Microsoft telah memperkenalkan rStar-Math, yang merupakan kelanjutan dan penyempurnaan dari rStar framework, untuk mendorong batasan model bahasa kecil (SLM) dalam penalaran matematika.
Dirancang untuk menyaingi sistem yang lebih besar seperti o1-preview OpenAI, rStar-Math mencapai tolok ukur luar biasa dalam pemecahan masalah sekaligus menunjukkan bagaimana model kompak dapat bekerja pada tingkat kompetitif. Perkembangan ini menunjukkan pergeseran dalam prioritas AI, mulai dari peningkatan skala hingga optimalisasi kinerja untuk tugas-tugas tertentu.
Melanjutkan dari rStar ke rStar-Math
RStar kerangka kerja dari musim panas lalu meletakkan dasar untuk meningkatkan penalaran SLM melalui Monte Carlo Tree Search (MCTS), sebuah algoritma yang menyempurnakan solusi dengan mensimulasikan dan memvalidasi berbagai jalur.
rStar menunjukkan bahwa model yang lebih kecil dapat menangani tugas yang kompleks, namun penerapannya tetap bersifat umum. rStar-Math dibangun di atas fondasi ini dengan inovasi yang ditargetkan dan disesuaikan dengan penalaran matematika.
Pusat kesuksesan rStar-Math adalah metodologi rantai pemikiran (CoT) yang ditambah dengan kode, di mana model tersebut menghasilkan solusi dalam kedua hal tersebut. bahasa alami dan kode Python yang dapat dieksekusi.
Struktur keluaran ganda ini memastikan bahwa langkah-langkah penalaran perantara dapat diverifikasi, mengurangi kesalahan, dan menjaga konsistensi logis. Para peneliti menekankan pentingnya pendekatan ini, dengan menyatakan, “Konsistensi timbal balik mencerminkan praktik umum manusia ketika tidak ada pengawasan, di mana kesepakatan di antara rekan-rekan mengenai jawaban yang diturunkan menunjukkan kemungkinan kebenaran yang lebih tinggi.”
Terkait: Model Pratinjau R1-Lite DeepSeek Tiongkok Menargetkan Kepemimpinan OpenAI dalam Penalaran Otomatis
Selain CoT, rStar-Math memperkenalkan Model Preferensi Proses (PPM), yang mengevaluasi dan memberi peringkat pada tingkat menengah langkah-langkah berdasarkan kualitas. Tidak seperti sistem penghargaan tradisional yang sering mengandalkan data yang tidak jelas, PPM memprioritaskan koherensi logis dan akurasi, sehingga semakin meningkatkan keandalan model Nilai-Q masih belum cukup tepat untuk menilai setiap langkah penalaran meskipun telah menggunakan peluncuran MCTS yang ekstensif, nilai-Q dapat diandalkan untuk membedakan langkah-langkah positif (benar) dari langkah-langkah negatif (tidak relevan/salah).
Demikianlah pelatihan ini dilakukan. metode menyusun pasangan preferensi untuk setiap langkah berdasarkan nilai Q dan menggunakan kerugian peringkat berpasangan untuk mengoptimalkan prediksi skor PPM untuk setiap langkah penalaran, sehingga mencapai pelabelan yang andal. Pendekatan ini menghindari metode konvensional yang secara langsung menggunakan nilai-Q sebagai label imbalan, yang pada dasarnya bersifat berisik dan tidak tepat dalam penetapan imbalan secara bertahap.”
Terakhir, resep evolusi diri empat putaran yang secara progresif membangun batas-batas keduanya. model kebijakan dan PPM dari awal.
