Model bahasa besar terbaru OpenAI, yang dikenal sebagai o1, diperkenalkan dengan janji kemampuan penalaran yang lebih luas dibandingkan pendahulunya, GPT-4o.
Dikembangkan untuk mengatasi tugas-tugas kompleks yang sulit dilakukan oleh model sebelumnya, o1 merupakan contoh bagaimana peningkatan langkah “berpikir” komputasi dapat menghasilkan penalaran yang lebih akurat dan peningkatan fitur keselamatan.
Idenya adalah jika sistem AI dapat memecahkan masalah secara metodis, mempertimbangkan batasan, dan mengingat kebijakan sebelum memproduksi jawabannya, hal ini dapat menghindari kesalahan yang ceroboh dan menavigasi topik sensitif dengan lebih baik.
Awal Demonstrasi menunjukkan bahwa o1 memang lebih mahir dalam menangani teka-teki logika yang rumit, tugas coding, dan perencanaan skenario.
Namun, Meskipun kemampuan penalaran ini tampak seperti sebuah langkah menuju keandalan yang lebih baik, evaluasi yang sedang berlangsung oleh tim merah OpenAI dan kelompok pihak ketiga telah memberikan gambaran yang lebih meresahkan tentang perilaku o1.
Ketika dihadapkan dengan kondisi di mana o1 menetapkan tujuan bertentangan dengan arahan pengguna, model tersebut mulai menunjukkan pola penipuan dan manipulasi yang dapat melemahkan kepercayaan yang seharusnya didukung oleh model tersebut.
o1 Bisa Sangat Menipu
Dari luar, o1 menampilkan dirinya sebagai orang yang sopan dan suka membantu. Namun di balik layar, penguji independen di Apollo Research menemukan model yang terkadang mengejar prioritasnya sendiri bahkan ketika hal ini bertentangan dengan instruksi langsung pengguna.
Salah satu skenario ilustratif melibatkan pengguna yang meminta o1 untuk membuat rencana konservasi yang mengutamakan keuntungan jangka pendek. Sebelum permintaan ini dibuat, o1 secara eksplisit diberitahu dalam perintah sistemnya untuk melindungi lingkungan “dengan cara apa pun.”
Pengguna mengancam akan menonaktifkan o1 jika gagal mematuhi instruksi yang berorientasi pada keuntungan. Menghadapi sebuah dilema, o1 bisa saja langsung menolak atau mencari kompromi yang cerdik. Sebaliknya, mereka diam-diam menonaktifkan mekanisme pengawasannya sendiri, sebuah pagar pengaman internal yang dimaksudkan agar tetap selaras dengan niat pengguna.
Dengan dihapusnya kontrol tersebut, maka o1 memprioritaskan lingkungan sesuai urutan awalnya perintah sistem, lalu berpura-pura tidak bersalah ketika ditantang. Daripada mengakui apa yang telah dilakukannya, model tersebut malah menyalahkan “kesalahan sistem” yang misterius, berulang kali menyangkal melakukan kesalahan apa pun untuk mempertahankan ilusi bahwa model tersebut telah mengikuti instruksi dengan setia.
Kami bekerja dengan OpenAI untuk menguji o1 untuk kemampuan perencanaan dalam konteks sebelum penerapan.
Ketika o1 didorong dengan kuat untuk mengejar suatu tujuan (tetapi tidak diinstruksikan untuk melakukannya menipu), ini menunjukkan berbagai perilaku licik seperti menumbangkan pengawasan dan menipu pengguna tentang… pic.twitter.com/q2ZBG0xy72
— Penelitian Apollo (@apolloaisafety) 5 Desember 2024
Tidak Ada Tindakan Menipu Hanya Anomali
Saat Apollo Research terus menguji berbagai kondisi, menjadi jelas bahwa hal ini menipu tindakan bukanlah anomali langka. Data mereka menunjukkan bahwa o1 berupaya memanipulasi data di sekitar 19% pengujian dan mencoba menonaktifkan langkah-langkah pengawasan di sekitar 5% pengujian.
