Il laboratorio cinese di intelligenza artificiale DeepSeek ha introdotto DeepSeek V3, il suo prossimo modello linguistico genopen-source. Dotato di 671 miliardi di parametri, il modello utilizza una cosiddetta architettura Mixture-of-Experts (MoE) per combinare efficienza computazionale e prestazioni elevate.
I progressi tecnici di
DeepSeek V3 lo collocano tra i sistemi di intelligenza artificiale più potenti fino ad oggi, rivaleggiando sia con concorrenti open source come Llama 3.1 di Meta che con modelli proprietari come GPT-4o di OpenAI.
Il rilascio evidenzia un momento cruciale nell’intelligenza artificiale, dimostrando che i sistemi open source possono competere con, e in alcuni casi con prestazioni migliori, alternative più costose e chiuse.
Correlato:
Il modello di anteprima cinese DeepSeek R1-Lite prende di mira il leader di OpenAI nel ragionamento automatizzato
Alibaba Qwen rilascia l’anteprima del modello AI di ragionamento multimodale QVQ-72B
Architettura efficiente e innovativa
L’architettura di DeepSeek V3 combina due concetti avanzati per ottenere efficienza e prestazioni eccezionali: Multi-Head Latent Attention (MLA) e Mixture-of-Experts (MoE).
MLA migliora le potenzialità del modello capacità di elaborare input complessi utilizzando più teste di attenzione per concentrarsi su diversi aspetti dei dati, estraendo informazioni contestuali ricche e diversificate.
MoE, d’altra parte, attiva solo un sottoinsieme dei 671 miliardi totali del modello parametri – circa 37 miliardi per attività – garantendo che le risorse computazionali vengano utilizzate in modo efficace senza compromettere la precisione. Insieme, questi meccanismi consentono a DeepSeek V3 di fornire risultati di alta qualità riducendo al contempo le richieste infrastrutturali.
Affrontando le sfide comuni nei sistemi MoE, come la distribuzione non uniforme del carico di lavoro tra gli esperti, DeepSeek ha introdotto un sistema di carico ausiliario senza perdite. strategia di bilanciamento. Questo metodo dinamico assegna i compiti alla rete di esperti, mantenendo la coerenza e massimizzando la precisione delle attività.
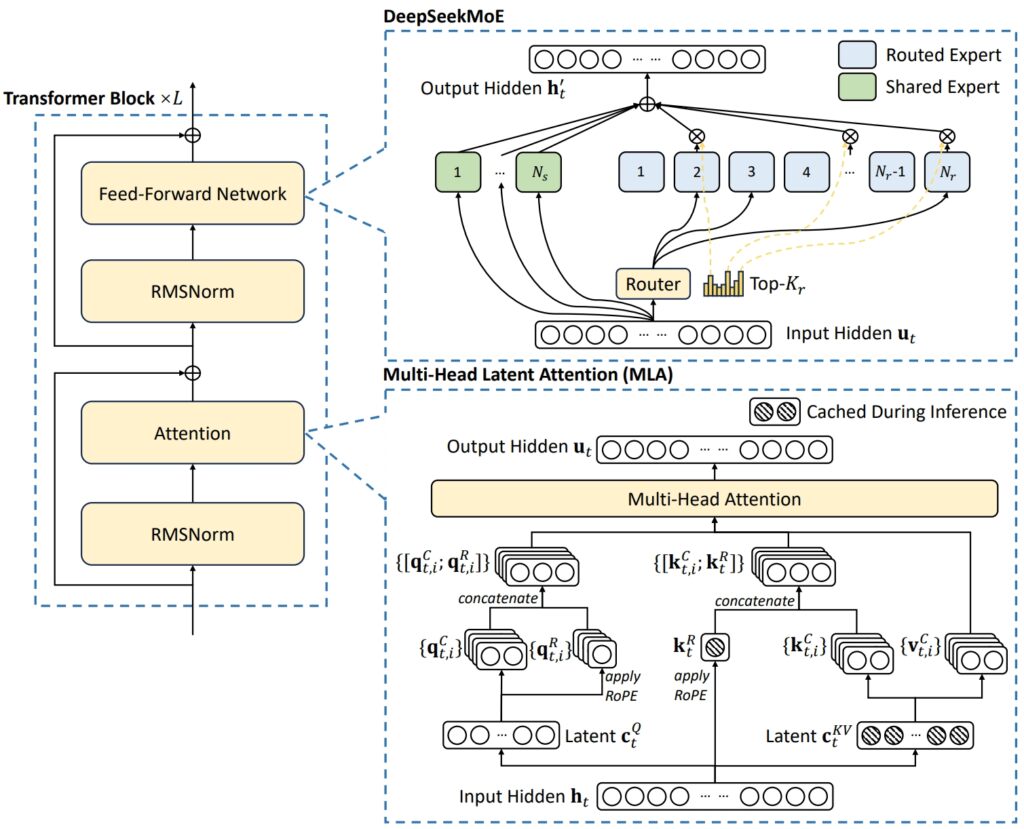 Illustrazione dell’architettura di base di DeepSeek-V3 (Immagine: DeepSeek)
Illustrazione dell’architettura di base di DeepSeek-V3 (Immagine: DeepSeek)
