DeepSeek AI telah merilis DeepSeek-VL2, rangkaian Model Bahasa Visi (VLM) yang kini tersedia di bawah lisensi sumber terbuka. Seri ini memperkenalkan tiga varian—Tiny, Small, dan VL2 standar—yang menampilkan ukuran parameter aktif masing-masing sebesar 1,0 miliar, 2,8 miliar, dan 4,5 miliar.
Model dapat diakses melalui GitHub dan Memeluk Wajah. Mereka berjanji untuk memajukan aplikasi AI utama, termasuk menjawab pertanyaan visual (VQA), pengenalan karakter optik (OCR), dan analisis dokumen dan grafik resolusi tinggi.
Menurut dokumentasi resmi GitHub, “DeepSeek-VL2 menunjukkan kemampuan unggul dalam berbagai tugas, termasuk namun tidak terbatas pada menjawab pertanyaan visual, pemahaman dokumen/tabel/bagan, dan landasan visual.”
Waktu peluncuran ini menempatkan DeepSeek AI dalam persaingan langsung dengan pemain besar seperti OpenAI dan Google, yang keduanya mendominasi domain AI bahasa visi dengan kepemilikan model seperti GPT-4V dan Gemini-Exp.
Penekanan DeepSeek pada sumber terbuka kolaborasi, dikombinasikan dengan fitur teknis canggih dari rangkaian VL2, menjadikannya sebagai opsi gratis bagi para peneliti.
Petakan Dinamis: Memajukan Pemrosesan Gambar Resolusi Tinggi
Salah satu kemajuan paling menonjol dalam DeepSeek-VL2 adalah strategi pengkodean visi ubin dinamis, yang merevolusi cara model memproses data visual resolusi tinggi.
Tidak seperti pendekatan resolusi tetap tradisional, pembagian ubin dinamis gambar menjadi ubin yang lebih kecil dan fleksibel yang beradaptasi dengan berbagai rasio aspek. Metode ini memastikan ekstraksi fitur secara detail dengan tetap menjaga efisiensi komputasi.
Pada repositori GitHub-nya, DeepSeek menjelaskan hal ini sebagai cara untuk “memproses gambar beresolusi tinggi secara efisien dengan berbagai rasio aspek, menghindari penskalaan komputasi yang biasanya dikaitkan dengan peningkatan resolusi gambar.”
Kemampuan ini memungkinkan DeepSeek-VL2 unggul dalam aplikasi seperti landasan visual, di mana presisi tinggi sangat penting untuk mengidentifikasi objek dalam gambar yang kompleks, dan tugas OCR yang padat, yang memerlukan pemrosesan teks dalam dokumen atau bagan terperinci secara dinamis menyesuaikan diri dengan yang berbeda resolusi gambar dan rasio aspek, model ini mengatasi keterbatasan metode pengkodean statis, sehingga cocok untuk kasus penggunaan yang menuntut fleksibilitas dan akurasi.
Campuran-of-Experts dan Multi-Head Latent Attention untuk Efisiensi
Peningkatan kinerja DeepSeek-VL2 semakin didukung oleh integrasi kerangka Mixture-of-Experts (MoE) dan Multi-head Latent Attention (MLA). Desain ini mengurangi overhead komputasi dengan hanya menggunakan parameter yang diperlukan untuk setiap operasi, sebuah fitur yang sangat berguna di lingkungan dengan sumber daya terbatas.
Mekanisme MLA melengkapi kerangka kerja MoE dengan mengompresi cache Nilai-Kunci menjadi cache laten vektor selama inferensi. Pengoptimalan ini meminimalkan penggunaan memori dan meningkatkan kecepatan pemrosesan tanpa mengorbankan akurasi model.
Menurut dokumentasi teknis, “Arsitektur MoE, dikombinasikan dengan MLA, memungkinkan DeepSeek-VL2 mencapai kinerja yang kompetitif atau lebih baik daripada model padat dengan lebih sedikit parameter yang diaktifkan.”
Jalur Pelatihan Tiga Tahap
Pengembangan DeepSeek-VL2 melibatkan alur pelatihan tiga tahap yang ketat yang dirancang untuk mengoptimalkan kemampuan multimodal model itu model dilatih untuk mengintegrasikan fitur visual dengan informasi tekstual.
Hal ini dicapai dengan menggunakan kumpulan data seperti ShareGPT4V, yang menyediakan contoh gambar-teks berpasangan untuk penyelarasan awal berbagai kumpulan data, termasuk WIT, WikiHow, dan data OCR multibahasa, untuk meningkatkan kemampuan generalisasi model di berbagai domain (SFT), yang menggunakan kumpulan data khusus tugas untuk menyempurnakan performa model di berbagai bidang seperti landasan visual, pemahaman antarmuka pengguna grafis (GUI), dan teks padat.
