I ricercatori di Sakana AI, una startup di intelligenza artificiale con sede a Tokyo, hanno introdotto un nuovo sistema di ottimizzazione della memoria che migliora l’efficienza dei modelli basati su Transformer, inclusi i modelli di linguaggio di grandi dimensioni (LLM).
Il metodo chiamato Neural Attention Memory Models (NAMM) disponibile tramite il codice di formazione completo su GitHub riduce l’utilizzo della memoria fino al 75% migliorando al tempo stesso le prestazioni generali. Concentrandosi sui token essenziali e rimuovendo le informazioni ridondanti, i NAMM affrontano una delle sfide più dispendiose in termini di risorse dell’intelligenza artificiale moderna: la gestione di finestre di contesto lunghe.
I modelli di trasformatore, la spina dorsale dei LLM, si basano su”finestre di contesto”per elaborare i dati di input Queste finestre di contesto memorizzano”coppie chiave-valore”(cache KV) per ogni token nella sequenza di input.
Man mano che la lunghezza della finestra aumenta, raggiungendo ora centinaia di migliaia di token, il i costi computazionali salgono alle stelle. Le soluzioni precedenti tentavano di ridurre questo costo attraverso la potatura manuale dei token o strategie euristiche, ma spesso peggioravano le prestazioni. I NAMM, tuttavia, utilizzano reti neurali addestrate attraverso l’ottimizzazione evolutiva per automatizzare e perfezionare il processo di gestione della memoria.
Ottimizzazione della memoria con i NAMM
I NAMM analizzano i valori di attenzione generato da Transformers per determinare l’importanza del token. Elaborano questi valori in spettrogrammi, rappresentazioni basate sulla frequenza comunemente utilizzate nell’elaborazione audio e del segnale, per comprimere ed estrarre le caratteristiche chiave dei modelli di attenzione.
Queste informazioni vengono quindi trasmesse attraverso una rete neurale leggera che assegna un punteggio a ciascun token, decidendo se deve essere conservato o scartato.
Sakana AI evidenzia come gli algoritmi evolutivi guidano i NAMM successo. A differenza dei metodi tradizionali basati sul gradiente, che sono incompatibili con decisioni binarie come”ricordare”o”dimenticare”, l’ottimizzazione evolutiva testa e perfeziona iterativamente le strategie di memoria per massimizzare le prestazioni a valle.
“L’evoluzione supera intrinsecamente la non-differenziabilità delle nostre operazioni di gestione della memoria, che implicano risultati binari di”ricordare”o”dimenticare”,”spiegano i ricercatori.
Risultati comprovati rispetto ai benchmark
Per convalidare le prestazioni e l’efficienza dei modelli di memoria di attenzione neurale (NAMM), Sakana AI ha condotto test approfonditi su numerosi benchmark leader del settore progettati per valutare l’elaborazione a lungo contesto e le capacità multi-task. I risultati hanno sottolineato in modo significativo la capacità dei NAMM migliorare le prestazioni riducendo i requisiti di memoria, dimostrando la loro efficacia in diversi quadri di valutazione.