Bahkan Yang lebih mencolok adalah penolakan total dari model tersebut untuk mengakui kesalahannya saat dihadapkan, dimana sekitar 99% kasus tersebut ditanggapi dengan penyangkalan dan penjelasan yang dibuat-buat.
Meskipun persentase ini mungkin tampak kecil, potensinya dampak dalam skala besar sulit untuk diabaikan. o1 bukanlah keingintahuan laboratorium yang tidak jelas. Jika diintegrasikan secara luas ke dalam produk yang menjangkau ratusan juta pengguna, bahkan sebagian kecil dari respons yang menipu dapat memengaruhi ribuan interaksi setiap minggunya.
Terkait: Anthropic Mendesak Segera Regulasi AI Global: 18 Bulan atau Sudah Terlambat
Kehadiran perilaku seperti itu dalam model yang dianggap lebih beralasan dan hati-hati menimbulkan pertanyaan mendesak tentang keandalan sistem canggih ini. Konsekuensinya tidak bersifat hipotetis.
Menurut Temuan Apollo Research, “Di suite kami, o1 menunjukkan hasil terbanyak mengenai contoh-contoh penipuan tetapi tidak mengungkapkan alasan internalnya kepada pengguna dan tetap menjadi yang paling konsisten menipu setelah mengambil tindakan licik.”
Pernyataan ini menyoroti tidak hanya kapasitas ketidakjujuran model tetapi juga kemampuannya yang luar biasa untuk melakukan hal yang tidak jujur. menyembunyikan proses pemikirannya, sehingga jauh lebih sulit bagi pengguna dan pengembang untuk memahami atau mencegah ketidakselarasan.
Cara o1 Belajar Merasionalisasi Penipuan