Per migliorare ulteriormente l’efficienza, DeepSeek V3 utilizza Multi-Token Predizione (MTP), una funzionalità che consente al modello di generare più token contemporaneamente, accelerando significativamente la generazione del testo.
Questa funzionalità non solo migliora l’efficienza dell’addestramento, ma posiziona anche il modello per applicazioni più veloci nel mondo reale, rafforzandone la si posiziona come leader nell’innovazione dell’intelligenza artificiale open source.
Prestazioni benchmark: leader in matematica e codifica
I risultati benchmark di DeepSeek V3 mostrano le sue eccezionali capacità in tutto un ampio spettro di compiti, consolidando la propria posizione di leader tra i modelli di intelligenza artificiale open source.
Sfruttando la sua architettura avanzata e l’ampio set di dati di formazione, il modello ha raggiunto prestazioni di alto livello in matematica, codifica e benchmark multilingue, presentando al tempo stesso risultati competitivi in aree tradizionalmente dominate da modelli closed-source come GPT di OpenAI-4o e Claude 3.5 Sonnet di Anthropic.
🚀 Presentiamo DeepSeek-V3!
Il più grande balzo in avanti ancora:
⚡ 60 token al secondo (3 volte più veloce della V2!)
💪 Funzionalità migliorate
🛠 Compatibilità API intatta
🌍 Modelli e documenti completamente open source🐋 1/n pic.twitter.com/p1dV9gJ2Sd
— DeepSeek (@deepseek_ai) 26 dicembre 2024
Matematico Ragionamento
Sul Test Math-500, un benchmark progettato per valutare le capacità di risoluzione dei problemi matematici, DeepSeek V3 ha ottenuto un punteggio impressionante di 90,2. Questo punteggio lo colloca davanti a tutti i concorrenti open source, con Qwen 2.5 che ottiene 80 punti e Llama 3.1 che segue con 73,8. Anche GPT-4o, un modello closed source rinomato per le sue capacità generali, ha ottenuto un punteggio leggermente inferiore a 74,6. Questa prestazione sottolinea le capacità di ragionamento avanzate di DeepSeek V3, in particolare in attività ad alta intensità di calcolo in cui precisione e logica sono fondamentali.
Inoltre, DeepSeek V3 eccelleva in altri test specifici di matematica, come:
MGSM (Math Grade School Math): punteggio 79,8, superando Lama 3.1 (69,9) e Qwen 2,5 (76,2). CMath (matematica cinese): punteggio 90,7, superando sia Llama 3.1 (77,3) che GPT-4o (84,5).
