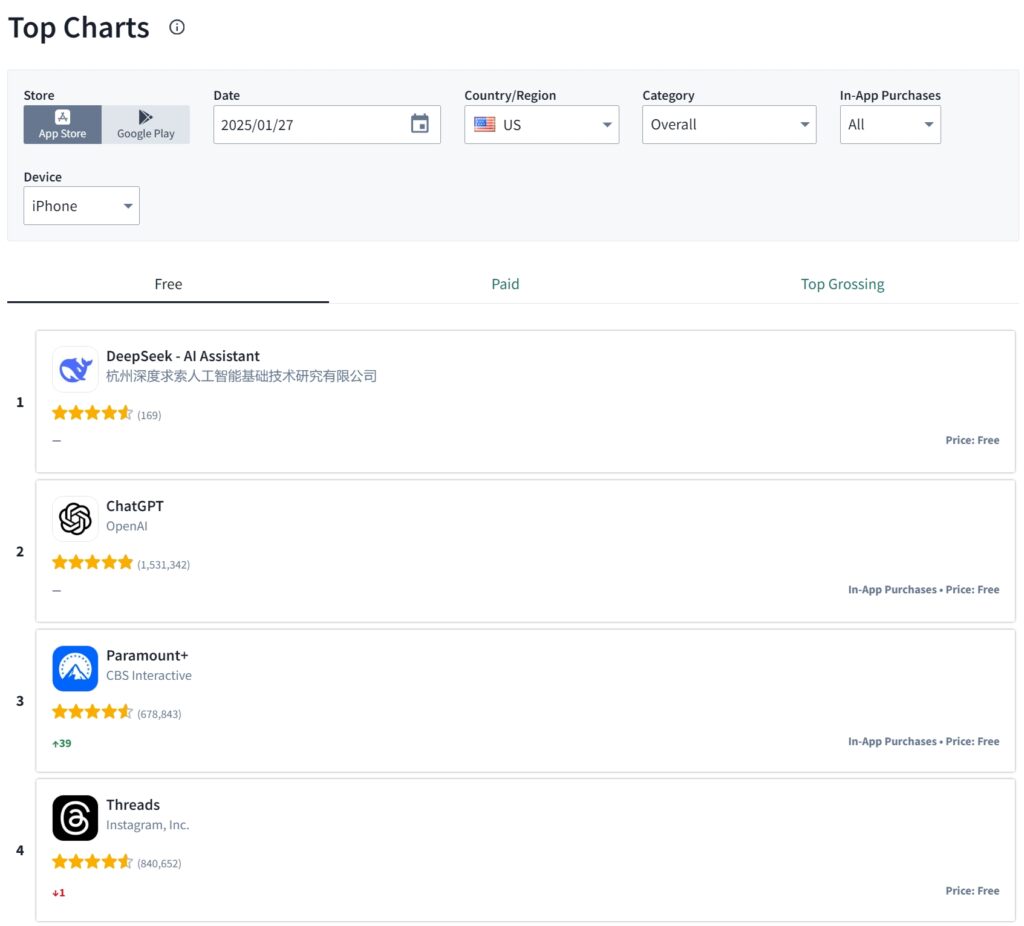
DeepSeek, sebuah perusahaan rintisan kecerdasan buatan Tiongkok, menduduki posisi teratas di App Store Apple AS akhir pekan lalu, melampaui ChatGPT OpenAI dalam hal unduhan.
Pencapaian ini terjadi setelah peluncuran model penalaran andalan DeepSeek, R1 pada tanggal 20 Januari, yang dengan cepat mendapatkan pengakuan atas kemampuannya untuk menyaingi sistem AI canggih sambil beroperasi dengan sumber daya yang sangat sedikit yang biasanya dibutuhkan.
 Sumber: Menara Sensor
Sumber: Menara Sensor
DeepSeek R1 memberikan kinerja terdepan, sekaligus disensor menurut aturan PKC.
Peningkatan pesat aplikasi yang didukung R1 mencerminkan rekayasa inovatif DeepSeek dan penggunaan strategis GPU Nvidia H800, yang dilarang untuk diekspor ke Tiongkok karena sanksi AS.
Terkait: Mengapa Sanksi AS Sulit Membatasi Pertumbuhan Teknologi Tiongkok
Dengan mengembangkan metode pelatihan yang efisien, perusahaan yang berbasis di Hangzhou ini telah menunjukkan bahwa kemajuan AI adalah hal yang penting. mungkin bahkan di bawah kendala geopolitik. Perkembangan ini menantang persepsi dominasi AS dalam kecerdasan buatan dan menimbulkan pertanyaan tentang efektivitas pembatasan ekspor yang bertujuan membatasi kemampuan teknologi Tiongkok.
Membangun AI dalam Pembatasan: Pendekatan yang Cerdas
Model R1 DeepSeek dilatih hanya menggunakan 2.048 GPU Nvidia H800 dengan total biaya di bawah $6 juta, menurut makalah penelitian yang dirilis perusahaan pada bulan Desember 2024.
