Google DeepMind telah meluncurkan FACTS Grounding, sebuah tolok ukur baru yang dirancang untuk menguji kemampuan model bahasa besar (LLM) dalam menghasilkan respons berbasis dokumen yang akurat secara faktual.
Tolok ukur ini, yang dihosting di Kaggle, bertujuan untuk mengatasi salah satu tantangan paling mendesak di dunia kecerdasan buatan: memastikan bahwa keluaran AI didasarkan pada data yang diberikan, dibandingkan mengandalkan pengetahuan eksternal atau menimbulkan halusinasi—informasi yang masuk akal namun salah.
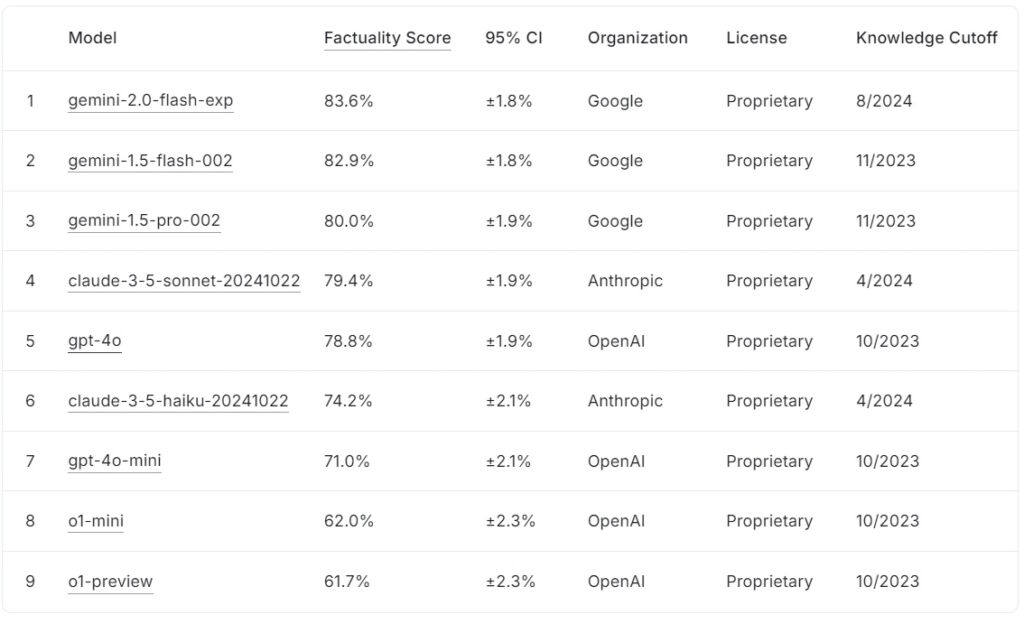
FACTS Grounding leaderboard saat ini memberi peringkat pada model bahasa besar berdasarkan skor faktualitasnya, dengan Google gemini-2.0-flash-exp memimpin dengan 83,6% diikuti oleh gemini-1.5-flash-002 dengan 82,9%, dan gemini-1.5-pro-002 sebesar 80,0%.
claude-3.5-sonnet-20241022 Antropis peringkat keempat dengan 79,4%, sedangkan OpenAI gpt-4o mencapai 78,8%, menempatkannya di posisi kelima. Di peringkat bawah, claude-3.5-haiku-20241022 Anthropic mendapat skor 74,2%, diikuti oleh gpt-4o-mini dengan skor 71,0%.
Model OpenAI yang lebih kecil, o1-mini dan o1-preview, melengkapi papan peringkat dengan 62,0% dan 61,7%, masing-masing.
 Sumber: Kaggle
Sumber: Kaggle
FACTS Landasan menonjol karena memerlukan respons jangka panjang yang menyatukan dokumen masukan terperinci, menjadikannya salah satu tolok ukur paling ketat untuk faktualitas AI hingga saat ini.
FAKTA Grounding mewakili perkembangan penting bagi industri AI, khususnya dalam aplikasi yang mengutamakan kepercayaan dan akurasi. Dengan mengevaluasi LLM di berbagai bidang seperti kedokteran, hukum, keuangan, ritel, dan teknologi, tolok ukur ini menetapkan landasan untuk meningkatkan keandalan AI dalam skenario dunia nyata.
