Perusahaan AI Tiongkok, DeepSeek, merilis sistem sumber terbuka baru pada hari Senin yang dirancang untuk mengatasi hambatan utama AI: memproses dokumen berukuran besar.
Timnya yang berbasis di Hangzhou mengembangkan DeepSeek-OCR, sebuah alat yang menggunakan teknik “kompresi optik” baru untuk mengonversi teks dari gambar dan PDF ke dalam format yang sangat terkompresi.
Metode ini memungkinkan model bahasa menganalisis file panjang dengan komputasi yang jauh lebih sedikit. kekuatan, dilaporkan mempertahankan akurasi 97% dengan pengurangan data sepuluh kali lipat.
Meluncurkan model ini menandai poros strategis menuju efisiensi untuk DeepSeek, yang model R2 andalannya ditunda tanpa batas waktu pada awal tahun ini di tengah tantangan perangkat keras terkait perang teknologi AS-Tiongkok.
Tersedia untuk umum di platform pengembang Hugging Face, model baru dan kodenya menandakan komitmen kuat terhadap komunitas sumber terbuka.
Reaksi awal sangat positif, dengan pengamat industri berpendapat bahwa implikasi teknologi ini jauh melampaui pemrosesan dokumen standar.
Memecahkan Masalah Dokumen Panjang dengan’Kompresi Optik’
Pada intinya, DeepSeek-OCR memperkenalkan teknik yang disebut perusahaan sebagai “kompresi optik”.
Daripada memproses teks digital token demi token, sistem menganalisis gambar dokumen dan mengubah isinya menjadi serangkaian “token visi” yang sangat efisien.
Metode seperti itu secara signifikan mengurangi data yang harus ditangani oleh model bahasa, sebuah tantangan penting bagi aplikasi AI yang menangani konten berdurasi panjang seperti makalah penelitian, laporan keuangan, dan kontrak hukum.
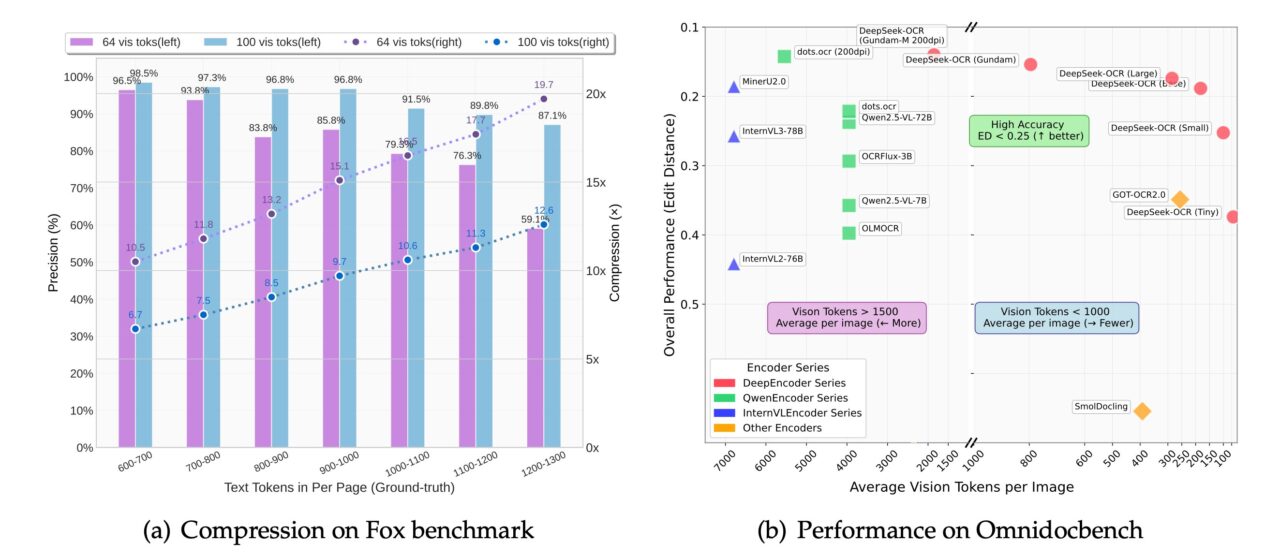
Menurut makalah teknis resmi, sistem ini sangat efektif. “Eksperimen menunjukkan bahwa ketika jumlah token teks berada dalam 10 kali lipat jumlah token vision…model dapat mencapai presisi decoding (OCR) sebesar 97%.”
Efisiensinya dicapai melalui arsitektur yang canggih. “DeepEncoder”yang canggih pertama-tama memproses gambar resolusi tinggi menggunakan komponen dari Segment Anything Model (SAM) Meta untuk analisis lokal dan CLIP OpenAI untuk konteks global.