GPU ini sengaja dibatasi versi chip H100 yang digunakan oleh perusahaan AS seperti OpenAI dan Meta. Terlepas dari keterbatasan perangkat keras, para insinyur DeepSeek mengembangkan teknik pengoptimalan baru yang memungkinkan R1 mencapai hasil yang sebanding dengan model yang dilatih pada infrastruktur yang jauh lebih kuat.
Pendiri Liang Wenfeng, mantan manajer dana lindung nilai, menjelaskan pendekatan perusahaan selama wawancara dengan 36Kr. “Kita perlu mengonsumsi daya komputasi empat kali lebih banyak untuk mencapai efek yang sama,”
Terkait: Model Bahasa Vision Seri VL2 DeepSeek AI Open Sources
Liang mengatakan, “Apa yang perlu kita lakukan adalah terus mempersempit kesenjangan ini.” Pandangan ke depan Liang dalam menimbun GPU Nvidia sebelum pembatasan di AS diberlakukan merupakan faktor penting dalam kemampuan perusahaan untuk berinovasi dalam keadaan yang penuh tantangan.
Para insinyur DeepSeek juga berfokus pada pengurangan penggunaan memori dan overhead komputasi, sehingga memungkinkan akurasi tinggi meskipun ada kendala perangkat keras. Dimitris Papailiopoulos, peneliti utama di laboratorium AI Frontiers Microsoft, menyoroti efisiensi desain R1.
“Mereka bertujuan untuk mendapatkan jawaban yang akurat dibandingkan merinci setiap langkah logis, sehingga secara signifikan mengurangi waktu komputasi sekaligus mempertahankan tingkat efektivitas yang tinggi,” katanya kepada MIT Technology Review.
Kinerja Tolok Ukur dan Pengakuan Industri
Kinerja R1 sangat kuat pada tolok ukur teknis, memperoleh skor 97,3% pada MATH-500 dan 79,8% pada AIME 2024. Hasil ini menempatkan R1 di samping seri o1 OpenAI, yang menunjukkan bahwa model DeepSeek yang hemat sumber daya dapat bersaing dengan para pemimpin industri.
Di luar model andalannya, DeepSeek juga telah merilis versi R1 yang lebih kecil yang mampu berjalan pada perangkat keras tingkat konsumen. Aksesibilitas ini telah memperluas daya tarik model ini di kalangan pengembang, pendidik, dan penghobi. Di media sosial, pengguna telah berbagi contoh R1 yang menangani tugas-tugas kompleks seperti pengembangan web, pengkodean, dan pemecahan masalah matematika tingkat lanjut.
Terkait: Mistral AI Debutkan Pixtral 12B untuk Pemrosesan Teks dan Gambar
Prestasi DeepSeek telah menuai pujian dari tokoh-tokoh terkemuka di bidang AI. Yann LeCun, Kepala Ilmuwan AI Meta, menekankan peran kolaborasi sumber terbuka dalam kesuksesan DeepSeek. ““DeepSeek mendapat keuntungan dari penelitian terbuka dan sumber terbuka (misalnya, PyTorch dan Llama dari Meta). Mereka memunculkan ide-ide baru dan membangunnya di atas karya orang lain.”tulis LeCun di LinkedIn. Karena karya mereka dipublikasikan dan open source, semua orang bisa mendapatkan keuntungan darinya. Itulah kekuatan penelitian terbuka dan open source.”
Demikian pula, Marc Andreessen, salah satu pendiri Andreessen Horowitz, menggambarkan R1 sebagai “salah satu terobosan paling menakjubkan yang pernah saya lihat.”Dukungan ini menyoroti dampak global dari pendekatan cerdas DeepSeek terhadap AI pengembangan.
Keterjangkauan dan Etos Sumber Terbuka
Tidak seperti platform berpemilik seperti ChatGPT OpenAI, DeepSeek menganut filosofi sumber terbuka yang dibuat oleh perusahaan bobot model R1, resep pelatihan, dan dokumentasi tersedia untuk umum, sehingga memungkinkan pengembang di seluruh dunia untuk mereplikasi atau mengembangkan pekerjaannya. Transparansi ini telah membedakan DeepSeek dalam industri yang sering kali bersifat rahasia.
Keterjangkauan juga menjadi faktor kunci dalam popularitas R1. Aplikasi ini gratis untuk digunakan, dan harga akses API jauh lebih rendah dibandingkan penawaran pesaing. Strategi penetapan harga ini, dikombinasikan dengan kemampuan model yang kuat, telah menjadikan DeepSeek pilihan yang menarik bagi individu dan bisnis.
Terkait: LLaMA AI Under Fire – Apa yang Tidak Diungkapkan Meta Anda Tentang Model “Sumber Terbuka”
Implikasi Geopolitik dari Kesuksesan DeepSeek
Kebangkitan DeepSeek terjadi pada saat meningkatnya ketegangan geopolitik antara kedua negara Amerika Serikat dan Tiongkok, khususnya di bidang kecerdasan buatan.
