Tim AI Meta berada di bawah tekanan kuat setelah pelepasan model R1 Deepseek, yang telah menantang industri AI dengan efisiensi dan kinerjanya yang belum pernah terjadi sebelumnya.
Posting anonim pada platform jaringan profesional Blind mengungkapkan kekacauan dalam jajaran Meta, dengan insinyur menggambarkan upaya panik untuk memahami dan mereplikasi kesuksesan Deepseek sambil bergulat dengan inefisiensi internal dan salah langkah kepemimpinan.
Buta adalah platform jaringan profesional anonim Di mana karyawan dapat berbagi informasi, mendiskusikan masalah tempat kerja, dan jaringan dengan rekan-rekan yang sama atau industri yang berbeda. Ini memiliki sistem verifikasi untuk memastikan bahwa pengguna adalah karyawan aktual dari perusahaan yang mereka klaim bekerja, dan terutama populer di kalangan profesional di industri teknologi.
terkait: seberapa dalam R1 melampaui chatgpt o1 di bawah sanksi di bawah sanksi, redefining efisiensi eli hanya menggunakan Efisiensi AI. > Satu karyawan meta anonim, Posting dengan nama”NGI,”merangkum suasana hati di dalam divisi Meta Genai:
“Ini dimulai dengan Deepseek V3 [model Deepseek yang dirilis pada Desember 2024], yang membuat Llama 4 sudah tertinggal dalam tolok ukur. Perusahaan Cina dengan 5 juta anggaran pelatihan.’Manajemen khawatir membenarkan biaya besar Genai Org. Bagaimana mereka menghadapi kepemimpinan ketika setiap’pemimpin’Genai Org membuat lebih dari biaya untuk melatih Deepseek V3 sepenuhnya, dan kami memiliki lusinan’pemimpin.’Deepseek R1 membuat segalanya lebih menakutkan. Saya tidak dapat mengungkapkan info rahasia tetapi akan segera dipublikasikan.
Seharusnya org kecil yang berfokus pada rekayasa tetapi karena sekelompok orang ingin bergabung dengan dampak ambil dan secara artifisial mengembang perekrutan di dalamnya org, semua orang kalah.”
Komentar karyawan menyoroti ketidakpuasan internal dengan pendekatan Meta terhadap pengembangan AI, yang banyak orang gambarkan sebagai terlalu banyak birokrasi, intensif sumber daya, dan didorong oleh metrik superfisial daripada inovasi yang bermakna. p>
Rilis Deepseek R1 telah mengekspos kekurangan ini dan memaksa perhitungan untuk salah satu pemain terbesar industri AI.
terkait: llama AI Under Fire-apa meta Tidak memberi tahu Anda tentang model”open source”
Deepseek R1 mengirimkan gelombang kejut melalui sektor teknologi AS
Model R1 Deepseek, dirilis pada 10 Januari 2025 , telah membalikkan lanskap AI global dengan menunjukkan bahwa model kinerja tinggi dapat dikembangkan di sebagian kecil dari biaya yang biasanya terkait dengan proyek tersebut.
Menggunakan NVIDIA H800 GPU-chip tingkat lebih rendah yang dibatasi oleh kontrol ekspor A.S.-Insinyur DEEPSEEK melatih model di bawah $ 6 juta, menurut makalah penelitian yang dirilis pada Desember 2024.
Ini GPU, sengaja dicekik untuk mematuhi sanksi A.S., menghadirkan tantangan unik, tetapi teknik optimasi Deepseek memungkinkan tim untuk mencapai kinerja yang sebanding dengan model industri terkemuka.
Tolok ukur R1 termasuk skor 97,3% pada Math-500 dan skor 79,8% pada AIME 2024, menempatkannya di antara sistem AI yang paling mampu di dunia.
Efisiensi Deepseek R1, yang juga sebagian mengungguli model O1 Openai, tidak hanya mengguncang kepercayaan pada raksasa teknologi AS seperti meta tetapi juga memicu reaksi pasar yang signifikan.