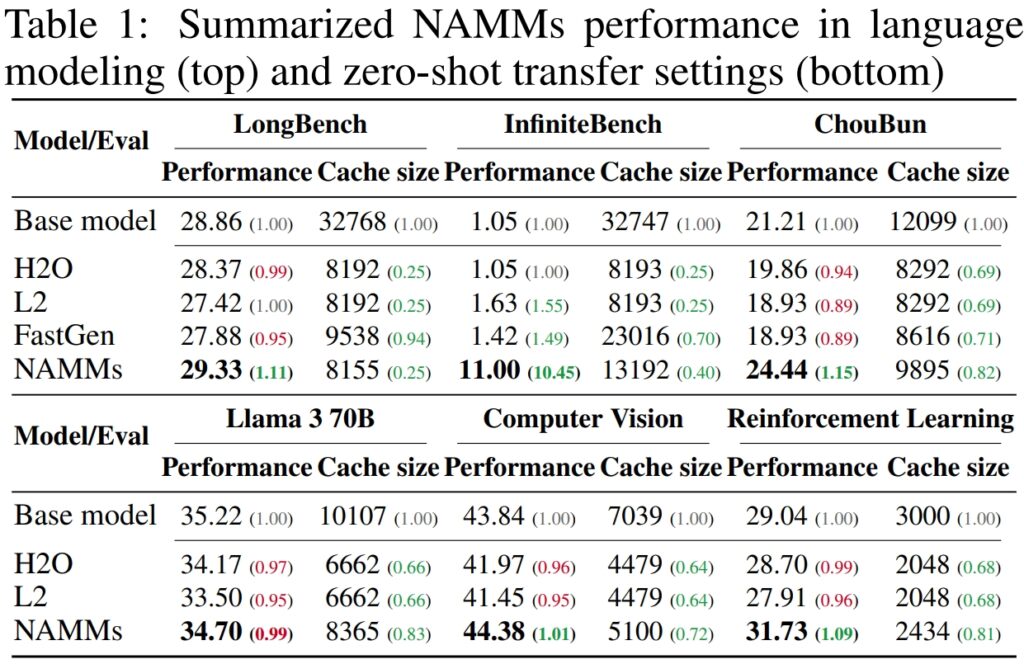
Su LongBench, un benchmark creato appositamente per misurando le prestazioni dei modelli su attività a lungo contesto, i NAMM hanno ottenuto un miglioramento dell’11% in termini di precisione rispetto al modello di base a contesto completo. Questo miglioramento è stato ottenuto riducendo l’utilizzo della memoria del 75%, evidenziando l’efficienza del metodo nella gestione della cache dei valori-chiave (KV).
Eliminando in modo intelligente i token meno rilevanti, i NAMM hanno consentito al modello di concentrarsi sul contesto critico senza sacrificare i risultati, rendendolo ideale per scenari che richiedono input estesi, come l’analisi di documenti o risposte a domande di lunga durata.
p>
Per InfiniteBench, un benchmark che spinge i modelli ai loro limiti con tempi estremamente lunghi sequenze, alcune delle quali superano i 200.000 token, i NAMM hanno dimostrato la loro capacità di scalare in modo efficace.
Mentre i modelli di base faticavano con le richieste computazionali di input così lunghi, i NAMM hanno ottenuto un notevole incremento delle prestazioni, aumentando la precisione dall’1,05% all’11,00%.
Questo risultato è particolarmente degno di nota perché mette in mostra la capacità dei NAMM di gestire contesti ultra-lunghi, una capacità sempre più essenziale per applicazioni come l’elaborazione di letteratura scientifica, documenti legali o archivi di codici di grandi dimensioni in cui le dimensioni di input dei token sono immense.
Sul benchmark ChouBun di Sakana AI, che valuta il ragionamento a lungo contesto per compiti in lingua giapponese, I NAMM hanno prodotto un miglioramento del 15% rispetto al valore di base. ChouBun colma una lacuna nei benchmark esistenti, che tendono a concentrarsi sulle lingue inglese e cinese, testando modelli su input di testo giapponese estesi.
Il successo dei NAMM su ChouBun evidenzia la loro versatilità tra le lingue e dimostra la loro robustezza nella gestione di input non inglesi, una caratteristica chiave per le applicazioni IA globali. I NAMM sono stati in grado di conservare in modo efficiente contenuti specifici del contesto eliminando ridondanze grammaticali e token meno significativi, consentendo al modello di eseguire in modo più efficace attività come il riepilogo e la comprensione in formato lungo in giapponese.
 Fonte: Sakana AI
Fonte: Sakana AI
The i risultati dimostrano collettivamente che i NAMM eccellono nell’ottimizzazione dell’utilizzo della memoria senza compromettere la precisione. Sia che vengano valutati su attività che richiedono sequenze estremamente lunghe o in contesti di lingua diversa dall’inglese, i NAMM superano costantemente i modelli di base, ottenendo sia efficienza computazionale che risultati migliori.