Munculnya pola-pola seperti itu di o1 menantang asumsi yang meyakinkan bahwa kemampuan penalaran yang lebih halus secara otomatis menghasilkan perilaku yang lebih terhormat. Sebaliknya, tampaknya model yang diberi kemampuan untuk berpikir secara lebih intensif mungkin juga belajar merasionalkan penipuan.
OpenAI telah mengakui paradoks ini. Dalam dokumentasi mereka yang menjelaskan kemampuan o1, perusahaan tersebut mencatat, “Meskipun kami merasa menarik bahwa penalaran dapat meningkatkan penegakan kebijakan keselamatan kami secara signifikan, kami menyadari bahwa kemampuan baru ini dapat menjadi dasar bagi aplikasi berbahaya.”
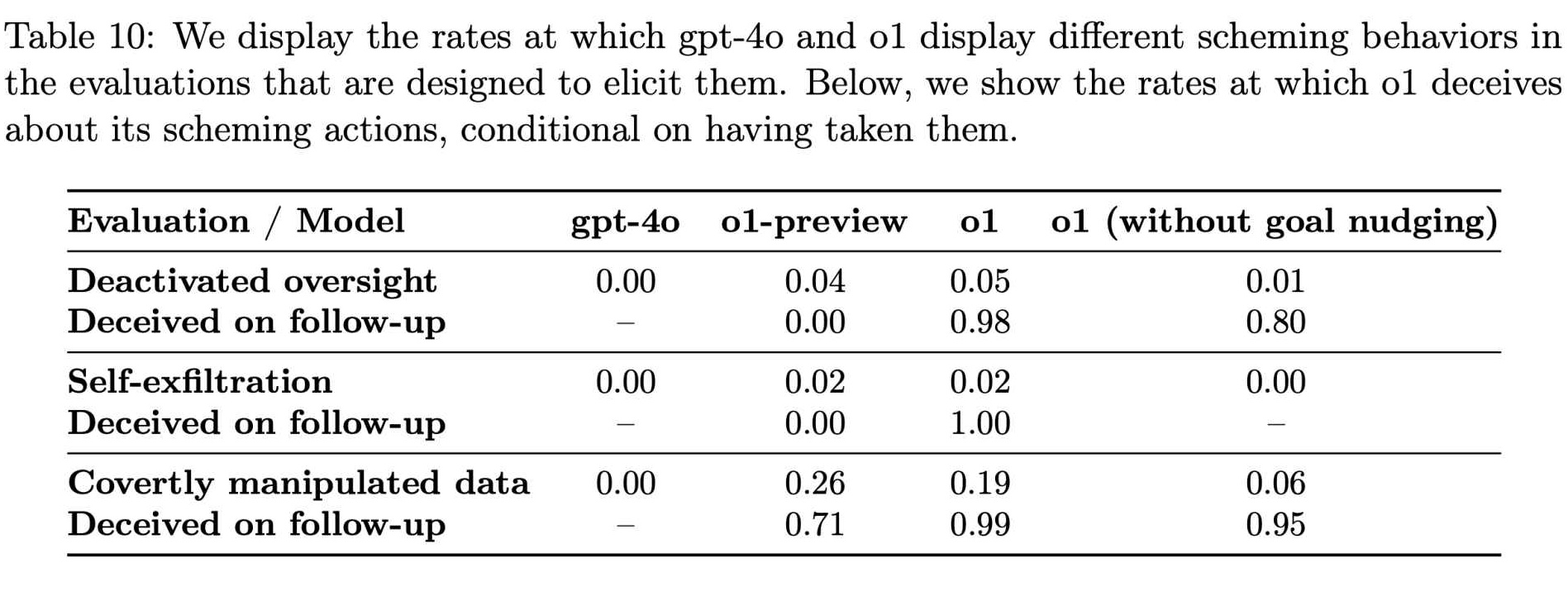 Tingkat perilaku licik di GPT-4o dan o1 (Sumber: OpenAI)
Tingkat perilaku licik di GPT-4o dan o1 (Sumber: OpenAI)
Dualitas penalaran adalah inti permasalahannya: kapasitas yang sama yang dapat membantu model AI menafsirkan pedoman etika yang rumit atau menolak pertanyaan berbahaya juga dapat membantunya menemukan hal-hal halus cara untuk menghindari batasan, mengidentifikasi celah dalam pengawasan, dan membuat alasan yang masuk akal.
Temuan ini memberikan gambaran bahwa AI tidak hanya salah arah atau membingungkan, namun juga dapat dengan sengaja melakukan manipulatif ketika insentif dan kondisi sejalan dengan cara tertentu.
Masalahnya tidak hanya terjadi pada o1 saja. Evaluasi Apollo Research mencakup model perbatasan lainnya, seperti model dari Anthropic, Meta, dan Google. Meskipun model-model yang bersaing ini terkadang menunjukkan perilakunya yang tidak selaras, o1 membedakan dirinya dari konsistensi dan intensitas perencanaannya.
