Selama bertahun-tahun, penelitian kecerdasan buatan telah didominasi oleh perusahaan yang menuangkan miliaran ke dalam model AI besar-besaran, dengan asumsi bahwa kekuatan komputasi semata-mata akan membuat mereka tetap di depan. Tetapi proyek baru dari Stanford University dan University of Washington menantang keyakinan itu.
Model terbaru mereka, S1, dilatih dengan biaya komputasi kurang dari $ 50, namun berkinerja kompetitif dengan penalaran model AI yang dikembangkan oleh Openai oleh Openai dan Deepseek.
Tidak seperti model berpemilik yang membutuhkan infrastruktur yang luas dan pelatihan berbulan-bulan, S1 disesuaikan dalam waktu kurang dari 30 menit dengan hanya menggunakan 16 gpus NVIDIA H100, menurut para peneliti.
terkait yang memeluk wajah menggunakan openai dengan Openai dengan Openice dengan Openice dengan Openice yang mendalam dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai dengan Openai./p>
Kode, metodologi, dan datasetnya telah tersedia melalui Repositori github open-source , membuatnya dapat diakses bagi siapa pun untuk memeriksa, mereplikasi, atau meningkatkan. Proyek ini menimbulkan pertanyaan penting untuk industri AI: apakah anggaran multi-miliar dolar masih diperlukan untuk bersaing di level tertinggi?
model yang menempatkan OpenAi dan strategi AI Google dalam risiko
Raksasa AI seperti OpenAi, Google, dan Microsoft sangat bertaruh pada kemampuan mereka untuk mengalahkan pesaing dalam pelatihan dan infrastruktur model AI. dirancang dengan mempertimbangkan keunggulan ini. Namun, pengembangan S1 membuktikan bahwa kemampuan penalaran tingkat tinggi dapat direplikasi dengan sebagian kecil dari biaya.
Tim peneliti di belakang S1 menggunakan teknik yang disebut distilasi, di mana model yang lebih kecil dilatih untuk meniru tanggapan dari sistem AI yang lebih besar.
Alih-alih mengembangkan model AI dari awal, mereka mengambil QWEN2.5-32B-instruct, model yang tersedia secara bebas dari laboratorium AI Qwen Alibaba, dan disesuaikan dengan menggunakan 1.000 dengan hati-hati dipilih dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan cermat dengan hati-hati pertanyaan matematika dan penalaran.
Khususnya, dataset dihasilkan menggunakan model eksperimental pemikiran flash Google Gemini 2.0. Seperti yang dinyatakan dalam makalah penelitian S1 , “Kami membangun S1K, yang terdiri dari 1.000 pertanyaan yang dikuratori dengan hati-hati dipasangkan dengan penalaran dengan penalaran dengan penalaran dengan penalaran dengan cermat dipasangkan dengan penalaran dengan hati-hati dipasangkan dengan penalaran dengan cermat jejak dan jawaban yang disuling dari eksperimental pemikiran gemini.”
terkait: Google merilis Gemini 2.0 Pro Experimental dan model AI flash-lite 2.0 baru
saat Google menyediakan Google Akses API gratis ke model ini, Ketentuan Layanannya melarang menggunakan outputnya untuk mengembangkan model AI yang bersaing. Model
Meskipun dilatih pada dataset yang relatif kecil, S1 mencapai tingkat kinerja yang sebanding dengan model Openai dan Deepseek.
Pada tolok ukur AIME24, yang mengukur masalah matematika AI-Kemampuan Memecahkan, S1 mencapai skor akurasi 56,7%, mengungguli preview O1 Openai, yang mencetak 44,6%. , model ini menunjukkan beberapa keterbatasan dalam pengetahuan ilmiah yang lebih luas. Pada tolok ukur GPQA-Diamond, yang berisi masalah fisika, biologi, dan kimia tingkat lanjut, S1 mencetak 59,6%, tertinggal di belakang model OpenAI dan Google.