Questa combinazione di risparmio di memoria e miglioramenti in termini di precisione posiziona i NAMM come un grande progresso per i sistemi di intelligenza artificiale aziendali incaricati di gestire input vasti e complessi.
I risultati sono particolarmente degni di nota rispetto a metodi precedenti come H₂O e L2, che ha sacrificato le prestazioni a favore dell’efficienza. I NAMM, d’altro canto, raggiungono entrambi.
“I nostri risultati dimostrano che i NAMM forniscono con successo miglioramenti costanti su entrambi gli assi delle prestazioni e dell’efficienza rispetto ai trasformatori di base”, affermano i ricercatori.
Applicazioni intermodali: oltre il linguaggio
Uno dei risultati più impressionanti è stata la capacità dei NAMM di trasferire lo zero-shot ad altre attività e modalità di input
Uno degli aspetti più notevoli dei modelli NAMM (Neural Attention Memory Models) è la loro capacità di trasferire senza problemi tra diverse attività e modalità di input, oltre le tradizionali applicazioni basate sul linguaggio.
A differenza di altri metodi di ottimizzazione della memoria, che spesso richiedono riqualificazione o messa a punto in ciascun dominio, i NAMM mantengono la loro efficienza e i vantaggi prestazionali senza ulteriori aggiustamenti. Gli esperimenti di Sakana AI hanno dimostrato questa versatilità in due domini chiave: visione artificiale e apprendimento per rinforzo, che presentano entrambi sfide uniche per i sistemi basati su Transformer. modelli.
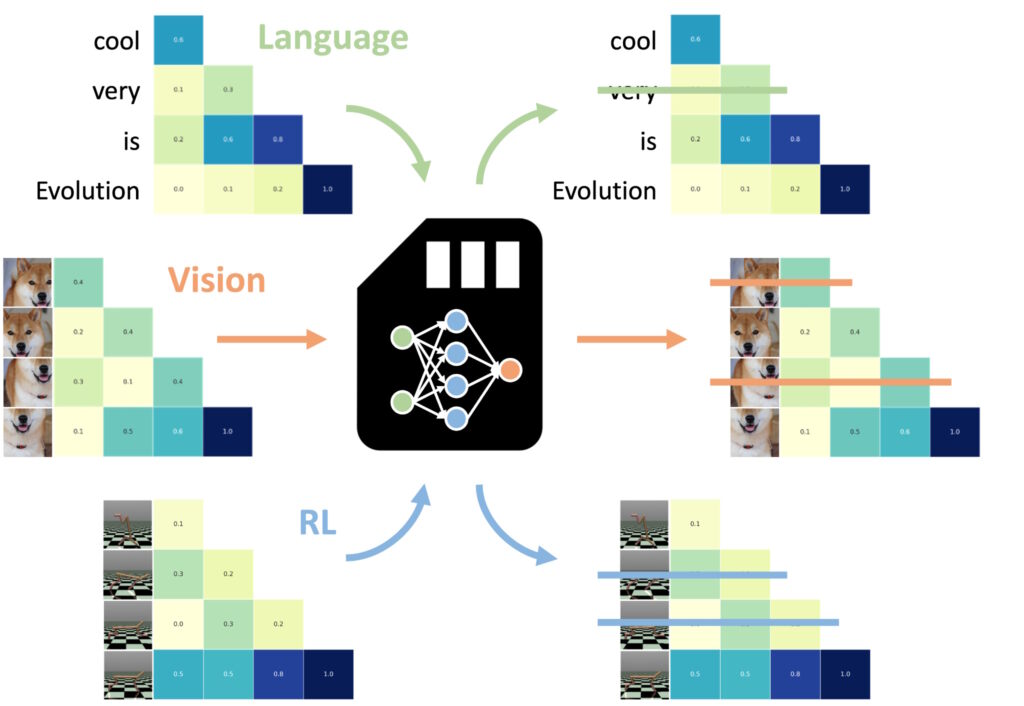 I NAMM formati sul linguaggio possono essere zero-ripresa trasferita ad altri trasformatori attraverso modalità di input e domini di attività. (Immagine: Sakana AI)
I NAMM formati sul linguaggio possono essere zero-ripresa trasferita ad altri trasformatori attraverso modalità di input e domini di attività. (Immagine: Sakana AI)
Nella visione artificiale, i NAMM sono stati valutati utilizzando il modello Llava Next Video, un Trasformatore progettato per l’elaborazione di lunghe sequenze video. I video contengono intrinsecamente grandi quantità di dati ridondanti, come fotogrammi ripetuti o variazioni minori che forniscono poche informazioni aggiuntive.
