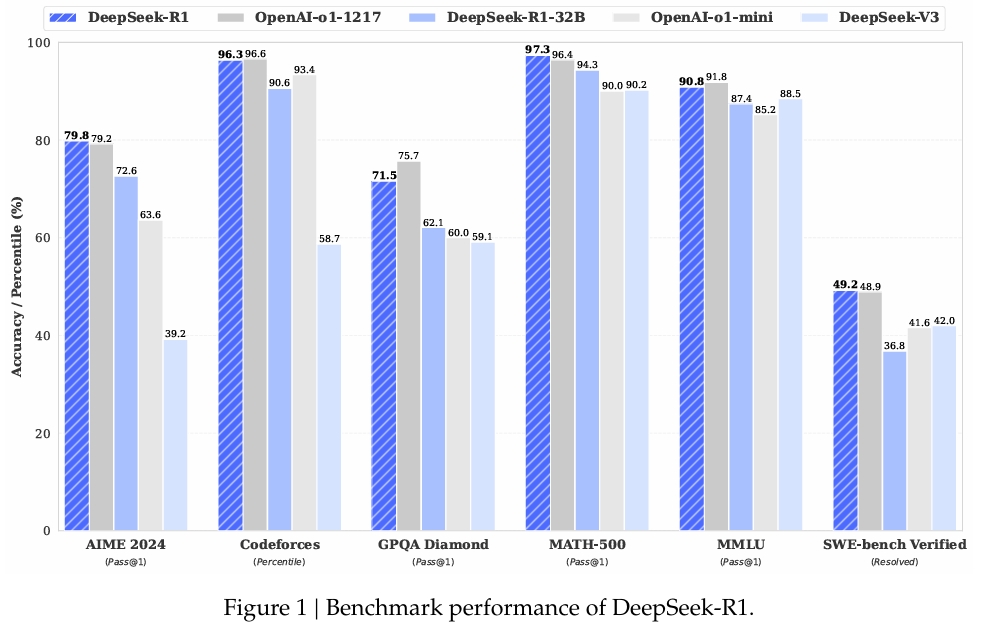
In MATH-500, un set di dati progettato per valutare la risoluzione di problemi matematici, DeepSeek-R1 ha ottenuto un punteggio Pass@1 del 97,3%, corrispondente a quello di OpenAI modello o1-1217. Nel benchmark AIME 2024, che si concentra su attività di ragionamento avanzato, il modello ha ottenuto un punteggio del 79,8%, superando leggermente i risultati di OpenAI.
Le prestazioni del modello in LiveCodeBench, un benchmark per attività di codifica e di logica, sono state altrettanto degne di nota, con un punteggio Pass@1-CoT del 65,9%. Secondo la ricerca di DeepSeek, questo lo rende uno dei modelli open source con le migliori prestazioni in questa categoria.
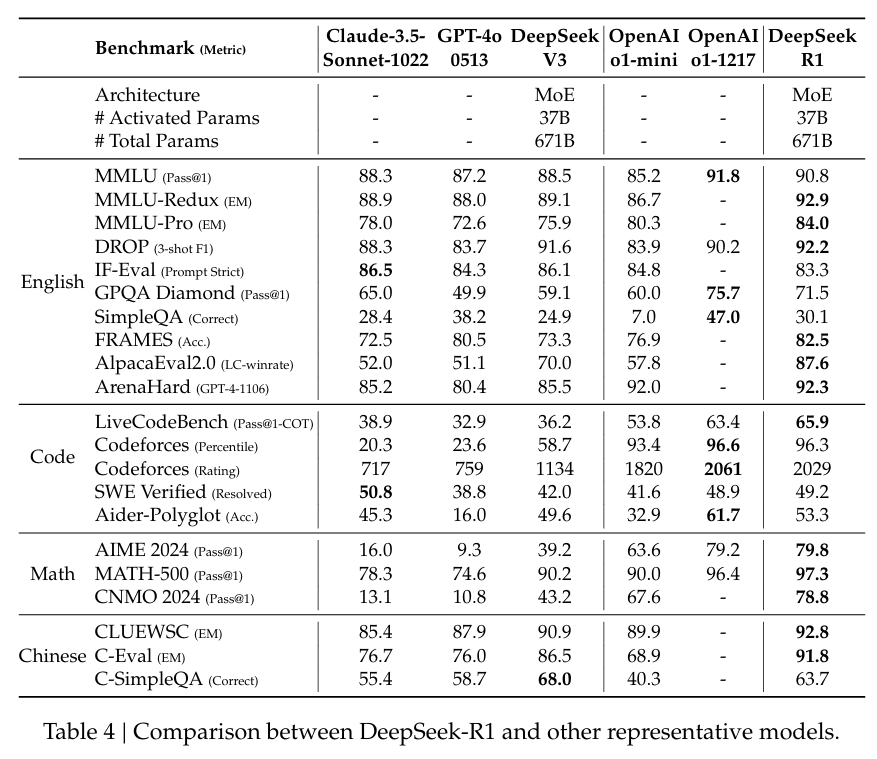
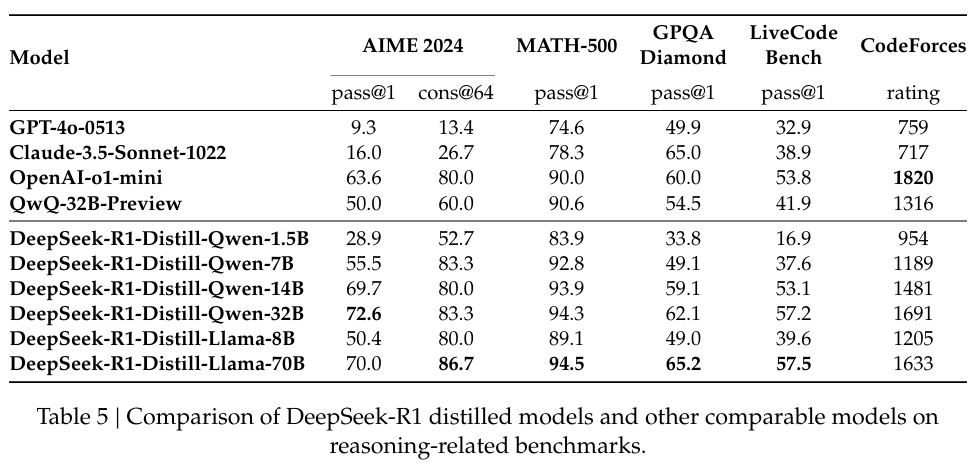
L’azienda ha anche investito molto nella distillazione, garantendo che versioni più piccole di DeepSeek-R1 conserva gran parte delle capacità di ragionamento dei modelli più grandi. In particolare, il modello da 32 miliardi di parametri, DeepSeek-R1-Distill-Qwen-32B, ha sovraperformato o1-mini di OpenAI in diverse categorie pur essendo più accessibile dal punto di vista computazionale.