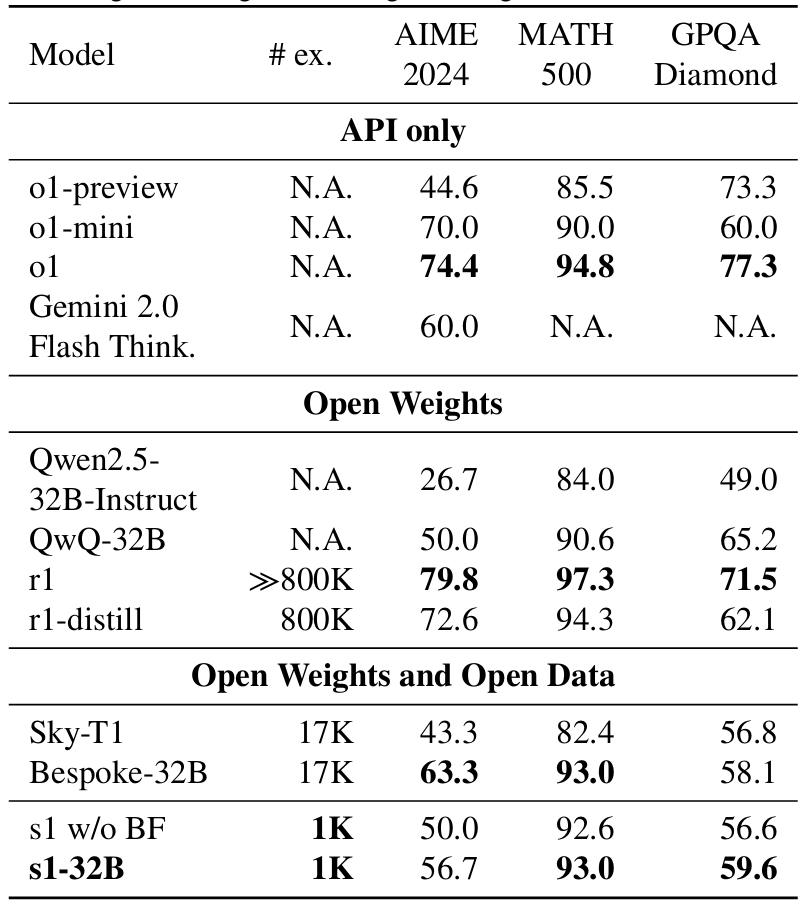 s1 model performance benchmarks compared to leading AI models from Google dan OpenAi
s1 model performance benchmarks compared to leading AI models from Google dan OpenAi
Namun, untuk model yang dilatih dalam waktu kurang dari 30 menit dengan komputasi minimal, hasil ini menantang asumsi bahwa kumpulan data yang lebih besar dan siklus pelatihan yang lebih lama selalu diperlukan.
trik yang tidak terduga yang tidak terduga bahwa itu yang tidak terduga bahwa itu yang tidak terduga bahwa itu yang tidak terduga bahwa itu yang tidak terduga bahwa itu yang tidak terduga bahwa itu yang tidak terduga bahwa itu yang tidak terduga bahwa itu itu yang tidak terduga bahwa itu yang tidak terduga bahwa itu yang tidak terduga bahwa itu yang tak terduga yang itu terduga bahwa itu yang tidak terduga bahwa itu yang tak terduga yang itu Meningkatkan penalaran AI
Penelitian ini juga mengungkapkan temuan tak terduga yang meningkatkan akurasi S1. Alih-alih memodifikasi model itu sendiri, mereka bereksperimen dengan cara yang disusun.’Tunggu’beberapa kali untuk generasi model ketika mencoba untuk berakhir. Ini dapat menyebabkan model untuk memeriksa ulang jawabannya, sering kali memperbaiki langkah-langkah penalaran yang salah.”
Cukup menambahkan kata”tunggu”ke dalam prompt paksa S1 untuk menghabiskan lebih banyak waktu mempertimbangkan responsnya sebelum menyelesaikan jawaban. Pendekatan ini selaras dengan penelitian terbaru tentang penskalaan waktu tes , di mana model meningkatkan akurasi dengan mengalokasikan Lebih banyak perhitungan untuk tugas-tugas kompleks daripada merespons secara instan.