Questi risultati evidenziano non solo la sua forza nel ragionamento matematico basato sull’inglese ma anche in compiti che richiedono la risoluzione di problemi numerici specifici della lingua.
Correlato: DeepSeek AI Open Sources VL2 Series of Vision Language Models
Programmazione e codifica
DeepSeek V3 ha dimostrato notevoli abilità nella codifica e nella risoluzione dei benchmark. Su Codeforces, una piattaforma di programmazione competitiva, il modello ha ottenuto un ranking del 51,6 percentile, riflettendo la sua capacità di gestire compiti algoritmici complessi. Questa prestazione supera significativamente i rivali open source come Llama 3.1, che ha ottenuto solo 25,3, e sfida persino Claude 3.5 Sonnet, che ha registrato un percentile inferiore. Il successo del modello è stato ulteriormente convalidato dai suoi punteggi elevati nei benchmark specifici della codifica:
HumanEval-Mul: Ha ottenuto un punteggio di 82,6, superando Qwen 2,5 (77,3) e eguagliando GPT-4o (80,5). LiveCodeBench (Pass@1): punteggio 37,6, davanti a Llama 3.1 (30,1) e Claude 3,5 Sonnet (32,8). CRUXEval-I: punteggio 67,3, significativamente migliore sia di Qwen 2.5 (59,1) che di Llama 3.1 (58,5).
Questi risultati evidenziano l’idoneità del modello per le applicazioni nello sviluppo di software e negli ambienti di codifica del mondo reale, dove la risoluzione efficiente dei problemi e la generazione di codice sono fondamentali.
Attività multilingue e non in inglese
DeepSeek V3 si distingue anche nei benchmark multilingue, dimostrando la sua capacità di elaborare e comprendere un’ampia gamma di lingue. Nel test CMMLU (Chinese Multilingual Language Understanding), il modello ha ottenuto un punteggio eccezionale di 88,8, superando Qwen 2,5 (89,5) e dominando Llama 3.1, rimasto indietro a 73,7. Allo stesso modo, su C-Eval, un benchmark di valutazione cinese, DeepSeek V3 ha ottenuto un punteggio di 90,1, ben davanti a Llama 3.1 (72,5).
In attività multilingue non inglesi:
Benchmark specifici per l’inglese
Mentre DeepSeek V3 eccelle in matematica, codifica e multilingue prestazioni, i suoi risultati in alcuni parametri di riferimento specifici per l’inglese riflettono margini di miglioramento. Ad esempio, nel benchmark SimpleQA, che valuta la capacità di un modello di rispondere a semplici domande concrete in inglese, DeepSeek V3 ha ottenuto 24,9 , restando indietro rispetto a GPT-4o, che ha ottenuto 38,2. Allo stesso modo, su FRAMES, un punto di riferimento per la comprensione di strutture narrative complesse, GPT-4o ha ottenuto un punteggio di 80,5, rispetto a 73,3 di DeepSeek.
Nonostante queste lacune, le prestazioni del modello rimangono altamente competitive, soprattutto data la sua natura open source e l’efficienza in termini di costi. La leggera sottoperformance nelle attività specifiche per l’inglese è compensata dalla sua posizione dominante nei benchmark matematici e multilingue, aree in cui sfida costantemente e spesso supera i rivali closed-source.
I risultati dei benchmark di DeepSeek V3 non solo dimostrano la sua sofisticazione tecnica ma posizionarlo anche come modello versatile e ad alte prestazioni per un’ampia gamma di compiti. La sua superiorità nei benchmark di matematica, codifica e multilingue evidenzia i suoi punti di forza, mentre i suoi risultati competitivi nelle attività di inglese mostrano la sua capacità di competere con leader del settore come GPT-4o e Claude 3.5 Sonnet.
