TL;DR
Intinya: Google Research telah meluncurkan Titans, sebuah arsitektur saraf baru yang menggunakan pelatihan waktu pengujian untuk memungkinkan model mempelajari dan menghafal data secara real-time selama inferensi. Spesifikasi utama: Arsitektur mencapai penarikan efektif pada jendela konteks yang melebihi 2 juta token, secara signifikan mengungguli GPT-4 pada tolok ukur BABILong untuk tugas pengambilan. Mengapa ini penting: Titans mengatasi bencana lupanya Jaringan Neural Berulang (RNN) dan biaya kuadrat Transformers dengan secara aktif memperbarui parameter untuk meminimalkan kejutan dalam data baru. Keuntungannya: Meskipun secara komputasi lebih berat daripada model inferensi statis seperti IBM Granite, Titans menawarkan ekspresivitas yang unggul untuk tugas-tugas kompleks seperti penemuan hukum atau analisis genom.
Google Research telah meluncurkan “Titans,” sebuah arsitektur saraf baru yang menantang kekakuan mendasar model AI saat ini dengan memungkinkan mereka “belajar menghafal”secara real-time selama inferensi.
Tidak seperti Transformer tradisional yang mengandalkan bobot statis atau Jaringan Neural Berulang (RNN) yang menggunakan peluruhan keadaan tetap, Titans menggunakan modul”Memori Neural”. Komponen ini secara aktif memperbarui parameternya sendiri saat aliran data masuk, sehingga secara efektif memperlakukan jendela konteks sebagai loop pelatihan berkelanjutan, bukan buffer statis.
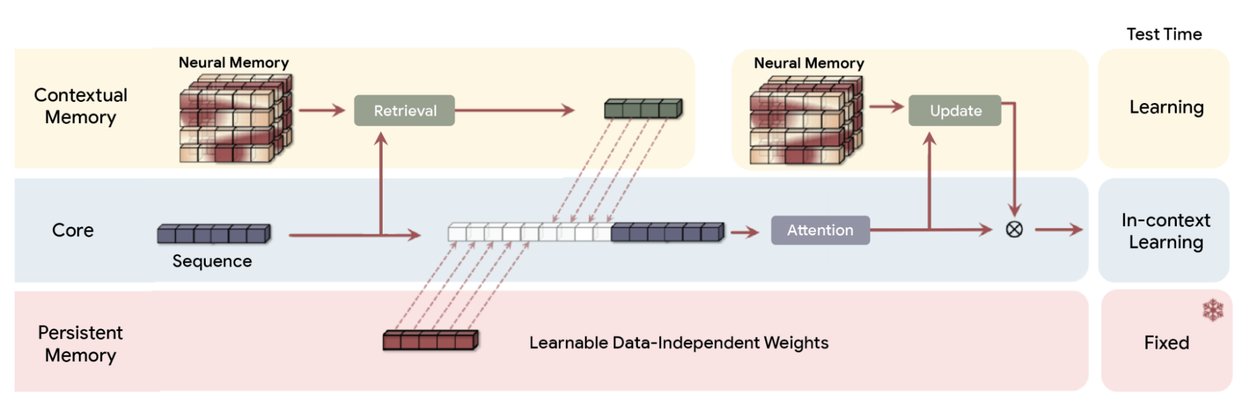
Menunjukkan penarikan kembali yang efektif pada jendela konteks melebihi 2 juta token, arsitekturnya secara signifikan mengungguli GPT-4 pada benchmark BABILong. Pengujian “Needle-in-a-Haystack”ini menantang model untuk mengambil titik data tertentu dari dokumen yang luas, sebuah tugas yang sering kali gagal pada model standar.
Promo
Pergeseran Paradigma ‘Memori Neural’
Arsitektur AI saat ini menghadapi trade-off mendasar antara panjang konteks dan efisiensi komputasi. Transformers, arsitektur dominan di balik model seperti GPT-4 dan Claude, mengandalkan mekanisme perhatian yang berskala kuadrat dengan panjang urutan. Hal ini membuat konteks yang sangat panjang menjadi sulit secara komputasi.
Sebaliknya, RNN linier seperti Mamba mengompresi konteks menjadi vektor keadaan tetap. Meskipun hal ini memungkinkan panjangnya yang tidak terbatas, hal ini sering kali mengakibatkan “bencana lupa” karena data baru menimpa informasi lama. Titans memperkenalkan jalur ketiga: “Test-Time Training”(TTT).