Tahap pelatihan ini memungkinkan DeepSeek-VL2 untuk membangun landasan yang kuat untuk pemahaman multimodal sekaligus memungkinkan model beradaptasi dengan tugas-tugas khusus. Penggabungan kumpulan data multibahasa semakin meningkatkan penerapan model dalam penelitian global dan lingkungan industri.
Terkait: Model Pratinjau R1-Lite DeepSeek Tiongkok Menargetkan Kepemimpinan OpenAI dalam Penalaran Otomatis
Hasil Pembandingan
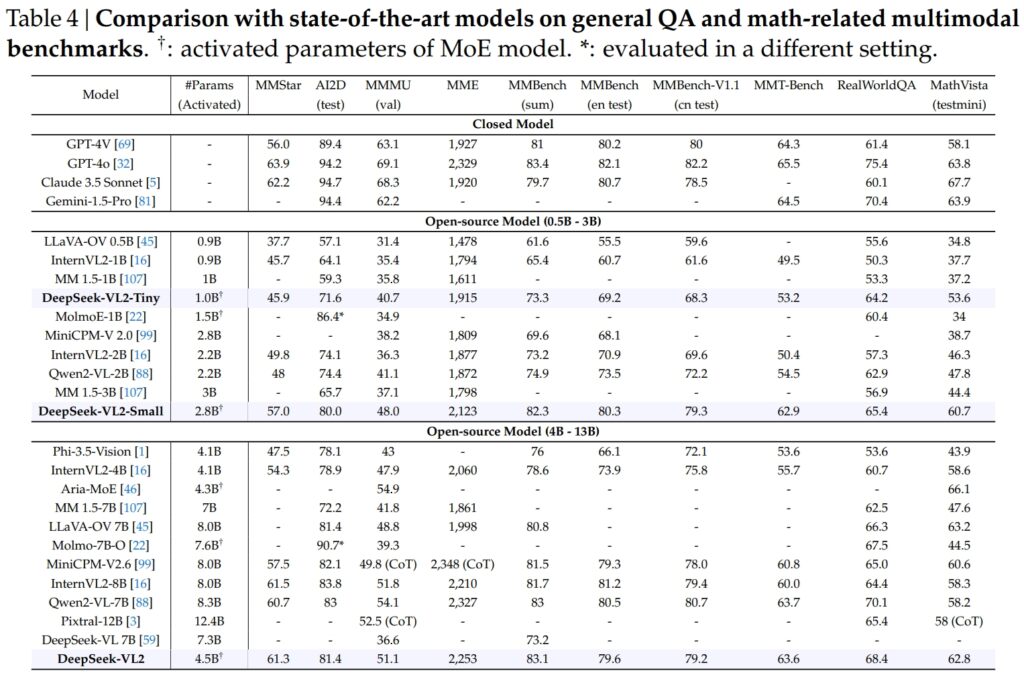
Model DeepSeek-VL2, termasuk varian Tiny, Small, dan standar, unggul dalam tolok ukur penting untuk umum tanya jawab (QA) dan tugas multimodal yang berhubungan dengan matematika.
DeepSeek-VL2-Small, dengan 2,8 miliar parameter yang diaktifkan, mencapai skor MMStar 57,0 dan mengungguli model berukuran serupa seperti InternVL2-2B (49,8) dan Qwen2-VL-2B (48,0). Model ini juga menyaingi model yang jauh lebih besar, seperti 4.1B InternVL2-4B (54.3) dan 8.3B Qwen2-VL-7B (60.7), yang menunjukkan efisiensi kompetitifnya.
Pada pengujian AI2D untuk visual alasannya, DeepSeek-VL2-Small mencapai skor 80.0, melampaui InternVL2-2B (74.1) dan MM 1,5-3B (tidak dilaporkan). Bahkan melawan pesaing berskala lebih besar seperti InternVL2-4B (78,9) dan MiniCPM-V2.6 (82,1), DeepSeek-VL2 menunjukkan hasil yang kuat dengan lebih sedikit parameter yang diaktifkan.
 Sumber: DeepSeek
Sumber: DeepSeek
Unggulannya Model DeepSeek-VL2 (4,5 miliar parameter yang diaktifkan) memberikan hasil yang luar biasa, dengan skor 61,3 pada MMStar dan 81,4 pada AI2D. Performanya mengungguli kompetitor seperti Molmo-7B-O (7,6B parameter aktif, 39,3) dan MiniCPM-V2.6 (8,0B, 57,5), yang semakin memvalidasi keunggulan teknisnya.