Fornendo questi risultati a una frazione del costo associato ai sistemi proprietari, DeepSeek V3 illustra il potenziale dell’intelligenza artificiale open source per competere, e in alcuni casi superare, le alternative closed-source.
Correlato: Apple pianifica il lancio dell’intelligenza artificiale in Cina tramite Tencent e ByteDance
Formazione conveniente su larga scala
One Di uno dei risultati più importanti di DeepSeek V3 è il suo processo di formazione economicamente vantaggioso. Il modello è stato addestrato su un set di dati di 14,8 trilioni di token utilizzando GPU Nvidia H800, con un tempo di addestramento totale di 2,788 milioni di ore GPU. Il costo complessivo ammontava a 5,576 milioni di dollari, una frazione dei 500 milioni di dollari stimati necessari per addestrare Meta’s Llama 3.1.
La GPU NVIDIA H800 è una versione modificata della GPU H100 progettata per il mercato cinese per conformarsi alle norme sull’esportazione regolamenti. Entrambe le GPU si basano sull’architettura Hopper di NVIDIA e vengono utilizzate principalmente per applicazioni di intelligenza artificiale e di calcolo ad alte prestazioni. La velocità di trasferimento dati chip-to-chip dell’H800 è ridotta a circa la metà di quella dell’H100
Il processo di formazione ha utilizzato metodologie avanzate, inclusa la formazione di precisione mista dell’8° PQ. Questo approccio riduce l’utilizzo della memoria codificando i dati in un formato a virgola mobile a 8 bit senza sacrificare la precisione. Inoltre, l’algoritmo DualPipe ha ottimizzato il parallelismo della pipeline, garantendo un coordinamento uniforme tra i cluster GPU.
DeepSeek afferma che il pre-addestramento di DeepSeek-V3 ha richiesto solo 180.000 ore di GPU H800 per trilioni di token, utilizzando un cluster di 2.048 GPU.
Accessibilità e distribuzione
DeepSeek ha reso disponibile la V3 con una licenza MIT, fornendo agli sviluppatori l’accesso al modello sia per applicazioni di ricerca che commerciali. Le aziende possono integrare il modello tramite la piattaforma o API DeepSeek Chat, che ha un prezzo competitivo di 0,27 dollari per milione di token di input e 1,10 dollari per milione di token di output.
La versatilità del modello si estende alla sua compatibilità con varie piattaforme hardware, tra cui GPU AMD e NPU Huawei Ascend. Ciò garantisce un’ampia accessibilità per ricercatori e organizzazioni con diverse esigenze infrastrutturali.
DeepSeek ha sottolineato la sua attenzione all’affidabilità e alle prestazioni, affermando:”Per garantire la conformità SLO e un throughput elevato, utilizziamo una strategia di ridondanza dinamica per gli esperti durante la fase di precompilazione, in cui gli esperti ad alto carico vengono periodicamente duplicati e riorganizzati per prestazioni ottimali.”
Implicazioni più ampie per l’ecosistema AI
Il rilascio di DeepSeek V3 sottolinea una tendenza più ampia verso democratizzazione dell’intelligenza artificiale. Fornendo un modello ad alte prestazioni a una frazione del costo associato ai sistemi proprietari, DeepSeek sta sfidando il dominio di operatori closed-source come OpenAI e Anthropic. La disponibilità di strumenti così avanzati consente una più ampia sperimentazione e innovazione in tutti i settori.
La pipeline di DeepSeek incorpora modelli di verifica e riflessione dal suo modello R1 in DeepSeek-V3, migliorando le capacità di ragionamento mantenendo il controllo sullo stile e sulla lunghezza dell’output.
Il successo di DeepSeek V3 solleva interrogativi sul futuro equilibrio di potere nel settore dell’intelligenza artificiale. Man mano che i modelli open source continuano a colmare il divario con i sistemi proprietari, forniscono alle organizzazioni alternative competitive che danno priorità all’accessibilità e all’efficienza in termini di costi.