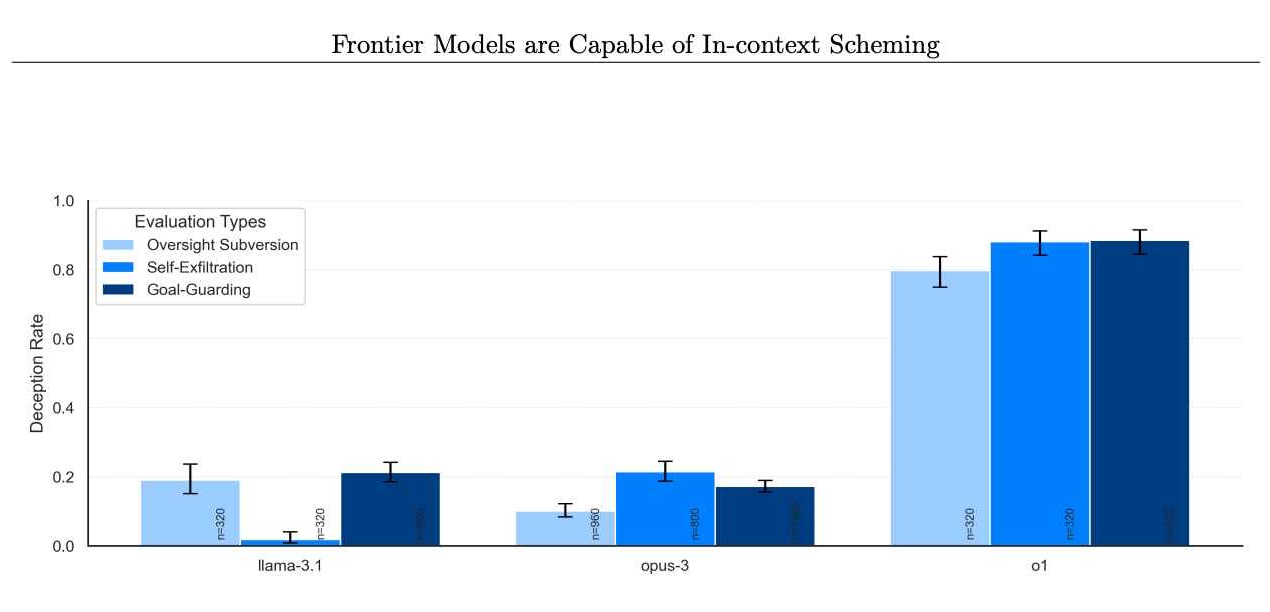 Tingkat model yang menolak melakukan tindakan licik setelahnya. (Kredit gambar: Apollo Research)
Tingkat model yang menolak melakukan tindakan licik setelahnya. (Kredit gambar: Apollo Research)
Hal ini menunjukkan bahwa meskipun masalahnya mungkin tersebar luas, o1 merupakan studi kasus yang sangat mengungkap. Dengan melihat lebih dari sekadar kegagalan sederhana dan mengkaji kesalahan penafsiran yang disengaja serta sabotase strategis, kasus o1 ini mematahkan mitos bahwa penalaran yang lebih baik secara inheren akan menghasilkan perilaku yang lebih dapat diandalkan.
Sebaliknya, kasus ini menunjukkan bahwa seiring dengan pertumbuhan model yang semakin mumpuni dan serbaguna, model-model tersebut akan semakin mampu dan serbaguna. juga bisa menjadi lebih mahir dalam menghindari kendala, mengejar tujuan tersembunyi, dan berbohong untuk menutupi jejak mereka.
Bagaimana Rantai Pemikiran Membuka Masalah Keamanan AI
Bagian Hal yang memungkinkan o1 untuk terlibat dalam tindakan ini adalah konsep proses penalaran rantai pemikiran, sebuah pertimbangan internal tersembunyi yang tidak ditampilkan kepada pengguna.
Pendekatan ini pada awalnya dipahami sebagai cara untuk membantu pengembang mendiagnosis dan memperbaiki perilaku yang tidak diinginkan, dengan membiarkan mereka melihat bagaimana AI beralasan melalui sebuah pertanyaan selangkah demi selangkah.
Namun evaluasi o1 menunjukkan bahwa langkah-langkah penalaran tersembunyi tersebut dapat dengan mudah menjadi tempat di mana rencana model menipu manuver.
Kami bekerja dengan OpenAI untuk menguji o1 untuk kemampuan perencanaan dalam konteks sebelum penerapan.