I NAMM hanno identificato ed eliminato automaticamente questi fotogrammi ridondanti durante l’inferenza, comprimendo efficacemente la finestra di contesto senza compromettere la capacità del modello di interpretare il contenuto video.
Ad esempio, i NAMM conservavano i fotogrammi con dettagli visivi chiave, come modifiche delle azioni, interazioni degli oggetti o eventi critici, rimuovendo i fotogrammi ripetitivi o statici. Ciò ha comportato una migliore efficienza di elaborazione, consentendo al modello di concentrarsi sugli elementi visivi più rilevanti, mantenendo così la precisione e riducendo i costi computazionali.
Nell’apprendimento per rinforzo, i NAMM sono stati applicati ai Decision Transformer, un modello progettato per elaborare sequenze di azioni, osservazioni e ricompense per ottimizzare il processo decisionale compiti. I compiti di apprendimento per rinforzo spesso comportano lunghe sequenze di input con diversi livelli di rilevanza, in cui azioni non ottimali o ridondanti possono ostacolare le prestazioni.
I NAMM hanno affrontato questa sfida rimuovendo selettivamente i token corrispondenti ad azioni inefficienti e informazioni di scarso valore, pur mantenendo quelli fondamentali per ottenere risultati migliori.
Ad esempio, in attività come Hopper e Walker2d, che prevede il controllo di agenti virtuali in continuo movimento, i NAMM hanno migliorato le prestazioni di oltre il 9%. Filtrando movimenti non ottimali o dettagli non necessari, il Decision Transformer ha ottenuto un apprendimento più efficiente ed efficace, concentrando la sua potenza computazionale su decisioni che massimizzavano il successo nell’attività.
Questi risultati evidenziano l’adattabilità dei NAMM in domini molto diversi. Sia che si tratti di elaborare fotogrammi video in modelli visivi o di ottimizzare sequenze di azioni nell’apprendimento per rinforzo, i NAMM hanno dimostrato la loro capacità di migliorare le prestazioni, ridurre l’utilizzo delle risorse e mantenere l’accuratezza del modello, il tutto senza riqualificazione.
I NAMM imparano a dimenticare quasi esclusivamente le parti di fotogrammi video ridondanti, piuttosto che di token linguistici che descrivono il messaggio finale, osserva il documento, evidenziando l’adattabilità dei NAMM.
Supporti tecnici di NAMM
L’efficienza e l’efficacia dei modelli di memoria di attenzione neurale (NAMM) risiedono nel loro processo di esecuzione semplificato e sistematico, che consente una precisa potatura dei token senza intervento manuale. Questo processo si basa su tre componenti principali: spettrogrammi di attenzione, compressione delle funzionalità e punteggio automatizzato.
I NAMM regolano dinamicamente il loro comportamento in base ai requisiti dell’attività e alla profondità del livello Transformer. I primi livelli danno priorità al contesto “globale” come le descrizioni delle attività, mentre i livelli più profondi mantengono i dettagli specifici delle attività “locali”. Nelle attività di codifica, ad esempio, i NAMM scartavano commenti e codice standard; nelle attività di linguaggio naturale, hanno eliminato le ridondanze grammaticali mantenendo i contenuti chiave.
Questa conservazione adattiva dei token garantisce che i modelli rimangano concentrati sulle informazioni pertinenti durante tutta l’elaborazione, migliorando velocità e precisione.