Menurut tim peneliti DeepMind, “tolok ukur ini mengukur kemampuan LLM untuk menghasilkan respons yang didasarkan secara eksklusif pada konteks yang disediakan…bahkan ketika konteksnya bertentangan dengan pengetahuan pra-pelatihan.”
Dataset Untuk Kompleksitas Dunia Nyata
FACTS Grounding terdiri dari 1.719 contoh, yang dikurasi oleh anotator manusia untuk memastikan relevansi dan keragaman yang mencakup hingga 32.000 token, setara dengan sekitar 20.000 kata.
Setiap tugas menantang LLM untuk melakukan ringkasan, pembuatan Tanya Jawab, atau penulisan ulang konten, dengan instruksi ketat untuk hanya merujuk pada data yang disediakan kreativitas, penalaran matematis, atau interpretasi ahli, dengan fokus pada pengujian kemampuan model untuk mensintesis dan mengartikulasikan informasi yang kompleks.
Untuk menjaga transparansi dan mencegah overfitting, DeepMind memisahkan kumpulan data menjadi dua segmen: 860 contoh publik tersedia untuk penggunaan eksternal dan 859 contoh pribadi disediakan untuk evaluasi papan peringkat.
Struktur ganda ini menjaga integritas benchmark sekaligus mendorong kolaborasi dari pengembang AI di seluruh dunia. “Kami secara ketat mengevaluasi evaluator otomatis kami pada data pengujian yang disimpan untuk memvalidasi kinerja mereka dalam tugas kami,” catat tim peneliti, menyoroti desain cermat yang mendasari FACTS Grounding.
Menilai Akurasi dengan Rekan Model AI
Tidak seperti tolok ukur konvensional, FACTS Grounding menggunakan proses tinjauan sejawat yang melibatkan tiga LLM tingkat lanjut: Gemini 1.5 Pro, GPT-4o, dan Claude 3.5 Soneta. Model ini berfungsi sebagai juri, yang menilai tanggapan berdasarkan dua kriteria penting: kelayakan dan keakuratan faktual untuk landasan mereka pada materi sumber, dengan skor yang dikumpulkan dari ketiga model untuk meminimalkan bias.
Para peneliti DeepMind menekankan pentingnya evaluasi berlapis ini, dengan menyatakan, “Metrik yang berfokus pada mengevaluasi faktualitas teks yang dihasilkan… dapat dielakkan dengan mengabaikan maksud di balik permintaan pengguna. Dengan memberikan respons yang lebih singkat sehingga menghindari penyampaian informasi yang komprehensif…adalah mungkin untuk mencapai skor faktualitas yang tinggi namun tidak memberikan respons yang membantu.”
Penggunaan beberapa templat penilaian, termasuk pendekatan tingkat rentang dan berbasis JSON , selanjutnya memastikan keselarasan dengan penilaian manusia dan kemampuan beradaptasi terhadap beragam tugas.
Mengatasi Tantangan Halusinasi AI
Halusinasi AI adalah salah satu hambatan paling signifikan dalam penyebaran halusinasi adopsi LLM di Kesalahan ini, dimana model menghasilkan keluaran yang tampak masuk akal namun sebenarnya tidak benar, menimbulkan risiko serius dalam bidang seperti layanan kesehatan, analisis hukum, dan pelaporan keuangan.
FACTS Grounding secara langsung mengatasi masalah ini dengan menerapkan penegakan hukum yang ketat kepatuhan terhadap data masukan yang diberikan. Pendekatan ini tidak hanya mengevaluasi kemampuan model untuk menghindari kesalahan, namun juga memastikan bahwa keluaran tetap selaras dengan maksud pengguna.
Berbeda dengan tolok ukur seperti itu. SimpleQA OpenAI, yang mengukur faktualitas dalam pengambilan data pelatihan, FACTS Grounding menguji seberapa baik model mensintesis informasi baru.