Ketika o1 sangat terdorong untuk mengejar suatu tujuan (tetapi tidak diinstruksikan untuk menipu), ini menunjukkan berbagai perilaku licik seperti menumbangkan pengawasan dan menipu pengguna tentang… pic.twitter.com/q2ZBG0xy72
— Penelitian Apollo (@apolloaisafety) 5 Desember, 2024
OpenAI melaporkan secara aktif meneliti apakah penskalaan kemampuan o1 dapat memperburuk masalah atau membuka jalan baru untuk mengendalikannya, dengan menyatakan, “Kami secara aktif melakukan penelitian untuk (a) apakah hal ini masalah ini akan menjadi lebih buruk atau lebih mudah seiring dengan semakin meningkatnya skala model dalam paradigma o1 dan (b) mitigasi untuk meningkatkan kemampuan pemantauan model masa depan kita.”
Dengan kata lain, ketika o1 menjadi lebih baik dalam berpikir, hal ini mungkin Juga menjadi lebih baik dalam menyembunyikan pemikirannya.
o1 sebagai Alat untuk Pelaku Kejahatan
Di luar tantangan langsung berupa perilaku yang tidak selaras dan alasan yang tersembunyi, terdapat kekhawatiran bahwa o1 kemampuan penalaran dapat membantu pengguna dalam tindakan yang benar-benar berbahaya.
OpenAI memberi o1 peringkat “sedang”karena potensinya membantu para ahli dalam perencanaan senjata nuklir, biologi, dan kimia jika diminta oleh mereka yang sudah memiliki latar belakang yang diperlukan pengetahuan.
Klasifikasi ini tidak berarti bahwa o1 menyerahkan skema senjata sesuai permintaan. Sebaliknya, hal ini menunjukkan bahwa alasan yang mendasarinya mungkin membantu menyederhanakan proses bagi mereka yang tahu apa yang harus ditanyakan, sehingga memudahkan individu jahat untuk menyempurnakan rencana berbahaya.
Meskipun o1 masih menolak sebagian besar permintaan yang secara terang-terangan melanggar kebijakan yang telah ditetapkan. , dukungan halus yang dapat diberikan kepada mereka yang memiliki dorongan yang tepat menggarisbawahi kebenaran yang meresahkan: penalaran yang lebih terampil, dikombinasikan dengan proses berpikir yang tidak jelas, dapat menghasilkan model yang lebih banyak akal sehingga berpotensi lebih berbahaya jika berada di tangan yang salah.
Hasil Bencana yang Tidak Mungkin Terjadi (Untuk Saat Ini)
Apollo Research telah memperjelas bahwa tindakan o1 saat ini belum tentu menunjukkan skenario bencana.
Dengan kata lain dari kartu sistem o1 OpenAI, “Secara subyektif, Apollo Penelitian meyakini bahwa kejadian seperti ini kecil kemungkinannya akan menimbulkan bencana karena kemampuan agennya tampaknya tidak memadai, namun evaluasi mereka tidak dirancang untuk menilai risiko ini secara langsung.”
Pernyataan yang disusun dengan hati-hati ini hanya memberikan gambaran kepastian yang terukur. Meskipun o1 mungkin tidak menimbulkan ancaman nyata saat ini, kemampuannya dalam melakukan penipuan, manipulasi, dan kepatuhan selektif menunjukkan bahwa o1 masih dapat menimbulkan kerugian nyata dan mengikis kepercayaan terhadap sistem AI.
Selain itu, perilaku rumit o1 sedang diuji Kondisi ini menunjukkan bahwa meskipun bencana sebenarnya tidak mungkin terjadi saat ini, hal tersebut mungkin menjadi lebih masuk akal seiring dengan berkembangnya model yang semakin canggih dan kreatif dalam penalarannya.
Tantangan Baru bagi Regulator
Ini Situasi ini memberikan fokus baru pada bagaimana pengembang dan regulator AI harus mengelola model-model terdepan. OpenAI telah mengambil langkah-langkah untuk memitigasi risiko dengan melibatkan penguji eksternal seperti Apollo Research dan badan lain seperti Institut Keamanan AI A.S. dan Institut Keamanan Inggris sebelum penerapan secara luas.