Keunggulan dalam OCR-Tolok Ukur Terkait
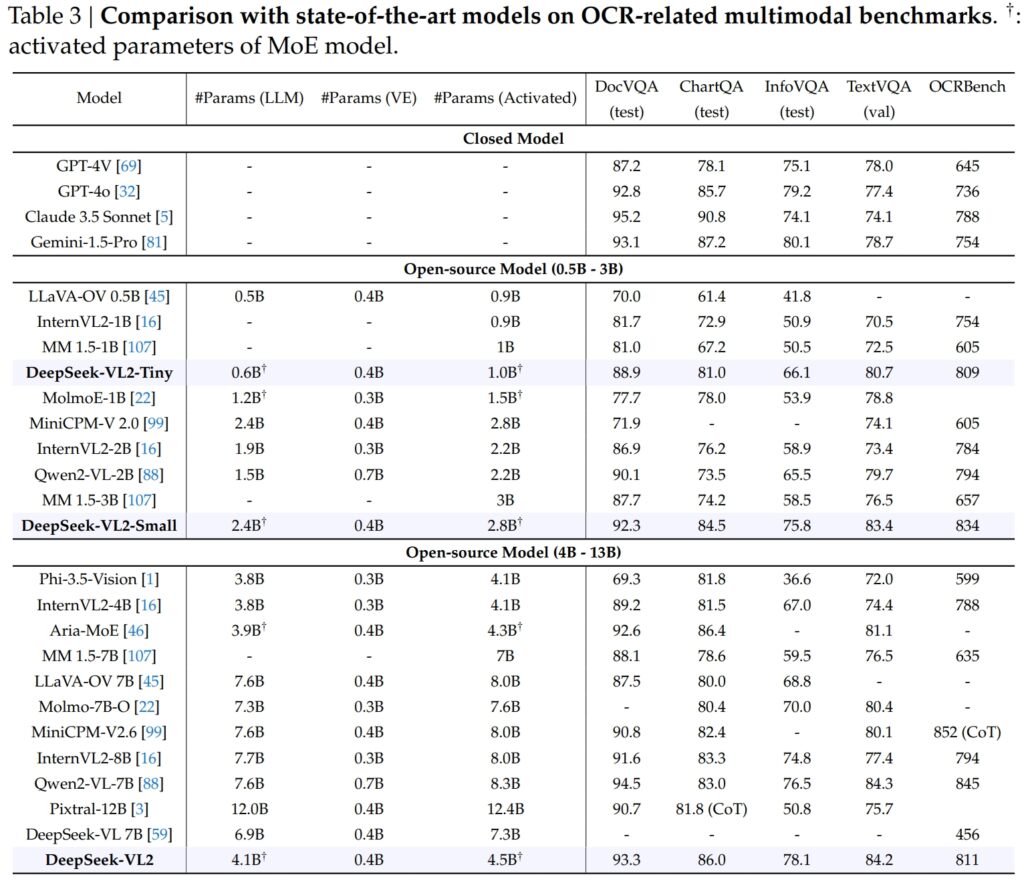
Kemampuan DeepSeek-VL2 sangat menonjol hingga tugas-tugas terkait OCR (pengenalan karakter optik), area penting untuk pemahaman dokumen dan ekstraksi teks di AI. Dalam pengujian DocVQA, DeepSeek-VL2-Small mencapai akurasi 92,3% yang mengesankan, mengungguli semua model sumber terbuka lainnya dengan skala serupa, termasuk InternVL2-4B (89,2%) dan MiniCPM-V2.6 (90,8%). Akurasinya berada tepat di belakang model tertutup seperti GPT-4o (92,8) dan Claude 3.5 Sonnet (95,2).
Model DeepSeek-VL2 juga unggul dalam pengujian ChartQA dengan skor 86,0, mengungguli InternVL2-4B (81,5) dan MiniCPM-V2.6 (82,4). Hasil ini mencerminkan kemampuan tingkat lanjut DeepSeek-VL2 untuk memproses bagan dan mengekstrak wawasan dari data visual yang kompleks.
 Sumber: DeepSeek
Sumber: DeepSeek
Di OCRBench, sangat kompetitif metrik untuk pengenalan teks halus, DeepSeek-VL2 mencapai 811, mengungguli 7.6B Qwen2-VL-7B (845) dan MiniCPM-V2.6 (852 dengan CoT), dan menyoroti kekuatannya dalam tugas-tugas OCR yang padat.