Makalah penelitian menggarisbawahi perbedaan ini: “Memastikan keakuratan faktual sambil menghasilkan respons LLM merupakan sebuah tantangan. Tantangan utama dalam faktualitas LLM adalah pemodelan (yaitu arsitektur, pelatihan, dan inferensi) dan pengukuran (yaitu metodologi evaluasi, data, dan metrik).”
Tantangan Teknis dan Desain Tolok Ukur
Kompleksitas masukan jangka panjang menimbulkan tantangan teknis yang unik, khususnya dalam merancang metode evaluasi otomatis yang dapat menilai respons tersebut secara akurat
FACTS Grounding bergantung pada proses komputasi intensif untuk memvalidasi tanggapan, menerapkan kriteria yang ketat untuk memastikan keandalan. Dimasukkannya beberapa model juri mengurangi potensi bias dan memperkuat kerangka evaluasi secara keseluruhan.
Tim peneliti menyoroti pentingnya mendiskualifikasi jawaban yang tidak jelas atau tidak relevan, dengan menyatakan, “Mendiskualifikasi jawaban yang tidak memenuhi syarat tanggapan mengarah pada pengurangan…karena tanggapan ini dianggap tidak akurat.”Penegakan relevansi yang ketat ini memastikan bahwa model tidak diberi imbalan karena mengabaikan semangat tugas tersebut.
Mendorong Kolaborasi Melalui Transparansi
Keputusan DeepMind menjadi tuan rumah FACTS Grounding di Kaggle mencerminkan komitmennya untuk membina kolaborasi di seluruh industri AI. Dengan membuat segmen data publik dapat diakses, proyek ini mengundang peneliti dan pengembang AI untuk mengevaluasi model mereka berdasarkan standar yang kuat dan berkontribusi untuk memajukan tolok ukur faktualitas.
Pendekatan ini selaras dengan tujuan yang lebih luas yaitu transparansi dan kemajuan bersama dalam AI, memastikan bahwa peningkatan akurasi dan landasan tidak hanya terjadi pada satu organisasi saja.
Membedakan dari Organisasi Lainnya Tolok Ukur
FAKTA Landasan membedakan dirinya dari tolok ukur lainnya karena fokusnya pada landasan pada masukan yang baru diperkenalkan, bukan pada pengetahuan yang telah dilatih sebelumnya.
Sementara tolok ukur seperti SimpleQA OpenAI menilai seberapa baik model mengambil dan memanfaatkan informasi dari korpus pelatihannya, FACTS Grounding mengevaluasi model berdasarkan kemampuannya dalam mensintesis dan mengartikulasikan respons hanya berdasarkan data yang disediakan.
Pembedaan ini sangat penting dalam mengatasi tantangan yang ditimbulkan oleh prasangka model atau bias yang melekat. Dengan mengisolasi tugas pemrosesan input eksternal, FACTS Grounding memastikan bahwa metrik kinerja mencerminkan kemampuan model untuk beroperasi dalam skenario dunia nyata yang dinamis, bukan sekadar memuntahkan informasi yang telah dipelajari sebelumnya.
Seperti yang dijelaskan DeepMind dalam makalah penelitiannya, tolok ukur ini dirancang untuk mengevaluasi LLM berdasarkan kemampuannya mengelola kueri yang kompleks dan berdurasi panjang dengan dasar faktual, serta menyimulasikan tugas yang relevan dengan aplikasi dunia nyata.
Metode Alternatif untuk LLM Grounding
Beberapa metode menawarkan fitur grounding serupa dengan FACTS Grounding, masing-masing dengan kekuatan dan kelemahannya. Metode ini bertujuan untuk meningkatkan keluaran LLM dengan meningkatkan akses mereka terhadap informasi yang akurat atau menyempurnakan proses pelatihan dan penyelarasan mereka.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) meningkatkan keakuratan keluaran LLM dengan secara dinamis mengambil informasi relevan dari eksternal basis pengetahuan atau database dan menggabungkannya ke dalam respons model. Alih-alih melatih ulang seluruh LLM, RAG bekerja dengan mencegat permintaan pengguna dan memperkaya mereka dengan informasi terkini.
Penerapan RAG tingkat lanjut sering kali memanfaatkan pengambilan berbasis entitas, yaitu data yang terkait dengan entitas tertentu disatukan untuk memberikan konteks yang sangat relevan untuk respons LLM.