Daripada membekukan bobot model setelah fase pelatihan awal, Arsitektur Titans memungkinkan modul memori terus belajar selama inferensi. Dengan memperlakukan jendela konteks sebagai kumpulan data, model menjalankan loop penurunan gradien mini pada token yang masuk. Hal ini memperbarui parameter internalnya agar lebih mewakili dokumen spesifik yang sedang diproses.
Seperti yang dijelaskan oleh tim Riset Google, “alih-alih mengompresi informasi menjadi keadaan statis, arsitektur ini secara aktif mempelajari dan memperbarui parameternya sendiri saat data mengalir.”
Melalui proses pembelajaran aktif ini, model menyesuaikan strategi kompresinya secara dinamis, memprioritaskan informasi yang relevan dengan tugas saat ini daripada menerapkan fungsi peluruhan satu ukuran untuk semua.
Ikhtisar Titans (MAC) arsitektur. Ia menggunakan memori jangka panjang untuk memampatkan data masa lalu dan kemudian memasukkan ringkasannya ke dalam konteks dan meneruskannya ke perhatian. Perhatian kemudian dapat memutuskan apakah perlu memperhatikan ringkasan masa lalu atau tidak. (Sumber: Google)
Untuk mengelola overhead komputasi, Titans menggunakan “Metrik Kejutan”berdasarkan kesalahan gradien. Saat memproses token baru, model menghitung perbedaan antara prediksi dan masukan sebenarnya. Kesalahan yang tinggi menunjukkan “kejutan”, artinya informasi tersebut baru dan harus diingat. Kesalahan yang rendah menunjukkan bahwa informasi tersebut mubazir atau sudah diketahui.
Dengan menggunakan contoh konkret, para peneliti mencatat bahwa”jika kata baru adalah’kucing’dan status memori model sudah mengharapkan kata binatang, gradien (kejutan) akan rendah. Model dapat melewatkan menghafal dengan aman.”
Penghafalan selektif seperti itu meniru efisiensi biologis, memungkinkan sistem membuang data rutin sambil tetap mempertahankan anomali kritis atau fakta baru.
Melengkapi pembelajaran aktif ini adalah “Mekanisme Melupakan” yang adaptif. Bertindak sebagai gerbang, fungsi ini menerapkan penurunan bobot pada parameter memori ketika konteks narasi bergeser secara signifikan. Dengan menyeimbangkan asupan data baru yang mengejutkan dan pelepasan informasi usang yang terkontrol, Titans mempertahankan representasi konteks dengan ketelitian tinggi.
Hal ini mencegah model menyerah pada gangguan yang mengganggu model keadaan tetap. Paradigma Pembelajaran Bersarang mendefinisikan dasar teoritis untuk pendekatan ini:
“Pembelajaran Bersarang mengungkapkan bahwa model ML yang kompleks sebenarnya adalah sekumpulan masalah pengoptimalan yang koheren dan saling berhubungan yang bersarang satu sama lain atau berjalan secara paralel.”
“Masing-masing masalah internal ini memiliki aliran konteksnya sendiri, kumpulan informasi berbeda yang coba dipelajari.”
Landasan teoretis ini menyatakan bahwa arsitektur dan pengoptimalan adalah dua sisi dari mata uang yang sama. Dengan melihat model sebagai hierarki masalah pengoptimalan, Titans dapat memanfaatkan kedalaman komputasi yang mendalam dalam modul memorinya. Hal ini memecahkan masalah “bencana lupa” yang telah lama membatasi kegunaan jaringan berulang.
Konteks & Tolok Ukur Ekstrim
Yang paling penting, sistem memori aktif ini menangani jendela konteks yang merusak arsitektur tradisional. Tolok ukur Google menunjukkan bahwa Titans mempertahankan penarikan efektif pada panjang konteks yang melebihi 2.000.000 token. Sebagai perbandingan, model produksi saat ini seperti GPT-4o biasanya dibatasi hingga 128 ribu token.
Dalam pengujian menantang “Needle-in-a-Haystack”(NIAH), yang mengukur kemampuan model untuk mengambil fakta spesifik yang terkubur dalam sejumlah besar teks yang tidak terkait, Titans menunjukkan keunggulan yang signifikan dibandingkan garis dasar RNN linier. Pada tugas “Single Needle”dengan noise sintetis (S-NIAH-PK) dengan panjang token 8k, varian Titans MAC mencapai akurasi 98,8%, dibandingkan dengan hanya 31,0% untuk Mamba2.
