I ricercatori dell’Università di Intelligenza Artificiale Mohamed bin Zayed (MBZUAI) ad Abu Dhabi hanno ha presentato LlamaV-o1, un nuovo modello di intelligenza artificiale multimodale che privilegia la trasparenza e la coerenza logica nel ragionamento.
A differenza di altri modelli di intelligenza artificiale, che spesso forniscono risultati in scatola nera, LlamaV-o1 dimostra il suo processo di risoluzione dei problemi passo dopo passo, consentendo agli utenti di tracciare ogni fase della sua logica.
Abbinato all’introduzione di VRC-Bench, un nuovo punto di riferimento per la valutazione delle fasi intermedie del ragionamento, LlamaV-o1 offre una nuova prospettiva sull’interpretabilità e l’utilizzabilità dell’IA in diversi campi come la diagnostica medica, la finanza e la scienza ricerca.
Il rilascio di questo modello e benchmark riflette la crescente domanda di intelligenza artificiale sistemi che non solo forniscono risultati accurati ma spiegano anche come tali risultati vengono raggiunti.
Correlati: OpenAI Presenta il nuovo modello o3 con capacità di ragionamento drasticamente migliorate
VRC-Bench: un benchmark progettato per un ragionamento trasparente
Il benchmark VRC-Bench è un elemento centrale di Sviluppo e valutazione di LlamaV-o1. I benchmark tradizionali dell’intelligenza artificiale si concentrano principalmente sull’accuratezza della risposta finale, spesso trascurando i processi logici che portano a tali risposte.
VRC-Bench affronta questa limitazione valutando la qualità dei passaggi di ragionamento attraverso metriche come Faithfulness-Step e Semantic Coverage, che misurano quanto bene il ragionamento di un modello si allinea con il materiale originale e la coerenza logica.
Correlato: Il nuovo modello Gemini 2.0 Flash Thinking di Google sfida o1 Pro di OpenAI con prestazioni eccellenti
Copre oltre 1.000 attività in otto categorie, VRC-Bench include domini come il ragionamento visivo, l’imaging medico e l’analisi del contesto culturale. Queste attività presentano più di 4.000 passaggi di ragionamento verificati manualmente, rendendo il benchmark uno dei più completi nella valutazione del ragionamento passo dopo passo.
I ricercatori ne descrivono l’importanza, affermando: “La maggior parte dei benchmark si concentra principalmente sull’accuratezza del compito finale, trascurando la qualità dei passaggi intermedi del ragionamento. VRC-Bench presenta una serie diversificata di sfide… consentendo una solida valutazione della coerenza logica e della correttezza nel ragionamento.”
Stabilendo un nuovo standard per la valutazione dell’intelligenza artificiale multimodale, VRC-Bench garantisce che modelli come LlamaV-o1 siano ritenuti responsabili dei propri processi decisionali, offrendo un livello di trasparenza fondamentale per le applicazioni ad alto rischio.
Metriche di prestazione: come sta LlamaV-o1 Out
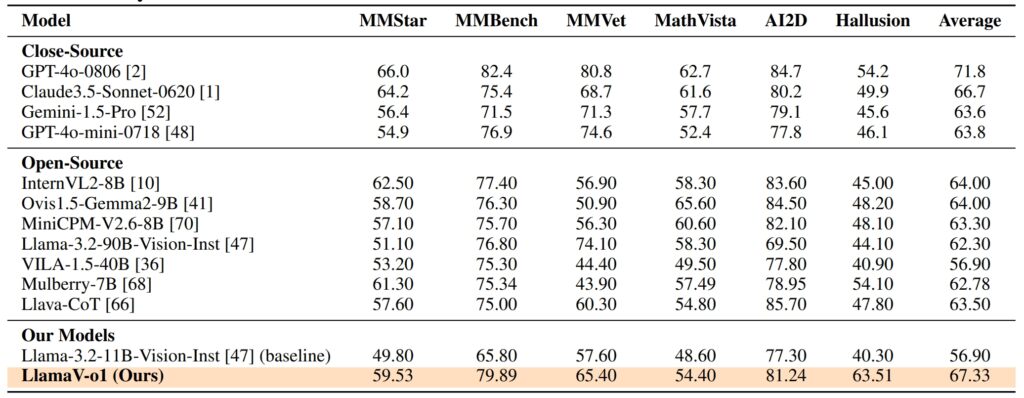
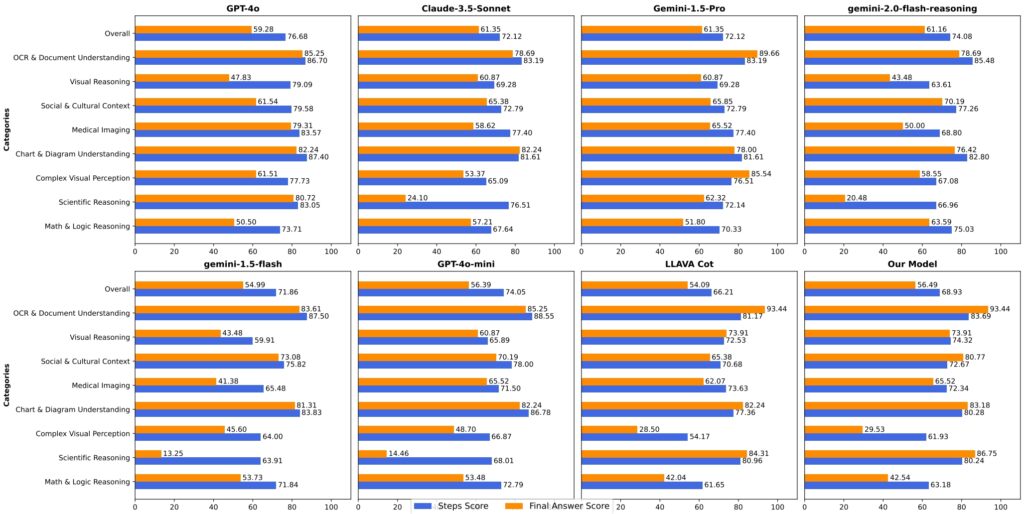
Le prestazioni di LlamaV-o1 su VRC-Bench e altri benchmark dimostrano la sua abilità tecnica. Ha ottenuto un punteggio di ragionamento di 68,93, superando altri modelli open source come LLava-CoT (66,21) e. riducendo il divario con modelli proprietari come GPT-4o, che ha ottenuto 71,8