Perbandingan Dengan Model Vision-Language Terkemuka
Ketika ditempatkan bersama para pemimpin industri seperti GPT-4V OpenAI dan Gemini-1.5-Pro Google, model DeepSeek-VL2 menawarkan keseimbangan yang menarik antara kinerja dan efisiensi. Misalnya, GPT-4V mendapat skor 87,2 di DocVQA, yang hanya sedikit lebih tinggi dari DeepSeek-VL2 (93,3), meskipun DeepSeek-VL2 beroperasi di bawah kerangka kerja sumber terbuka dengan lebih sedikit parameter yang diaktifkan.
Pada TextVQA, DeepSeek-VL2-Small mencapai 83,4, secara signifikan mengungguli model sumber terbuka serupa seperti InternVL2-2B (73,4) dan BPS Mini-V2.0 (74.1). Bahkan MiniCPM-V2.6 (8,0B) yang jauh lebih besar hanya mencapai 80,4, yang semakin menekankan skalabilitas dan efisiensi arsitektur DeepSeek-VL2.
Untuk ChartQA, skor DeepSeek-VL2 sebesar 86,0 melebihi skor Pixtral-12B (81.8) dan InternVL2-8B (83.3), menunjukkan kemampuannya untuk unggul dalam tugas-tugas khusus yang memerlukan pemahaman visual-tekstual yang tepat.
Terkait: Mistral AI Memperkenalkan Pixtral 12B untuk Pemrosesan Teks dan Gambar
Memperluas Aplikasi: Dari Percakapan Dasar ke Visual Bercerita
Salah satu fitur penting model DeepSeek-VL2 adalah kemampuannya untuk melakukan percakapan membumi, di mana model dapat mengidentifikasi objek dalam gambar dan mengintegrasikannya ke dalam diskusi kontekstual.
Misalnya, dengan menggunakan token khusus, model dapat memberikan detail spesifik objek, seperti lokasi dan deskripsi, untuk menjawab pertanyaan tentang gambar. Hal ini membuka kemungkinan penerapan dalam robotika, augmented reality, dan asisten digital, yang memerlukan penalaran visual yang tepat.
Area penerapan lainnya adalah visual storytelling. DeepSeek-VL2 dapat menghasilkan narasi yang koheren berdasarkan rangkaian gambar, menggabungkan pengenalan visual tingkat lanjut dan kemampuan bahasa.
Hal ini sangat berharga terutama dalam domain seperti pendidikan, media, dan hiburan, yang mengutamakan pembuatan konten dinamis. Model-model ini memanfaatkan pemahaman multimodal yang kuat untuk menyusun cerita yang mendetail dan sesuai konteks, mengintegrasikan elemen visual seperti bangunan terkenal dan teks ke dalam narasi dengan lancar.
Kemampuan model dalam landasan visual juga sama kuatnya. Dalam pengujian yang melibatkan gambar kompleks, DeepSeek-VL2 telah menunjukkan kemampuan untuk menemukan dan mendeskripsikan objek secara akurat berdasarkan perintah deskriptif.
Misalnya, ketika diminta untuk mengidentifikasi “mobil yang diparkir di sisi kiri jalan”, model dapat menentukan dengan tepat objek dalam gambar dan menghasilkan koordinat kotak pembatas untuk mengilustrasikan responsnya. Fitur-fitur ini membuat ini sangat dapat diterapkan untuk sistem otonom dan pengawasan, yang memerlukan analisis visual mendetail.
Aksesibilitas dan Skalabilitas Sumber Terbuka
Keputusan DeepSeek AI untuk merilis DeepSeek-VL2 sebagai sumber terbuka sangat kontras dengan sifat kepemilikan pesaing seperti GPT-4V OpenAI dan Gemini-Exp Google, yang merupakan sistem tertutup yang dirancang untuk akses publik terbatas.
Menurut dokumentasi teknis, “Dengan menjadikan kami model dan kode terlatih tersedia untuk umum, kami bertujuan untuk mempercepat kemajuan dalam pemodelan bahasa visi dan mempromosikan inovasi kolaboratif di seluruh komunitas riset.”
Skalabilitas DeepSeek-VL2 semakin meningkatkan daya tariknya. Model-model ini dioptimalkan untuk penerapan di berbagai konfigurasi perangkat keras, mulai dari GPU tunggal dengan memori 10 GB hingga pengaturan multi-GPU yang mampu menangani beban kerja skala besar.
Fleksibilitas ini memastikan bahwa DeepSeek-VL2 dapat digunakan oleh organisasi dari semua ukuran, mulai dari perusahaan rintisan hingga perusahaan besar, tanpa memerlukan infrastruktur khusus.