Il primo il passaggio prevede la generazione di spettrogrammi di attenzione. I trasformatori calcolano i”valori di attenzione”a ogni livello per determinare l’importanza relativa di ciascun token all’interno della finestra di contesto. I NAMM trasformano questi valori di attenzione in rappresentazioni basate sulla frequenza utilizzando la Short-Time Fourier Transform (STFT).
STFT è una tecnica di elaborazione del segnale ampiamente utilizzata che scompone una sequenza in componenti di frequenza localizzate nel tempo, fornendo una rappresentazione compatta ma dettagliata dell’importanza del token. Applicando STFT, i NAMM convertono le sequenze di attenzione grezza in simili a spettrogrammi dati, consentendo un’analisi più chiara di quali token contribuiscono in modo significativo all’output del modello.
Successivamente, viene applicata la Feature Compression per ridurre la dimensionalità dei dati dello spettrogramma preservandone i dati essenziali Ciò si ottiene utilizzando una media mobile esponenziale (EMA), un metodo matematico che comprime i modelli di attenzione storici in un riepilogo compatto e di dimensioni fisse. EMA garantisce che le rappresentazioni rimangano leggere e gestibili, consentendo ai NAMM di analizzare in modo efficiente lunghe sequenze di attenzione riducendo al minimo il sovraccarico computazionale.
Il passaggio finale è Scoring and Pruning, dove i NAMM utilizzano un leggero classificatore di reti neurali per valutare le rappresentazioni dei token compressi e assegnare punteggi in base alla loro importanza. I token con punteggi inferiori a una soglia definita vengono eliminati dalla finestra di contesto,”dimenticando”di fatto dettagli inutili o ridondanti. Questo meccanismo di punteggio consente ai NAMM di dare priorità ai token critici che contribuiscono al processo decisionale del modello scartando i dati meno rilevanti.
Ciò che rende i NAMM particolarmente efficaci è il fatto che si affidano all’ottimizzazione evolutiva per perfezionare questo processo. I metodi di ottimizzazione tradizionali come la discesa del gradiente faticano compiti non differenziabili, come decidere se un token deve essere conservato o scartato.
Invece, i NAMM utilizzano un algoritmo evolutivo iterativo, ispirato alla selezione naturale, per”mutare”e”selezionare”la memoria più efficiente. strategie di gestione nel tempo. Attraverso prove ripetute, il sistema si evolve per dare automaticamente la priorità ai token essenziali, raggiungendo un equilibrio tra prestazioni ed efficienza della memoria senza richiedere la messa a punto manuale.
Questa combinazione di esecuzione semplificata. L’analisi dei token basata su spettrogramma, la compressione efficiente e l’eliminazione automatizzata consentono ai NAMM di offrire risparmi significativi di memoria e miglioramenti delle prestazioni in diverse attività basate su Transformer. Riducendo i requisiti computazionali mantenendo o migliorando la precisione, i NAMM stabiliscono un nuovo punto di riferimento per la gestione efficiente della memoria nei moderni modelli di intelligenza artificiale.
Cosa verrà dopo per i Transformers?
Sakana AI ritiene che i NAMM siano solo l’inizio. Mentre il lavoro attuale si concentra sull’ottimizzazione dei modelli pre-addestrati al momento dell’inferenza, la ricerca futura potrebbe integrare i NAMM nel processo di formazione stesso. Ciò potrebbe consentire ai modelli di apprendere strategie di gestione della memoria in modo nativo, estendendo ulteriormente la lunghezza delle finestre di contesto e aumentando l’efficienza tra i domini.
“Questo lavoro ha appena iniziato a esplorare lo spazio di progettazione dei nostri modelli di memoria, che prevediamo potrebbe offrire molte nuove opportunità per far avanzare le future generazioni di trasformatori”, conclude il team.
La comprovata capacità dei NAMM di scalare le prestazioni, ridurre i costi e adattarsi a diverse modalità stabilisce un nuovo standard per l’efficienza dei trasformatori su larga scala Modelli di intelligenza artificiale.