16x kompresor kemudian secara drastis mengurangi jumlah token sebelum memasukkan data ke model bahasa DeepSeek-3B-MoE khusus untuk decoding.
Peningkatan kinerja dari pendekatan ini sangat besar. Dalam pengujian benchmark, DeepSeek-OCR mengungguli kompetitor seperti GOT-OCR2.0 yang hanya menggunakan 100 token vision dibandingkan dengan 256 token vision. DeepSeek-OCR juga mengungguli MinerU 2.0, yang membutuhkan hampir 7.000 token, dan menggunakan kurang dari 800 token.
Untuk aplikasi dunia nyata, throughputnya luar biasa: DeepSeek mengklaim satu GPU Nvidia A100 dapat memproses lebih dari 200.000 halaman per hari ini, menjadikannya alat yang ampuh untuk membangun kumpulan data besar yang diperlukan untuk melatih AI generasi berikutnya.
Poros Strategis Setelah Masalah Perangkat Keras Menghentikan Model R2
Berfokus pada efisiensi dan aksesibilitas sumber terbuka menandai perubahan strategis yang signifikan bagi DeepSeek. Peluncurannya terjadi setelah periode penuh gejolak bagi perusahaan setelah model penalaran R2 yang sangat dinanti-nantikan terhenti tanpa batas waktu pada pertengahan tahun 2025.
Meskipun laporan awal bervariasi, kemudian dikonfirmasi bahwa masalah utamanya adalah kegagalan teknis yang terus-menerus selama fase pelatihan.
DeepSeek tidak dapat menyelesaikan pelatihan yang sukses untuk model R2 menggunakan chip Ascend domestik Huawei. Kegagalan tersebut merupakan kemunduran besar bagi ambisi Tiongkok untuk mencapai kedaulatan teknologi, dan menyoroti kesulitan besar dalam membangun perangkat lunak yang kompetitif di perangkat keras domestik yang sedang berkembang.
Perusahaan terpaksa beralih kembali ke chip Nvidia yang sudah terbukti, sebuah langkah yang diperumit oleh perang teknologi AS-Tiongkok yang bergejolak.
Menambah tekanan, krisis perangkat keras telah membuat DeepSeek berada dalam posisi yang sulit. posisi kompetitifnya, menciptakan peluang bagi pesaing domestik seperti Z.ai dan Alibaba untuk mendapatkan kekuatan.
Perusahaan ini juga menghadapi pengawasan geopolitik yang ketat. Laporan pedas dari Komite DPR AS pada bulan April mencap perusahaan tersebut sebagai ancaman keamanan, dengan Ketua John Moolenaar menyatakan, “DeepSeek bukan sekadar aplikasi AI — ini adalah senjata milik Partai Komunis Tiongkok, yang dirancang untuk memata-matai orang Amerika, mencuri teknologi kami, dan melanggar hukum AS.”
Sumber Terbuka adalah Jalan ke Depan dalam Pasar Kompetitif
Dengan merilis DeepSeek-OCR sebagai alat sumber terbuka yang kuat, perusahaan ini tampaknya menjalankan strategi multi-cabang untuk mendapatkan kembali momentum.
Langkah tersebut secara langsung melibatkan komunitas pengembang global, mendorong adopsi dan inovasi seputar arsitektur barunya. Ini juga berfungsi sebagai demonstrasi praktis dari kemampuan penelitian yang sedang berlangsung, bahkan ketika model andalannya masih dalam ketidakpastian.
Peluncurannya mengikuti langkah agresif lainnya pada bulan September, ketika DeepSeek memangkas harga API-nya lebih dari 50% untuk bersaing dalam perang harga AI yang sengit di Tiongkok.
Sementara pesaing Barat seperti Mistral AI juga telah memasuki ruang OCR dengan API komersial yang kuat, fokus DeepSeek pada kompresi ekstrem dan model sumber terbuka menawarkan proposisi nilai yang berbeda.
Ini memberikan alternatif hemat biaya bagi pengembang dan peneliti yang perlu memproses dokumen dalam skala besar.
Bagi perusahaan yang menghadapi kenyataan pahit perang chip global, sumber terbuka, teknologi yang berfokus pada efisiensi, adalah langkah cerdas.
Hal ini memungkinkan DeepSeek untuk mendapatkan kembali keunggulan kompetitifnya dalam hal biaya dan inovasi, yang menandakan bahwa pengembangannya pipeline aktif dan beradaptasi dengan lanskap geopolitik yang menantang.