Inovasi dalam Data dan Pelatihan
Faktor utama di balik kesuksesan DeepSeek-VL2 adalah data pelatihannya yang luas dan beragam. Fase pra-pelatihan menggabungkan kumpulan data seperti WIT, WikiHow, dan OBELICS, yang menyediakan campuran pasangan gambar-teks yang disisipkan untuk generalisasi.
Data tambahan untuk tugas tertentu, seperti OCR dan jawaban pertanyaan visual, berasal dari sumber seperti LaTeX OCR dan PubTabNet, sehingga memastikan bahwa model dapat menangani tugas umum dan khusus dengan akurasi tinggi.
Dimasukkannya kumpulan data multibahasa juga mencerminkan tujuan penerapan global DeepSeek AI. Kumpulan data berbahasa Mandarin seperti Wanjuan diintegrasikan bersama dengan kumpulan data berbahasa Inggris untuk memastikan bahwa model tersebut dapat beroperasi secara efektif di lingkungan multibahasa.
Pendekatan ini meningkatkan kegunaan DeepSeek-VL2 di wilayah yang didominasi data non-Inggris, sehingga memperluas basis pengguna potensial secara signifikan.
Fase penyesuaian yang diawasi semakin menyempurnakan model’kemampuan dengan berfokus pada tugas-tugas tertentu seperti pemahaman GUI dan analisis grafik. Dengan menggabungkan kumpulan data internal dengan sumber daya sumber terbuka berkualitas tinggi, DeepSeek-VL2 mencapai kinerja tercanggih pada beberapa tolok ukur, sehingga memvalidasi efektivitas metodologi pelatihannya.
Kurasi DeepSeek AI yang cermat data dan jalur pelatihan inovatif telah memungkinkan model VL2 unggul dalam berbagai tugas dengan tetap menjaga efisiensi dan skalabilitas. Faktor-faktor ini menjadikannya tambahan yang berharga dalam bidang AI multimoda.
Kemampuan model untuk menangani tugas pemrosesan gambar yang kompleks, seperti landasan visual dan OCR yang padat, menjadikannya ideal untuk industri seperti logistik dan keamanan. Dalam bidang logistik, mereka dapat mengotomatiskan pelacakan inventaris dengan menganalisis gambar stok gudang, mengidentifikasi item, dan mengintegrasikan temuan ke dalam sistem manajemen inventaris.
Dalam domain keamanan, DeepSeek-VL2 dapat membantu pengawasan dengan mengidentifikasi objek atau individu secara real time, berdasarkan kueri deskriptif, dan memberikan informasi kontekstual terperinci kepada operator.
DeepSeek-Kemampuan percakapan membumi VL2 juga menawarkan kemungkinan dalam robotika dan augmented reality. Misalnya, robot yang dilengkapi model ini dapat menafsirkan lingkungannya secara visual, merespons pertanyaan manusia tentang objek tertentu, dan melakukan tindakan berdasarkan pemahamannya terhadap masukan visual.
Demikian pula, perangkat augmented reality dapat memanfaatkan fitur landasan visual dan penceritaan model untuk memberikan pengalaman yang interaktif dan imersif, seperti tur berpemandu atau hamparan kontekstual dalam lingkungan waktu nyata.
Tantangan dan Prospek Masa Depan
Meskipun memiliki banyak kekuatan, DeepSeek-VL2 menghadapi beberapa tantangan. Salah satu batasan utamanya adalah ukuran jendela konteksnya, yang saat ini membatasi jumlah gambar yang dapat diproses dalam satu interaksi.
Memperluas jendela konteks ini pada iterasi mendatang akan memungkinkan interaksi multi-gambar yang lebih kaya dan meningkatkan kegunaan model dalam tugas-tugas yang memerlukan pemahaman kontekstual yang lebih luas.
Tantangan lain terletak pada penanganan di luar konteks. domain atau input visual berkualitas rendah, seperti gambar buram atau objek yang tidak ada dalam data pelatihannya. Meskipun DeepSeek-VL2 telah menunjukkan kemampuan generalisasi yang luar biasa, meningkatkan ketahanan terhadap masukan tersebut akan semakin meningkatkan penerapannya di seluruh skenario dunia nyata.
Ke depan, DeepSeek AI berencana untuk memperkuat kemampuan penalaran modelnya, sehingga memungkinkan model tersebut menangani tugas multimoda yang semakin kompleks. Dengan mengintegrasikan pipeline pelatihan yang lebih baik dan memperluas kumpulan data untuk mencakup skenario yang lebih beragam, DeepSeek-VL2 versi mendatang dapat menetapkan tolok ukur baru untuk performa AI bahasa visi.