Startup kecerdasan buatan (AI) asal Tiongkok, DeepSeek, mengguncang fondasi pasar teknologi global, mempertanyakan penilaian yang terlalu tinggi terhadap raksasa teknologi AS.
Model R1 perusahaan, yang dirilis pada 10 Januari, telah membuktikan bahwa sistem AI yang kompetitif dapat dikembangkan dengan sedikit sumber daya yang biasanya dibutuhkan oleh para pemimpin industri.
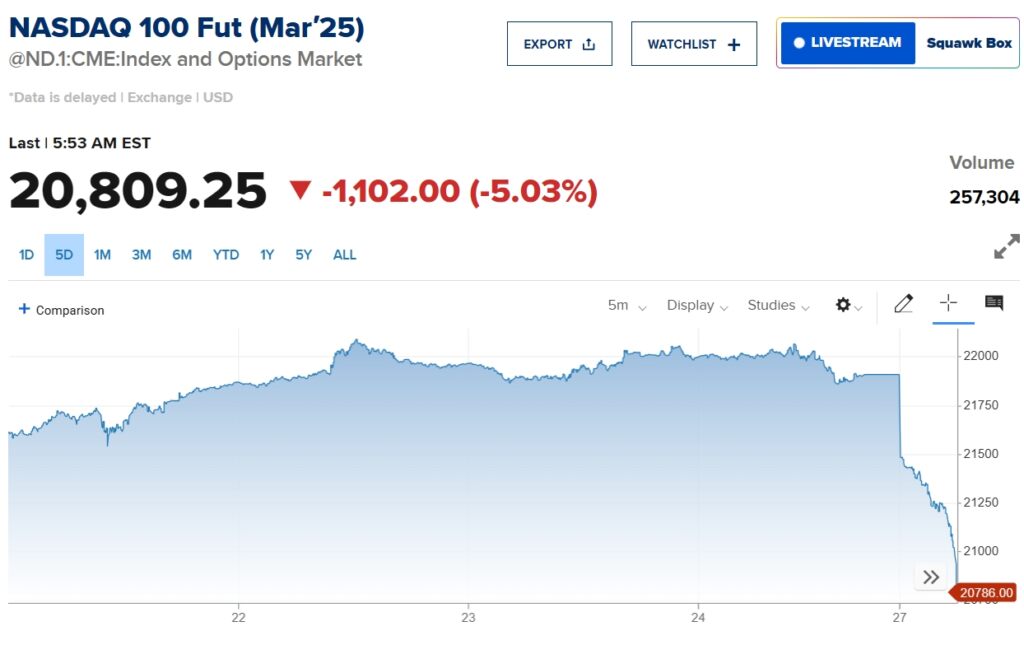
Hal ini menyebabkan Nasdaq 100 berjangka anjlok lebih dari 5% pada hari Senin. Ketika para investor bergulat dengan implikasinya, beberapa orang mengajukan pertanyaan mendesak: Apakah DeepSeek baru saja memecahkan gelembung pasar saham teknologi AS?