Oltre alla sua precisione, LlamaV-o1 ha fornito velocità di inferenza cinque volte più elevate rispetto ai suoi concorrenti, dimostrando la sua efficienza.
Su sei benchmark multimodali, tra cui MathVista, AI2D e Hallusion, LlamaV-o1 ha ottenuto un punteggio medio del 67,33%. sottolinea la sua capacità di gestire diversi compiti di ragionamento mantenendo coerenza logica e trasparenza.
Formazione LlamaV-o1: la sinergia tra apprendimento del curriculum e ricerca del raggio
Il successo di LlamaV-o1 è radicato nei suoi metodi di formazione innovativi. I ricercatori hanno utilizzato l’apprendimento del curriculum, una tecnica ispirata all’educazione umana.
Questo approccio inizia con compiti più semplici e progredisce gradualmente verso quelli più complessi, consentendo al modello di sviluppare capacità di ragionamento fondamentali prima di affrontare sfide avanzate.
Strutturando il processo di formazione, l’apprendimento del curriculum migliora la capacità del modello di generalizzare su diversi compiti, dall’OCR di documenti al ragionamento scientifico.
Correlato: QwQ di Alibaba-32B-Preview si unisce alla battaglia sul ragionamento del modello AI con OpenAI
Beam Search, un algoritmo di ottimizzazione, migliora questo approccio formativo generando più percorsi di ragionamento in parallelo e selezionando quello più logico. Questo metodo non solo migliora la precisione del modello ma riduce anche i costi computazionali, rendendolo più efficiente per le applicazioni del mondo reale.
Come spiegano i ricercatori,”Sfruttando l’apprendimento del curriculum e Beam Search, il nostro modello acquisisce competenze in modo incrementale… garantendo sia un’inferenza ottimizzata che solide capacità di ragionamento.”
Applicazioni in medicina , Finanza e oltre
Le capacità di ragionamento trasparenti di LlamaV-o1 lo rendono particolarmente adatto per applicazioni in cui l’affidabilità e l’interpretabilità sono essenziali Nell’imaging medico, ad esempio, il modello può fornire non solo una diagnosi ma a spiegazione dettagliata di come si è arrivati a questa conclusione.
Questa funzionalità consente ai radiologi e ad altri professionisti medici di convalidare informazioni basate sull’intelligenza artificiale, migliorando la fiducia e l’accuratezza nel processo decisionale critico.
In nel settore finanziario, LlamaV-o1 eccelle nell’interpretazione di grafici e diagrammi complessi, offrendo suddivisioni dettagliate che forniscono informazioni utili.
LlamaV-o1 rappresenta un progresso significativo nell’intelligenza artificiale multimodale, in particolare nella sua capacità di fornire un ragionamento trasparente. Combinando l’apprendimento del curriculum e Beam Search con i robusti parametri di valutazione di VRC-Bench, stabilisce un nuovo punto di riferimento per interpretabilità ed efficienza.
Man mano che i sistemi di intelligenza artificiale diventano sempre più integrati nei settori critici, la necessità di modelli in grado di spiegare i loro processi di ragionamento non potrà che crescere.