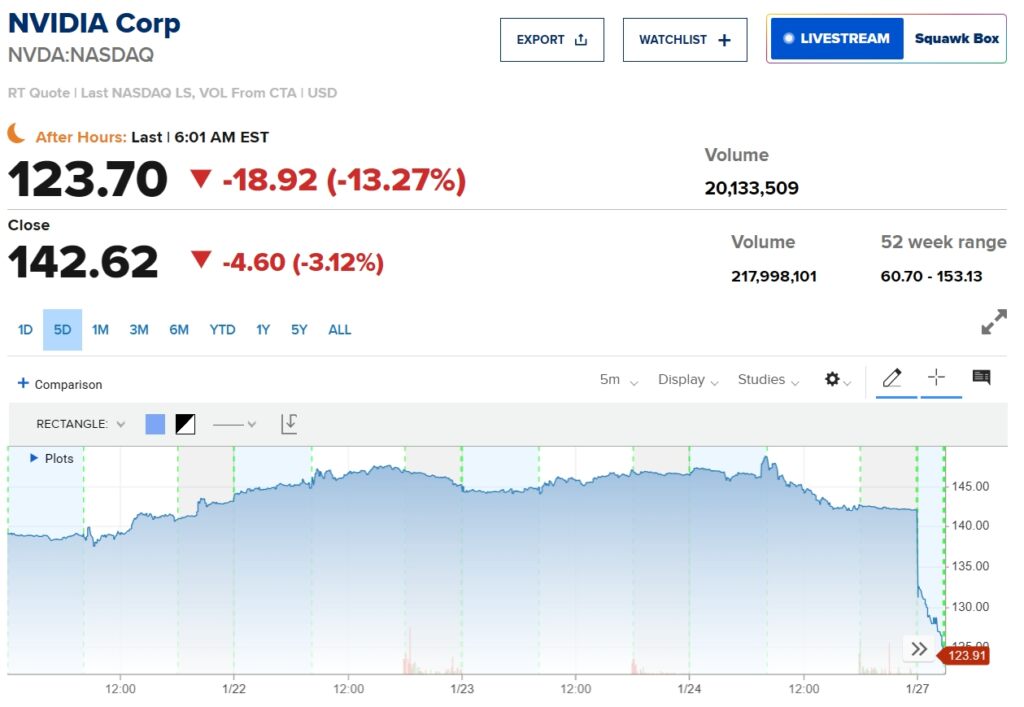
Saham NVIDIA turun lebih dari 13% dalam perdagangan premarket setelah rilis model, dan NASDAQ 100 Futures turun lebih dari 5%. Meanwhile, DeepSeek has climbed to the top spot on Apple’s U.S. App Store, surpassing OpenAI’s ChatGPT in downloads.
Meta Engineers Question Reliance on Expensive Computational AI Training
Within Meta, Insinyur telah mengkritik ketergantungan perusahaan pada kekuatan komputasi brute daripada mengejar inovasi yang digerakkan oleh efisiensi.
One employee remarked on Blind: A lot of the leadership has literally no idea (even a lot of engineering) about the underlying technology and they keep selling ‘more GPUs=win’ to the leadership.”Another shared frustration with the culture of “impact chasing,”describing it as a race for promotions rather than a commitment to meaningful advancements.
Meta’s AI efforts have also faced scrutiny for their lack of agility compared to competitors. Model R1 Deepseek tidak hanya hemat biaya tetapi juga open-source, memungkinkan pengembang di seluruh dunia untuk memeriksa dan membangun arsitekturnya.
Diskusi buta juga mengungkapkan kekhawatiran industri yang lebih luas. Karyawan Google mengakui dampak yang mengganggu Deepseek, dengan satu mencatat: “Sungguh gila apa yang dilakukan Deepseek. Ini bukan hanya meta, mereka juga menyalakan api di bawah Openai, Google dan Anthropic’s Ass. Yang merupakan hal yang baik, kami melihat waktu nyata seberapa efektif kompetisi terbuka untuk inovasi.”
Sentimen ini mencerminkan pengakuan yang berkembang bahwa strategi sumber daya tradisional mungkin tidak lagi menjamin dominasi dalam pengembangan AI.
Transparansi ini telah menarik pujian dari para pemimpin industri, termasuk Kepala Ilmuwan AI Meta sendiri, Yann Lecun, yang menulis di LinkedIn: “Deepseek telah mendapat untung dari penelitian terbuka dan open source (mis., Pytorch dan Llama dari Meta) Mereka datang dengan ide-ide baru dan membangunnya di atas pekerjaan orang lain.”
Mark Zuckerberg Double pada Investasi Infrastruktur AI
, Meta telah berfokus pada investasi infrastruktur skala besar. CEO Mark Zuckerberg baru-baru ini mengumumkan rencana untuk mengerahkan lebih dari 1,3 juta GPU pada tahun 2025 dan berinvestasi $ 60-65 miliar dalam pengembangan AI.
“Ini adalah upaya besar-besaran, dan selama beberapa tahun mendatang, ini akan mendorong produk dan bisnis inti kami, membuka kunci inovasi historis, dan memperluas kepemimpinan teknologi Amerika,”kata Zuckerberg dalam sebuah pernyataan publik awal tahun ini. Namun, rencana ini sekarang semakin bertentangan dengan pendekatan lean, efisiensi-pertama yang ditunjukkan oleh Deepseek.
Kenaikan Deepseek juga telah menyalakan kembali perdebatan tentang pembatasan ekspor A.S. pada teknologi terkait AI ke Cina Administrasi Biden telah menerapkan langkah-langkah untuk membatasi akses China ke chip canggih, termasuk GPU H100 NVIDIA. Sanksi mengambil efek penuh dan fokus pada efisiensi, Deepseek telah mengubah kendala menjadi keuntungan. memiliki celah satu kali lipat dalam struktur model dan dinamika pelatihan. Untuk alasan ini, kita perlu mengkonsumsi kekuatan komputasi empat kali lebih banyak untuk mencapai efek yang sama. Apa yang perlu kita lakukan adalah terus-menerus mempersempit kesenjangan ini”.
Ketika industri AI bergulat dengan implikasi dari kesuksesan Deepseek, meta menghadapi kebutuhan mendesak untuk beradaptasi. Karyawan perusahaan telah membuat frustrasi mereka jelas, menyerukan agar mereka jelas Pergeseran menuju strategi yang lebih efisien dan digerakkan oleh inovasi.