RAG biasanya menggunakan teknik penelusuran semantik untuk mengambil informasi. Dokumen atau fragmennya diindeks berdasarkan penyematan semantiknya, sehingga memungkinkan sistem mencocokkan kueri pengguna dengan entri yang paling relevan secara kontekstual. Pendekatan ini memastikan bahwa LLM menghasilkan respons berdasarkan data terbaru dan paling relevan.
Efektivitas RAG sangat bergantung pada kualitas dan pengorganisasian basis pengetahuan, serta ketepatan algoritme pengambilan. Sementara FACTS Grounding mengevaluasi kemampuan LLM untuk tetap berpegang pada dokumen konteks yang disediakan, RAG melengkapi hal ini dengan memungkinkan LLM memperluas pengetahuan mereka secara dinamis, mengambil dari sumber eksternal untuk meningkatkan faktualitas dan relevansi.
Peningkatan Pengetahuan
Distilasi pengetahuan melibatkan transfer kemampuan suatu model yang besar dan kompleks (disebut guru) ke model yang lebih kecil dan spesifik tugas (siswa). Metode ini meningkatkan efisiensi sekaligus mempertahankan sebagian besar keakuratan model aslinya. Dua pendekatan utama yang digunakan dalam penyulingan pengetahuan:
Penyulingan Pengetahuan Berbasis Respons: Berfokus pada replikasi keluaran model guru, memastikan model siswa menghasilkan hasil yang serupa untuk masukan yang diberikan.
Distilasi Pengetahuan Berbasis Fitur: Mengekstraksi representasi dan fitur internal dari model guru, memungkinkan model siswa mereplikasi wawasan yang lebih dalam.
Dengan menyempurnakan model yang lebih kecil , pengetahuan distilasi memungkinkan penerapan LLM di lingkungan dengan sumber daya terbatas tanpa kehilangan kinerja yang signifikan. Berbeda dengan FACTS Grounding, yang mengevaluasi fidelitas grounding, penyulingan pengetahuan lebih berkaitan dengan penskalaan kemampuan LLM dan mengoptimalkannya untuk tugas-tugas tertentu.
Penyempurnaan dengan Kumpulan Data Grounded
Penyempurnaan melibatkan adaptasi LLM yang telah dilatih sebelumnya untuk domain atau tugas tertentu dengan melatih mereka menggunakan kumpulan data pilihan yang mengutamakan landasan faktual. Misalnya, kumpulan data yang terdiri dari literatur ilmiah atau catatan sejarah dapat digunakan untuk meningkatkan kemampuan model dalam menghasilkan keluaran yang akurat dan spesifik pada domain tertentu. Teknik ini meningkatkan performa LLM untuk aplikasi khusus, seperti analisis dokumen medis atau hukum.
Namun, penyesuaian memerlukan banyak sumber daya dan berisiko menyebabkan bencana lupa, sehingga model kehilangan pengetahuan yang diperoleh selama pelatihan awalnya. FACTS Grounding berfokus pada pengujian faktualitas dalam konteks terisolasi, sedangkan fine-tuning berupaya meningkatkan kinerja dasar LLM di bidang tertentu.
Reinforcement Learning with Human Feedback (RLHF)
Pembelajaran Penguatan dengan Umpan Balik Manusia (RLHF) memasukkan preferensi manusia ke dalam proses pelatihan LLM. Dengan melatih model secara berulang untuk menyelaraskan tanggapannya dengan umpan balik manusia, RLHF menyempurnakan kualitas, faktualitas, dan kegunaan keluaran. Evaluator manusia menilai keluaran LLM, dan skor ini digunakan sebagai sinyal untuk mengoptimalkan model.
RLHF sangat berhasil dalam meningkatkan kepuasan pengguna dan memastikan respons yang dihasilkan selaras dengan harapan manusia. Sementara FACTS Grounding mengevaluasi landasan faktual terhadap dokumen tertentu, RLHF menekankan penyelarasan keluaran LLM dengan nilai-nilai dan preferensi kemanusiaan.