Sejak tahun 2021, pemerintahan Biden telah memperluas pembatasan ekspor chip canggih ke Tiongkok, yang bertujuan untuk membatasi kemampuan negara tersebut dalam mengembangkan teknologi AI yang kompetitif. Namun, pencapaian DeepSeek menunjukkan bahwa langkah-langkah tersebut mungkin tidak sepenuhnya mencegah inovasi.
Keberhasilan perusahaan ini telah memicu perdebatan di kalangan teknologi AS tentang konsekuensi yang tidak diinginkan dari pengendalian ekspor. Beberapa eksekutif berpendapat bahwa pembatasan ini mungkin mendorong banyak akal inovasi di antara perusahaan-perusahaan Tiongkok. Strategi Liang dalam menimbun GPU dan berfokus pada efisiensi telah membuktikan bahwa kendala dapat memacu pemecahan masalah secara kreatif, bukan menghambatnya sepenuhnya.
Terkait: Aturan Ekspor Chip AI AS yang Baru Menghadapi Reaksi Industri oleh Nvidia dan Lainnya
Gerakan AI Tiongkok yang Lebih Luas
Pendekatan sumber terbuka DeepSeek sejalan dengan tren yang lebih luas di sektor AI Tiongkok. Perusahaan lain, termasuk Alibaba Cloud dan 01.AI milik Kai-Fu Lee, juga memprioritaskan inisiatif sumber terbuka dalam beberapa tahun terakhir. Liang telah menggambarkan perlunya mengatasi apa yang disebutnya sebagai “kesenjangan efisiensi”antara usaha AI Tiongkok dan Barat, dan menjelaskan bahwa perusahaan lokal sering kali memerlukan sumber daya dua kali lipat untuk mencapai hasil yang sebanding.
Terkait: Alibaba Qwen Merilis Model AI Penalaran Multimodal Pratinjau QVQ-72B
Pada bulan Juli 2024, Liang menyatakan, “Kami memperkirakan bahwa model dalam dan luar negeri terbaik mungkin memiliki kesenjangan satu kali lipat dalam struktur model dan dinamika pelatihan. Oleh karena itu, kita perlu mengonsumsi daya komputasi dua kali lebih banyak untuk mencapai efek yang sama. Selain itu, mungkin juga terdapat kesenjangan efisiensi data sebesar satu kali lipat, yang berarti kita perlu mengonsumsi data pelatihan dan data dua kali lebih banyak. daya komputasi untuk mencapai efek yang sama. Secara bersama-sama, kita perlu mengonsumsi daya komputasi empat kali lebih banyak. Yang perlu kita lakukan adalah terus mempersempit kesenjangan ini.”
Kepemimpinannya telah mendapatkan pengakuan DeepSeek baik di Tiongkok maupun internasional. Pada tahun 2024, ia diundang ke pertemuan tingkat tinggi dengan para pejabat Tiongkok untuk membahas strategi memajukan kemampuan AI negara tersebut.
Tantangan dan Peluang Masa Depan
Sebagai DeepSeek terus menyempurnakan modelnya, perusahaan menghadapi peluang dan tantangan. Meskipun pencapaiannya telah membuktikan kelayakan AI yang hemat sumber daya, masih ada pertanyaan tentang apakah pendekatan tersebut dapat bersaing dengan investasi besar-besaran dari raksasa teknologi seperti OpenAI dan Meta.
Dalam postingan setelah rilis DeepSeek R1 , Mark Zuckerberg, CEO Meta, menyoroti pentingnya investasi skala besar dalam infrastruktur AI, sambil berkata, “Ini akan menjadi tahun yang menentukan bagi AI. Pada tahun 2025, saya memperkirakan Meta AI akan menjadi asisten terdepan yang melayani lebih dari 1 miliar orang, Llama 4 akan menjadi model tercanggih, dan kami akan membangun insinyur AI yang akan mulai berkontribusi dalam jumlah kode yang semakin besar. untuk upaya Penelitian dan Pengembangan kami. Untuk mewujudkan hal ini, Meta sedang membangun pusat data berkapasitas 2GW+ yang sangat besar sehingga dapat mencakup sebagian besar wilayah Manhattan.
Kami akan menghadirkan komputasi online sebesar ~1GW pada tahun ’25 dan kami akan mengakhiri tahun ini dengan lebih dari 1,3 juta GPU. Kami berencana menginvestasikan $60-65 miliar dalam belanja modal tahun ini sembari mengembangkan tim AI kami secara signifikan, dan kami memiliki modal untuk terus berinvestasi di tahun-tahun mendatang. Ini merupakan upaya besar-besaran, dan dalam beberapa tahun mendatang hal ini akan mendorong produk dan bisnis inti kami, membuka inovasi bersejarah, dan memperluas kepemimpinan teknologi Amerika. Ayo kita membangun!”
Untuk saat ini, kesuksesan DeepSeek dengan R1 telah menunjukkan bahwa inovasi tidak hanya menjadi domain para pemain yang memiliki pendanaan paling besar. Dengan memprioritaskan efisiensi, transparansi, dan aksesibilitas, perusahaan telah membuat langkah besar. dampak jangka panjang pada industri AI global.