Raksasa infrastruktur web Cloudflare telah meluncurkan pembaruan besar ke buku aturan tiga dekade internet untuk perayap web.
Perusahaan telah memperkenalkan”Kebijakan Sinyal Konten,”perpanjangan baru untuk `robots.txt` file yang memberikan pemilik situs web. Penerbit dan perusahaan AI, membahas kekhawatiran luas atas pengikisan data yang tidak dikompensasi yang mengancam model ekonomi web terbuka.

Ini telah menciptakan”masalah pengendara bebas”klasik, di mana raksasa teknologi membangun produk berharga menggunakan konten penerbit tanpa menyediakan lalu lintas rujukan atau kompensasi yang secara tradisional menerbitkan media online.
Trendel ini merupakan sumber alarm yang berkembang secara tradisional. CEO News/Media Alliance Danielle Coffey baru-baru ini menangkap frustrasi industri, menyatakan, “Tautan adalah kualitas penebusan terakhir pencarian yang memberikan lalu lintas dan pendapatan kepada penerbit. Sekarang Google hanya mengambil konten dengan paksa dan menggunakannya tanpa pengembalian.”
Penyebaran ini telah memicu gelombang mikro yang berpenampilan tinggi untuk tuntutan mikro, dengan organisasi seperti New York Times untuk mendapatkan gelombang mikro untuk tuntutan mikro, dengan organisasi seperti New York Times untuk mendapatkan gelombang mikrosoft untuk tuntutan mikro, dengan organisasi New York Times.
Konflik bukan hanya legal tetapi teknis. Banyak perusahaan AI telah dituduh mengabaikan `robots.txt` sama sekali. Cloudflare sendiri baru-baru ini menuduh AI kebingungan menggunakan”crawler siluman”untuk memotong blok penerbit, klaim kebingungan yang ditolak dengan keras. Perselisihan ini menggarisbawahi ketidakcukupan sistem kehormatan lama.
Bagaimana Konten Baru Sinyal Kebijakan Kerja
Konten CloudFlare menandakan kebijakan kebijakan untuk memodernisasi sistem ini dengan menambahkan lapisan spesifisitas baru. Ini bekerja dengan mengintegrasikan komentar yang dapat dibaca manusia dan arahan baru yang dapat dibaca mesin secara langsung ke dalam file `robots.txt` situs.
Tujuannya adalah untuk menciptakan standar yang tidak ambigu untuk bagaimana crawler dapat menggunakan konten setelah mengaksesnya, perbedaan protokol asli tidak pernah dibuat. Kebijakan ini memperkenalkan tiga sinyal berbeda.
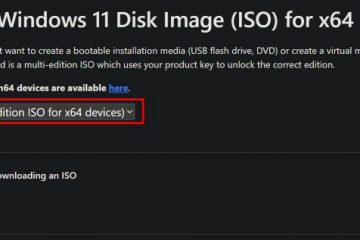
Sinyal `pencarian` memungkinkan konten untuk digunakan untuk membangun indeks pencarian tradisional, termasuk hyperlink dan kutipan pendek, tetapi secara eksplisit tidak termasuk ringkasan yang dihasilkan AI. Sinyal `AI-input` mengatur penggunaan waktu nyata dalam jawaban AI generatif, seperti Generasi Pengambilan-Pengambilan (RAG). Akhirnya, sinyal `ai-train` mengontrol apakah konten dapat digunakan untuk melatih atau menyempurnakan model AI. Operator situs web dapat mengekspresikan preferensi mereka dengan baris sederhana dan terbatas koma, seperti `sinyal konten: search=ya, ai-train=tidak`.
A”ya”memberikan izin, sementara”tidak”melarangnya. Yang terpenting, jika suatu sinyal dihilangkan, kebijakan tersebut menyatakan bahwa pemilik situs web Tidak ada hibah atau membatasi izin , meninggalkan opsi netral. Untuk mendorong adopsi, CloudFlare telah merilis kebijakan di bawah lisensi CC0 dan menyediakan alat generator di ContentSignals.org
untuk memberikan lebih banyak kebijakan, cloudflare yang disediakan. Petunjuk Hak Cipta.
Ini memposisikan arahan tidak hanya sebagai permintaan yang sopan tetapi sebagai deklarasi yang signifikan secara hukum dari niat penerbit.
Untuk mempercepat adopsi, CloudFlare telah secara otomatis mengaktifkan kebijakan untuk lebih dari 3,8 juta domain menggunakan fitur `robots.txt` yang dikelola` yang dikelola `TTX. `ai-train=tidak`. Perusahaan dengan sengaja meninggalkan sinyal `AI-input` netral dalam peluncuran ini, menyatakan tidak ingin menebak preferensi pelanggannya untuk kasus penggunaan spesifik itu. Langkah ini secara efektif menciptakan opt-outs skala web besar untuk pelatihan AI secara default.
Conundum kepatuhan dan pertanyaan Google
Sementara langkah yang signifikan, keberhasilan kebijakan tersebut bergantung pada kepatuhan sukarela. Seperti protokol asli, sinyal konten adalah penasihat dan tidak dapat ditegakkan secara teknis.
Beberapa aktor buruk mungkin mengabaikan aturan baru. Inilah sebabnya mengapa CloudFlare membingkai kebijakan sebagai”reservasi hak,”memperkuat posisi hukum penerbit.
Inisiatif ini adalah yang terbaru dalam pertahanan Cloudflare yang meningkat untuk penerbit. Perusahaan sebelumnya meluncurkan”AI Labyrinth,”sebuah alat untuk menjebak bot yang tidak patuh pada labirin konten palsu, dan sedang menguji”bayar per merangkak”untuk membiarkan situs mengenakan biaya untuk akses.
CEO Cloudflare, saya tidak dapat berhenti dengan penegakan,”Anda memberi tahu saya,”Anda tidak dapat menghentikan beberapa pangeran dengan penegakan,”Anda memberi tahu saya. tetap Google. Kesaksian Selama Landmark US v. Google Antitrust Trial mengungkapkan perusahaan menggunakan sistem opt-out terpisah untuk produk pencarian intinya dan model Gemini AI-nya.
Seorang eksekutif Google Deepmind mengkonfirmasi bahwa konten yang dipilih keluar dari pelatihan Gemini-untuk penggunaan”PERKOP AKTIVER”. Blokir fitur AI Google dan risiko kehilangan lalu lintas pencarian vital, atau memungkinkan penggunaan konten di seluruh papan.
Sampai pemain utama seperti Google mengadopsi standar baru atau menawarkan kontrol yang lebih jelas dan terpadu, penerbit akan tetap terperangkap di antara visibilitas dan kontrol, dan pertempuran untuk masa depan web akan berlanjut.