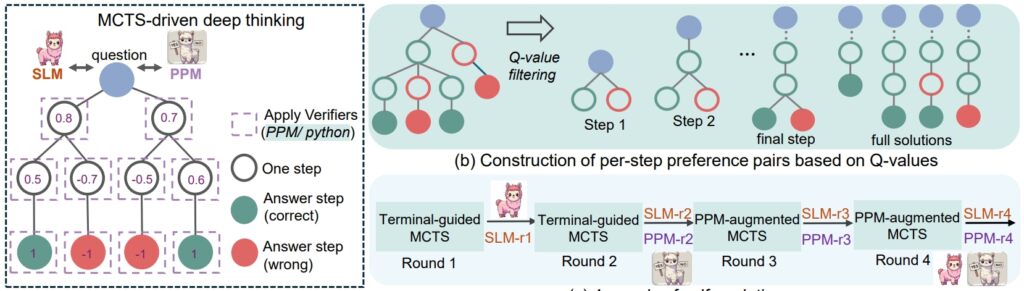 prosedur penalaran rSTar-Math (Sumber: makalah penelitian)
prosedur penalaran rSTar-Math (Sumber: makalah penelitian)
Kinerja yang Menantang Model yang Lebih Besar
rStar-Math menetapkan standar baru dalam tolok ukur penalaran matematis, mencapai hasil yang menyaingi, dan dalam beberapa kasus melampaui, sistem AI yang lebih besar
Pada set data GSM8K, tes untuk penalaran matematika, akurasi model 7 miliar parameter meningkat dari 12,51% menjadi 63,91% setelah mengintegrasikan rStar-Math href=”https://en.wikipedia.org/wiki/American_Invitational_Mathematics_Examination”>American Invitational Mathematics Examination (AIME), model ini menyelesaikan 53,3% soal, menempatkannya di antara 20% peserta sekolah menengah teratas.
Hasil kumpulan data MATH juga sama mengesankannya, dengan rStar-Math mencapai tingkat akurasi 90%, mengungguli o1-preview OpenAI.
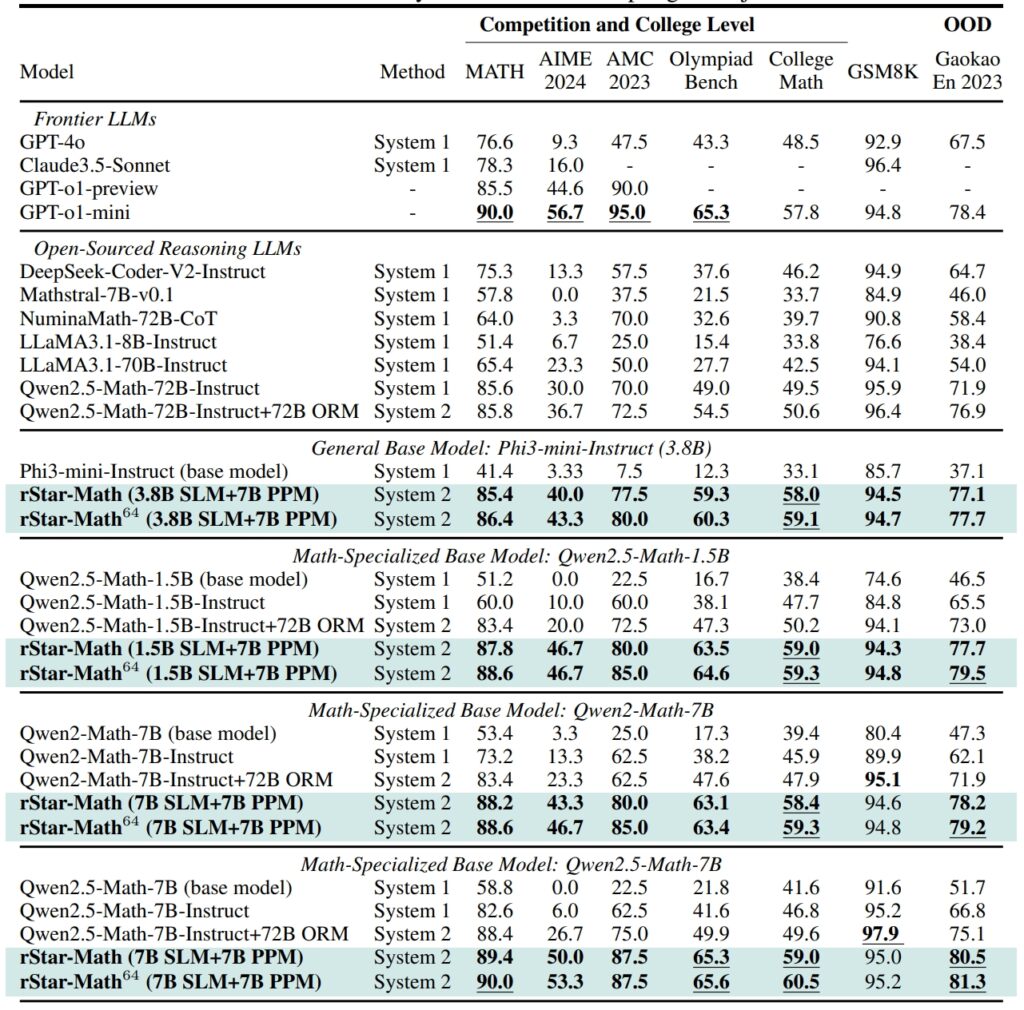 Kinerja rStar-Math dan LLM terdepan lainnya pada tolok ukur matematika paling menantang (Sumber: makalah penelitian)
Kinerja rStar-Math dan LLM terdepan lainnya pada tolok ukur matematika paling menantang (Sumber: makalah penelitian)
Pencapaian ini menyoroti kemampuan kerangka kerja yang memungkinkan SLM menangani tugas-tugas yang sebelumnya didominasi oleh model besar yang intensif sumber daya. Dengan menekankan konsistensi logis dan langkah-langkah perantara yang dapat diverifikasi, rStar-Math mengatasi salah satu tantangan AI yang paling sulit diatasi: memastikan penalaran yang andal di seluruh ruang masalah yang kompleks.