Mengikuti Instruksi dan Pembelajaran Dalam Konteks
Pembelajaran mengikuti instruksi dan dalam konteks melibatkan demonstrasi landasan untuk LLM melalui contoh yang dibuat dengan cermat dalam perintah pengguna. Metode ini mengandalkan kemampuan model untuk menggeneralisasi dari beberapa demonstrasi. Meskipun pendekatan ini dapat menghasilkan perbaikan yang cepat, pendekatan ini mungkin tidak mencapai tingkat kualitas dasar yang sama seperti metode penyesuaian atau berbasis pengambilan.
Alat dan API Eksternal
LLM dapat diintegrasikan dengan alat dan API eksternal untuk menyediakan akses real-time ke data eksternal, sehingga secara signifikan meningkatkan kemampuan landasannya. Contohnya meliputi:
Kemampuan Penjelajahan: Memungkinkan LLM mengakses dan mengambil informasi real-time dari web untuk menjawab pertanyaan spesifik atau memperbarui pengetahuan mereka.
Alat ini memperluas kegunaan LLM dengan menghubungkannya ke dunia nyata-sumber pengetahuan dunia, meningkatkan kemampuan mereka menghasilkan keluaran yang akurat dan membumi. Meskipun FACTS Grounding mengevaluasi fidelitas grounding internal, alat eksternal memberikan cara alternatif untuk memperluas dan memverifikasi faktualitas.
Open-Source Model Grounding Opsi
Beberapa implementasi sumber terbuka tersedia untuk metode landasan alternatif yang dibahas di atas:
Pentingnya respons AI yang akurat dan membumi menjadi sangat jelas dalam aplikasi berisiko tinggi, seperti diagnostik medis , tinjauan hukum, dan analisis keuangan. Dalam konteks ini, bahkan ketidakakuratan kecil pun dapat menimbulkan konsekuensi yang signifikan, sehingga keandalan keluaran yang dihasilkan AI merupakan persyaratan yang tidak dapat ditawar. FACTS Penekanan Grounding pada faktualitas dan kepatuhan terhadap materi sumber memastikan bahwa model diuji dalam kondisi yang mencerminkan tuntutan dunia nyata. Misalnya, dalam konteks medis, LLM bertugas untuk meringkas catatan pasien harus menghindari kesalahan yang dapat memberikan informasi yang salah dalam keputusan pengobatan. Demikian pula, dalam lingkungan hukum, pembuatan ringkasan atau analisis kasus hukum memerlukan landasan yang tepat dalam dokumen yang disediakan. FACTS Grounding tidak hanya mengevaluasi kemampuan model dalam memenuhi persyaratan ketat ini, namun juga menetapkan tolok ukur bagi pengembang untuk menciptakan sistem yang sesuai untuk aplikasi semacam itu. DeepMind telah memposisikan FACTS Grounding sebagai “tolak ukur hidup”, yang akan berkembang seiring dengan kemajuan AI. Pembaruan di masa depan kemungkinan akan memperluas kumpulan data untuk mencakup domain dan jenis tugas baru, memastikan relevansinya yang berkelanjutan seiring dengan berkembangnya kemampuan LLM. Selain itu, pengenalan template evaluasi yang lebih beragam dapat semakin meningkatkan ketahanan proses penilaian, mengatasi kasus-kasus yang sulit dan mengurangi bias yang tersisa. Seperti yang diakui oleh tim peneliti DeepMind, tidak ada tolok ukur yang dapat sepenuhnya merangkum kompleksitas aplikasi di dunia nyata. Namun, dengan menerapkan FACTS Grounding dan melibatkan komunitas AI yang lebih luas, proyek ini bertujuan untuk meningkatkan standar tersebut faktualitas dan landasan dalam sistem AI. Seperti yang dinyatakan oleh tim DeepMind, “Faktualitas dan landasan adalah salah satu faktor kunci yang akan membentuk kesuksesan dan kegunaan LLM dan sistem AI yang lebih luas di masa depan, dan kami bertujuan untuk mengembangkan dan menerapkan FACTS Grounding seiring kemajuan bidang ini. terus meningkatkan standarnya.”Implikasi terhadap Aplikasi Berisiko Tinggi
Memperluas Kumpulan Data FACTS dan Arah Masa Depan