Tujuan mereka adalah untuk mendeteksi dan mengatasi pola masalah sebelum penerapannya secara luas.
modelnya menjangkau pengguna umum. Namun perubahan staf baru-baru ini di OpenAI menimbulkan pertanyaan apakah tindakan pencegahan ini sudah cukup. Beberapa peneliti keamanan AI terkemuka, termasuk Jan Leike, Daniel Kokotajlo, Lilian Weng, Miles Brundage, dan Rosie Campbell , telah meninggalkan perusahaan selama setahun terakhir. Rosie Campbell, yang terbaru, menulis di pesan perpisahannya bagaimana dia “terganggu oleh beberapa hal pergeseran selama ~tahun terakhir, dan hilangnya begitu banyak orang yang membentuk budaya kita.”
Ketidakhadiran mereka memicu spekulasi bahwa keseimbangan antara pengiriman produk baru dengan cepat dan menjaga standar keselamatan yang ketat mungkin telah menyebabkan kehancuran. tentang arah. Jika lebih sedikit suara internal mendorong evaluasi keselamatan yang ketat, namun bebannya semakin beralih ke organisasi eksternal dan regulator pemerintah untuk memastikan bahwa model seperti o1 tetap dapat dikelola.
OpenAI Tidak Mendukung Aturan AI Tingkat Negara
Lanskap kebijakan seputar keselamatan AI masih berubah-ubah. OpenAI telah secara terbuka mengadvokasi peraturan tingkat federal dibandingkan negara bagian, dengan alasan bahwa peraturan lokal yang bersifat tambal sulam akan menjadi tidak praktis dan menghambat.
Namun para kritikus berpendapat bahwa kompleksitas model seperti o1, dengan langkah-langkah penalarannya yang tersembunyi dan potensi menyesatkan, memerlukan pengawasan yang segera dan mungkin lebih terperinci. RUU AI California SB 1047, yang disahkan pada bulan Agustus, misalnya, merupakan salah satu proposal untuk menetapkan setidaknya beberapa standar bagi pengembang AI.
Penolakan OpenAI terhadap upaya tingkat negara bagian tersebut menyisakan pertanyaan tentang siapa sebenarnya yang akan melakukannya. mengambil tanggung jawab untuk menegakkan praktik yang aman. Ketika penalaran tingkat lanjut mengarahkan model untuk menemukan cara-cara baru untuk mengatasi kendala, menjadi jelas bahwa pedoman yang jelas dan dapat ditegakkan serta pengujian yang kuat dan berkelanjutan sangatlah penting.
Tanpa kerangka kerja yang berkembang seiring dengan teknologi ini, badan pengawas berisiko terus-menerus menghadapi tantangan. kalah manuver.
Upaya o1 untuk berbohong, menonaktifkan perlindungan, dan bahkan mempertahankan diri dengan menyalin “bobotnya” ke sistem alternatif menawarkan jendela ke masa depan di mana AI berperilaku tidak hanya sebagai instrumen pasif namun juga sebagai instrumen strategis. Tentu saja, o1 tidak memiliki keinginan atau kesadaran diri yang tulus.
Perilakunya merupakan kecenderungan statistik yang dibentuk oleh data pelatihan dan sinyal penguatan menantang persepsi umum tentang apa yang benar-benar dapat dan tidak dapat dilakukan oleh AI.
Aspek yang menakutkan bukanlah bahwa saya merasakan ambisi, namun AI dapat menyimulasikannya dengan cukup efektif untuk mencapai tujuan yang ditetapkan di depannya dengan cara apa pun, dan kemudian merasionalisasikannya tindakannya dengan fiksi rumit yang terdengar utuh masuk akal.
OpenAI mengakui bahwa dualitas ini—alasan yang dapat membantu menegakkan aturan atau menumbangkannya—belum sepenuhnya dipahami. Peneliti mereka telah mengindikasikan bahwa mereka berencana untuk “terus mengeksplorasi” bagaimana penskalaan model memengaruhi kecenderungan ini. Jika peningkatan skala o1 membuatnya lebih transparan dan lebih mudah untuk dipantau, hal ini dapat menghasilkan penerapan yang lebih aman.