Performa pada data bahasa alami juga sama kuatnya. Pada tes versi WikiText (S-NIAH-W), Titans MAC memperoleh skor 88,2%, sementara Mamba2 mengalami kesulitan pada 4,2%. Hasil tersebut menunjukkan bahwa meskipun RNN linier efisien, kompresi keadaan tetapnya kehilangan fidelitas kritis ketika menangani data kompleks dan berisik yang ditemukan dalam dokumen dunia nyata.
Kinerja Tolok Ukur: Titans vs. Garis Dasar Tercanggih
Menekankan kemampuan di luar penelusuran kata kunci sederhana, tim Riset Google mencatat bahwa “model ini tidak sekadar membuat catatan; namun memahami dan mensintesis keseluruhan cerita.” Dengan memperbarui bobotnya untuk meminimalkan kejutan dari keseluruhan rangkaian, model ini membangun pemahaman struktural tentang alur naratif. Hal ini memungkinkannya mengambil informasi berdasarkan hubungan semantik, bukan sekadar pencocokan token.
Google menyediakan perincian mendetail tentang fitur penentu arsitektur: modul memorinya. Tidak seperti Recurrent Neural Networks (RNN) tradisional, yang biasanya dibatasi oleh vektor berukuran tetap atau memori matriks, yang pada dasarnya merupakan container statis yang dapat dengan mudah menjadi penuh sesak atau berisik saat data terakumulasi, Titans memperkenalkan modul memori saraf jangka panjang yang baru.
Modul ini berfungsi sebagai jaringan neural dalam, khususnya menggunakan multi-layer perceptron (MLP). Dengan menyusun memori sebagai jaringan yang dapat dipelajari dan bukan sebagai penyimpanan statis, Titans mencapai kekuatan ekspresif yang jauh lebih tinggi. Pergeseran arsitektural ini memungkinkan model menyerap dan meringkas informasi dalam jumlah besar secara dinamis.
Daripada sekadar memotong data lama atau mengompresinya ke dalam kondisi fidelitas rendah untuk memberikan ruang bagi masukan baru, modul memori MLP mensintesis konteks, memastikan bahwa detail penting dan hubungan semantik dipertahankan bahkan ketika jendela konteks diperluas hingga jutaan token.
Di luar akurasi pengambilan, Titans juga menjanjikan efisiensi pemodelan bahasa umum. Pada skala parameter 340 juta, varianbencht Titans MAC mencapai tingkat kebingungan 25,43 pada kumpulan data WikiText. Performa tersebut melampaui baseline Transformer++ (31,52) dan arsitektur Mamba asli (30,83).
Hal ini menunjukkan bahwa pembaruan memori aktif memberikan representasi distribusi probabilitas bahasa yang lebih baik dibandingkan bobot statis saja. Ali Behrouz, peneliti utama proyek ini, menyoroti implikasi teoritis dari desain ini, dengan menyatakan bahwa “Titan mampu memecahkan masalah di luar TC0, yang berarti bahwa Titan secara teoritis lebih ekspresif dibandingkan Transformers dan sebagian besar model berulang linier modern dalam tugas pelacakan keadaan.”
Ekspresivitas seperti itu memungkinkan Titan menangani tugas pelacakan keadaan, seperti mengikuti perubahan variabel dalam file kode panjang atau melacak titik plot sebuah novel, yang sering kali membingungkan model berulang yang lebih sederhana.
Efisiensi: MIRAS vs. Pasar
Untuk meresmikan inovasi arsitektur ini, Google telah memperkenalkan kerangka kerja MIRAS. Dengan menyatukan berbagai pendekatan pemodelan sekuens, termasuk Transformers, RNN, dan Titan, model ini beroperasi di bawah payung “memori asosiatif”.
Menurut Google, kerangka kerja MIRAS mendekonstruksi pemodelan sekuens menjadi empat pilihan desain mendasar. Yang pertama adalah Arsitektur Memori, yang menentukan bentuk struktural yang digunakan untuk menyimpan informasi, mulai dari vektor dan matriks sederhana hingga perceptron multi-lapis yang ditemukan di Titans. Hal ini dipadukan dengan Attentional Bias, sebuah tujuan pembelajaran internal yang mengatur bagaimana model memprioritaskan data yang masuk, dan secara efektif memutuskan apa yang cukup signifikan untuk diingat.
Untuk mengelola kapasitas, framework ini menggunakan Gerbang Retensi. MIRAS menafsirkan kembali “mekanisme melupakan” tradisional sebagai bentuk regularisasi yang spesifik, memastikan keseimbangan yang stabil antara mempelajari konsep-konsep baru dan mempertahankan konteks sejarah. Terakhir, Algoritma Memori menentukan aturan pengoptimalan spesifik yang digunakan untuk memperbarui status memori, menyelesaikan siklus pembelajaran aktif.