Inovasi Teknis yang Mendorong rStar-Math
Evolusi dari rStar ke rStar-Math memperkenalkan beberapa kemajuan penting. Integrasi MCTS tetap menjadi inti dari kerangka kerja ini, sehingga memungkinkan model untuk mengeksplorasi beragam jalur pemikiran dan memprioritaskan jalur yang paling menjanjikan.
Penambahan alasan CoT, dengan fokus pada verifikasi kode, memastikan bahwa keluaran dapat ditafsirkan dan akurat.
Terkait: QwQ-32B Alibaba-Pratinjau Bergabung dalam Pertarungan Penalaran Model AI dengan OpenAI
Mungkin yang paling transformatif adalah proses pelatihan evolusioner rStar-Math. Selama empat putaran berulang, kerangka kerja ini menyempurnakan model kebijakan dan PPM, dengan menggabungkan data pemikiran berkualitas lebih tinggi di setiap langkah.
Pendekatan berulang ini memungkinkan model untuk terus meningkatkan kinerjanya, mencapai hasil yang canggih tanpa bergantung pada penyulingan dari model yang lebih besar.
Membandingkan rStar-Math hingga OpenAI o1
Sementara Microsoft berfokus pada pengoptimalan model yang lebih kecil, OpenAI terus memprioritaskan peningkatan sistemnya.
o1 Pro Mode, yang diperkenalkan pada bulan Desember 2024 sebagai bagian dari ChatGPT Pro Plan, menawarkan kemampuan penalaran tingkat lanjut yang disesuaikan untuk aplikasi berisiko tinggi seperti pengkodean dan penelitian ilmiah. OpenAI melaporkan bahwa Mode Pro o1 mencapai tingkat akurasi 86% pada AIME dan tingkat keberhasilan 90% dalam tolok ukur pengkodean seperti Codeforces.
rStar-Math mewakili pergeseran dalam inovasi AI, menantang fokus industri pada model yang lebih besar sebagai sarana utama untuk mencapai penalaran maju. Dengan menyempurnakan SLM dengan pengoptimalan khusus domain, Microsoft menawarkan alternatif berkelanjutan yang mengurangi biaya komputasi dan dampak lingkungan.
Terkait: Penyelarasan yang Disengaja: Strategi Keamanan OpenAI untuk Model Berpikir o1 dan o3
Keberhasilan kerangka kerja ini dalam penalaran matematis membuka pintu untuk penerapan yang lebih luas, mulai dari pendidikan untuk penelitian ilmiah.
Para peneliti berencana untuk merilis kode dan data rStar-Math di GitHub, sehingga membuka jalan bagi kolaborasi dan pengembangan lebih lanjut. Transparansi ini mencerminkan pendekatan Microsoft untuk membuat alat AI berkinerja tinggi dapat diakses oleh khalayak yang lebih luas, termasuk institusi akademis dan organisasi skala menengah.
Terkait: SemiAnalisis: Tidak, Penskalaan AI Tidak Ada Tidak Melambat
Seiring dengan semakin ketatnya persaingan antara Microsoft dan OpenAI, kemajuan yang diperkenalkan oleh rStar-Math menyoroti potensi model yang lebih kecil untuk menantang dominasi sistem yang lebih besar. Dengan memprioritaskan efisiensi dan akurasi, rStar-Math menetapkan tolok ukur baru mengenai apa yang dapat dicapai oleh sistem AI kompak.