Apprendimento per rinforzo senza supervisione: DeepSeek-R1-Zero
DeepSeek-R1-Zero è il coraggioso tentativo dell’azienda di esplorare Formazione solo RL. Utilizza un algoritmo unico, Group Relative Policy Optimization (GRPO), che semplifica la formazione RL eliminando la necessità di un modello critico separato.
Utilizza invece punteggi raggruppati per stimare le linee di base, riducendo significativamente i costi computazionali e allo stesso tempo mantenimento della qualità della formazione. Questo approccio consente al modello di sviluppare comportamenti di ragionamento, incluso il ragionamento basato sulla catena di pensiero (CoT) e l’autoriflessione.
Nel loro documento di ricerca, il team di DeepSeek ha dichiarato:
“DeepSeek-R1-Zero dimostra capacità come l’autoverifica, la riflessione e la generazione di CoT lunghi. Tuttavia, ha difficoltà con la ripetizione, la leggibilità e la mescolanza dei linguaggi, il che lo rende meno adatto ai casi d’uso del mondo reale.”
Sebbene questi comportamenti emergenti fossero promettenti, i limiti del modello hanno evidenziato la necessità di perfezionamento. Ad esempio , i suoi risultati erano occasionalmente ripetitivi o presentavano problemi con lingue miste, riducendo l’usabilità in scenari pratici.
Dalla formazione solo RL alla formazione ibrida: DeepSeek-R1
Per indirizzare Queste sfide, DeepSeek ha sviluppato DeepSeek-R1, combinando RL con un perfezionamento supervisionato. Il processo è iniziato con un set di dati curato con avvio a freddo di CoT lunghi e leggibili dall’uomo, progettati per migliorare la coerenza e la leggibilità della linea di base formando il modello su questa base è entrato in RL con una migliore capacità di soddisfare le aspettative umane in termini di chiarezza e pertinenza.
Correlato: LLaMA AI Under Fire: cosa Meta non ti dice di”Open”Source”Models
DeepSeek ha descritto questo approccio nella sua documentazione:
“A differenza di R1-Zero, per prevenire la fase iniziale e instabile di avvio a freddo dell’addestramento RL dal modello base, per R1 costruiamo e raccogliamo un piccola quantità di lunghi dati CoT per mettere a punto il modello come attore RL iniziale.”
La pipeline includeva anche RL iterativo per affinare ulteriormente le capacità di ragionamento e di risoluzione dei problemi, producendo un modello in grado di gestire scenari complessi come come codifica e prove matematiche.
Accessibilità open source e sfide future
DeepSeek ha rilasciato i suoi modelli sotto la licenza MIT, sottolineando il suo impegno verso l’open-principi di origine. Questo modello di licenza consente a ricercatori e sviluppatori di utilizzare, modificare e sviluppare liberamente il lavoro di DeepSeek, promuovendo la collaborazione e l’innovazione nella comunità dell’intelligenza artificiale.
Nonostante i successi, il team riconosce che le sfide rimangono. I risultati in lingue miste, la sensibilità tempestiva e la necessità di migliori capacità di ingegneria del software sono aree di miglioramento. Le future iterazioni di DeepSeek-R1 mireranno ad affrontare queste limitazioni espandendo al contempo le sue funzionalità a nuovi domini.
I ricercatori hanno espresso ottimismo sui loro progressi, affermando:
“Progettando attentamente il modello per il freddo-avviando i dati con precedenti umani, osserviamo prestazioni migliori rispetto a DeepSeek-R1-Zero. Riteniamo che la formazione iterativa sia un modo migliore per ragionare sui modelli.”
Implicazioni per il settore dell’intelligenza artificiale
Il lavoro di DeepSeek segnala un cambiamento nel panorama della ricerca sull’intelligenza artificiale , dove i modelli open source possono ora competere con i leader proprietari, dimostrando che RL può raggiungere un ragionamento di alto livello senza SFT ed enfatizzando la distillazione per scalare l’accessibilità, DeepSeek ha stabilito un punto di riferimento per la futura ricerca sull’intelligenza artificiale.
Mentre l’intelligenza artificiale open source continua a evolversi, i progressi di DeepSeek-R1 forniscono un modello per sfruttare l’RL per produrre modelli pratici e ad alte prestazioni.