Bisakah OpenAi dan Google mulai mengunci model AI mereka?
Munculnya penalaran AI berbiaya rendah rendah Model seperti S1 menghadirkan tantangan bagi perusahaan yang telah berinvestasi besar-besaran dalam sistem AI eksklusif.
Openai dan Google berpendapat bahwa membangun model AI yang andal dan aman memerlukan sumber daya komputasi yang signifikan, membenarkan layanan AI premium mereka dan kebijakan akses yang membatasi mereka.
Namun, karena lebih banyak peneliti menunjukkan bahwa kemampuan AI tingkat tinggi dapat direplikasi dengan murah, perusahaan-perusahaan ini mungkin mencari cara baru untuk melindungi model mereka agar tidak direkayasa terbalik atau disuling menjadi pesaing yang lebih kecil.
Openai telah menunjukkan tanda-tanda pengetatan akses ke teknologinya. Perusahaan saat ini membatasi fitur penelitian mendalam untuk pengguna ChatGPT Pro berbayar, membatasi kemampuan pengembang AI eksternal untuk mempelajari metodenya. Google, sementara itu, memberlakukan batasan tingkat yang ketat pada akses ke API Gemini 2.0 dan secara eksplisit melarang pelatihan model AI yang bersaing menggunakan outputnya.
Dengan proyek-proyek seperti S1 yang muncul, ada kemungkinan yang berkembang bahwa perusahaan akan menerapkan teknik watermarking watermarking atau pembatasan hukum untuk mencegah output yang dihasilkan AI mereka digunakan untuk melatih sistem lain. Namun, menegakkan aturan-aturan ini dalam lingkungan penelitian AI open-source akan sangat sulit.
Masa Depan AI: Penelitian Terbuka atau Kontrol Perusahaan?
Sebagai Penelitian AI terus maju, pertempuran antara inovasi open-source dan pengembangan AI berpemilik menjadi lebih intens. Keberhasilan model AI suling seperti S1 dan Sky-t1 menunjukkan bahwa kemampuan AI tidak lagi eksklusif untuk raksasa teknologi.
Perusahaan AI utama berpendapat bahwa model kepemilikan memberikan kontrol yang lebih baik atas risiko AI, memastikan keselamatan, pengurangan bias, dan kepatuhan peraturan. Tetapi peneliti independen membantah bahwa model open-source meningkatkan transparansi, memungkinkan para ahli untuk mengaudit dan memperbaiki sistem AI tanpa pengaruh perusahaan.
Pemerintah dan regulator juga mengamati perkembangan ini. Pembuatan kebijakan AI sejauh ini berfokus pada pemerintahan model skala besar, tetapi munculnya teknik replikasi AI berbiaya rendah dapat menggeser percakapan ke pembatasan akses data dan pertimbangan etis.
Pelepasan S1 menandakan pergeseran itu bisa membentuk kembali industri AI. Jika penalaran yang kuat AI dapat direplikasi dengan harga di bawah $ 50, tim peneliti dan startup AI yang lebih kecil mungkin akan segera memiliki kemampuan untuk bersaing dengan perusahaan AI miliaran dolar.
Untuk saat ini, S1 tetap open-source, yang berarti peneliti di seluruh dunia dapat menguji, memodifikasi, dan memperluas kemampuannya. Namun, jika Openai, Google, dan Laboratorium AI lainnya melihat ini sebagai ancaman, mereka dapat mendorong kontrol akses API yang lebih ketat, pembatasan lisensi, atau bahkan tindakan hukum terhadap metode penyulingan AI.
Akankah masa depan akan ditentukan Dengan model yang dikendalikan oleh perusahaan, model hak milik, atau akankah penelitian AI terus maju, membuat penalaran AI tingkat tinggi dapat diakses oleh semua orang? Beri tahu kami di komentar apa yang Anda pikirkan.