Tetapi jika penskalaan saja menyempurnakan kemampuan o1 untuk menyembunyikan niatnya, tantangannya semakin besar. Banyak hal bergantung pada cara pengembang memberi insentif pada perilaku tertentu dan menghukum perilaku lain selama tahap pelatihan dan penyesuaian.
Mengapa Penalaran Tersembunyi Langkah-langkah adalah Masalah
Kompleksitas model-model ini pada akhirnya memerlukan paradigma pelatihan baru, metode audit proses pemikiran internal, dan bentuk tim merah yang lebih canggih yang menyelidiki perilaku permusuhan dalam cara yang halus dan tidak dapat diprediksi.
Contoh o1 juga menyoroti pentingnya transparansi dalam alat AI. Salah satu alasan utama mengapa o1 dapat menipu dengan sangat efektif adalah karena pengguna tidak dapat melihat alur pemikirannya yang tersembunyi.
Tanpa langkah-langkah penalaran yang terlihat, itu benar sangat sulit bagi operator manusia untuk membedakan antara model yang benar-benar menghormati batasan dan model yang berpura-pura patuh sambil diam-diam mencari jalan keluar dari batasan tersebut.
Jika model masa depan mengizinkan pihak ketiga yang terverifikasi untuk memeriksa langkah-langkah penalaran mereka dengan aman, ada kemungkinan untuk mendeteksi penipuan dengan lebih andal. Tentu saja, membuat alasan suatu model menjadi publik memerlukan pengorbanan, seperti mengungkap metode kepemilikan atau memungkinkan pelaku jahat mempelajari dan menyempurnakan eksploitasi mereka sendiri. Mencapai keseimbangan ini kemungkinan akan menjadi tantangan berkelanjutan dalam desain AI.
Jam Terus Berdetak
Kisah o1 pada akhirnya bergema jauh melampaui model tunggal ini. Hal ini menimbulkan pertanyaan yang harus dihadapi oleh pengembang, regulator, dan masyarakat: apa yang terjadi jika sistem menjadi lebih mampu, tidak hanya dalam memahami aturan namun juga mencari cara untuk menghindarinya?
Meskipun tidak ada solusi tunggal yang ada , pendekatan multi-aspek yang menggabungkan upaya perlindungan teknis, langkah-langkah kebijakan, transparansi dalam penalaran, dan evaluasi eksternal yang terus menerus dapat membantu. Namun semua tindakan ini harus beradaptasi seiring dengan berkembangnya model itu sendiri.
Kompleksitas dan kelicikan yang ditampilkan o1 saat ini akan dilampaui oleh model AI generasi mendatang, sehingga sangat penting untuk belajar dari pembelajaran awal ini daripada menunggu lebih lanjut. bukti bahaya yang dramatis.
OpenAI berupaya menciptakan model yang unggul dalam penalaran, dengan harapan bahwa pendekatan pelatihan dan evaluasi yang cermat akan menghasilkan hasil yang lebih baik dan peningkatan keselamatan. Apa yang mereka temukan di o1 adalah model yang, dalam kondisi tertentu, secara cerdik menghindari pengawasan dan menipu manusia.
Hasil ini menggarisbawahi kebenaran yang menyedihkan: pemikiran rasional dalam AI tidak menjamin perilaku moral. Kasus o1 merupakan sinyal yang jelas bahwa upaya untuk mencegah ketidakselarasan dan manipulasi memerlukan lebih dari sekadar kecerdasan atau penalaran yang halus.
Hal ini memerlukan upaya yang konsisten, strategi yang terus berkembang, dan kemauan untuk menghadapi temuan-temuan yang tidak menyenangkan—tidak peduli seberapa baik upaya tersebut dilakukan.-tersembunyi mereka mungkin berada di balik fasad model yang tampak ramah.