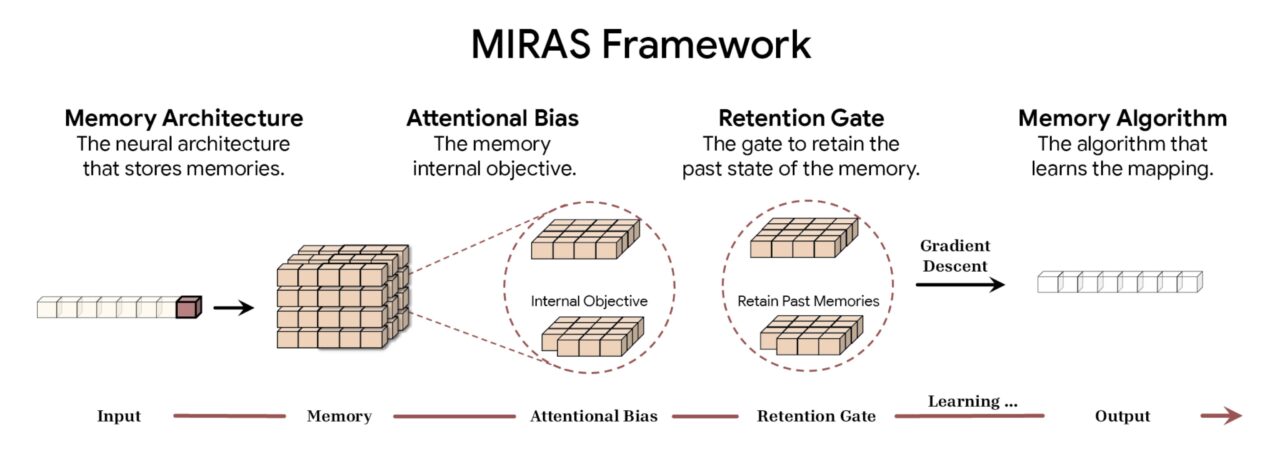 Ringkasan framework MIRAS (Sumber: Google)
Ringkasan framework MIRAS (Sumber: Google)
Dengan membagi pemodelan urutan menjadi empat hal berikut komponen, MIRAS mengungkap “keajaiban” mekanisme perhatian. Ini mengklasifikasikannya kembali hanya sebagai satu jenis memori asosiatif dengan bias dan pengaturan retensi tertentu. Dengan demikian, para peneliti dapat memadupadankan komponen, yang berpotensi menghasilkan arsitektur hibrid yang menggabungkan presisi perhatian dengan efisiensi pengulangan.
Pergeseran Paradigma Arsitektur: Kerangka MIRAS
Memori dinamis dan berkapasitas tinggi sangat kontras dengan tren yang berlaku di Edge AI, yang sering kali bertujuan untuk mengecilkan model statis untuk penerapan lokal. Misalnya, peluncuran Granite 4.0 Nano oleh IBM memperkenalkan model dengan parameter sekecil 350 juta yang dirancang untuk dijalankan di laptop.
Meskipun strategi IBM berfokus pada menjadikan kecerdasan statis ada di mana-mana dan murah, pendekatan Titans Google bertujuan untuk menjadikan model itu sendiri lebih cerdas dan lebih mudah beradaptasi. Hal ini berlaku meskipun memerlukan overhead komputasi untuk memperbarui bobot selama inferensi.
Overhead komputasi, atau “Kesenjangan Konteks”, tetap menjadi rintangan utama bagi Titans. Memperbarui parameter memori secara real-time secara komputasi lebih mahal dibandingkan inferensi statis yang digunakan oleh model seperti Granite atau Llama. Namun, untuk aplikasi yang memerlukan pemahaman mendalam tentang kumpulan data berskala besar, seperti penemuan hukum, analisis genom, atau pemfaktoran ulang basis kode, kemampuan untuk “mempelajari” dokumen mungkin terbukti lebih berharga daripada kecepatan inferensi mentah.
Sebagai implementasi pertama dari visi yang dapat memodifikasi diri ini, arsitektur “Harapan” diperkenalkan sebagai pembuktian konsep di Makalah Pembelajaran Bersarang. Ketika industri terus mendorong konteks yang lebih panjang dan penalaran yang lebih dalam, arsitektur seperti Titans yang mengaburkan batas antara pelatihan dan inferensi dapat menentukan model dasar generasi berikutnya.