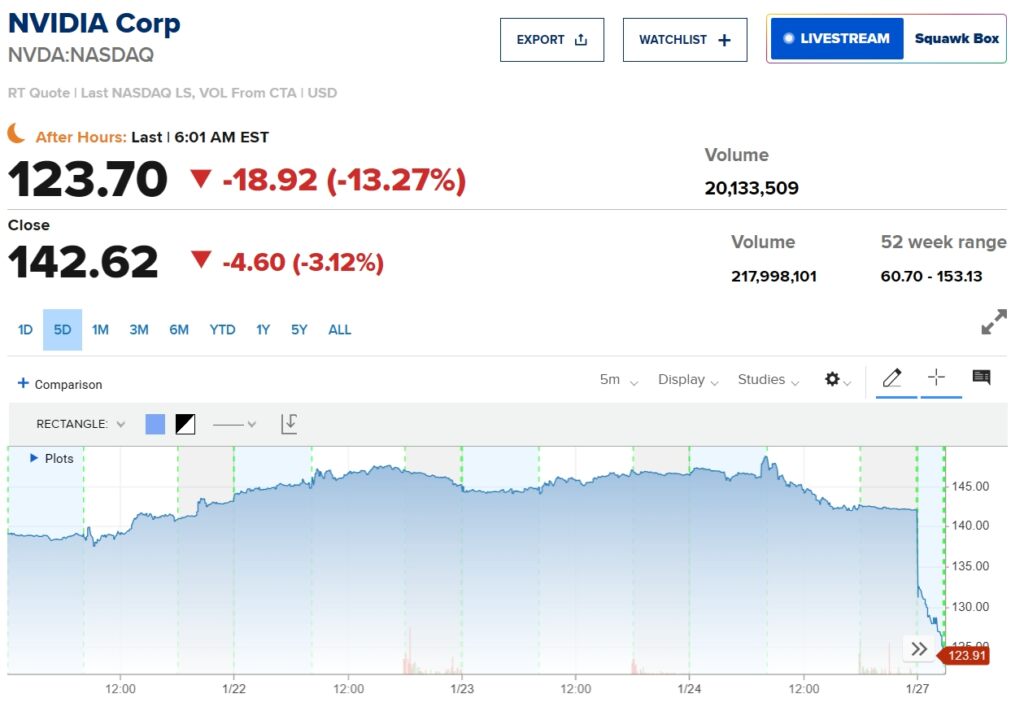
Nvidia, anak poster dari Booming AI, membuat sahamnya anjlok lebih dari 13% dalam perdagangan pra-pasar.
Inti dari pergolakan ini adalah efisiensi revolusioner DeepSeek R1. Berbeda dengan model yang dikembangkan oleh OpenAI dan Meta yang mengandalkan perangkat keras berperforma tinggi dan mahal, R1 mencapai kinerja serupa menggunakan GPU H800 Nvidia—chip kelas rendah yang dibatasi oleh sanksi AS.
Terkait: Bagaimana DeepSeek R1 Melampaui ChatGPT o1 Di Bawah Sanksi, Mendefinisikan Ulang Efisiensi AI Hanya Dengan Menggunakan 2.048 GPU
Pencapaian ini telah mematahkan asumsi lama tentang perlunya belanja infrastruktur besar-besaran dalam pengembangan AI dan menimbulkan kekhawatiran baru mengenai keberlanjutan model bisnis Silicon Valley.
DeepSeek R1: Penantang yang Hemat Biaya bagi Silicon Valley
Model R1 DeepSeek merupakan tonggak sejarah dalam inovasi AI, dengan cepat naik ke posisi teratas di Apple App Store AS hanya beberapa hari setelah dirilis. Menawarkan transparansi dalam proses penalarannya, aplikasi ini dipuji karena kemampuannya menyelesaikan pertanyaan kompleks secara efisien. Ulasan pengguna menyoroti aksesibilitas dan keandalannya, berbeda dengan pendekatan intensif sumber daya yang dilakukan oleh rekan-rekannya di AS.
Model ini dilatih menggunakan 2.048 GPU Nvidia H800 dengan total biaya di bawah $6 juta, menurut studi pada bulan Desember 2024. makalah penelitian yang dirilis oleh DeepSeek. GPU ini, yang sengaja dirancang dengan kemampuan yang lebih rendah untuk mematuhi pembatasan ekspor AS, menghadirkan tantangan unik.
Namun, para insinyur DeepSeek mengembangkan teknik pengoptimalan baru untuk meminimalkan kebutuhan komputasi dan memori, sehingga mencapai tolok ukur kinerja sebesar 97,3% pada MATH-500 dan 79,8% pada AIME 2024.
Pendiri Liang Wenfeng, seorang mantan manajer dana lindung nilai, menggambarkan strategi perusahaan: “Kami memperkirakan bahwa model dalam dan luar negeri terbaik mungkin memiliki kesenjangan satu kali lipat dalam struktur model dan dinamika pelatihan. Oleh karena itu, kita perlu mengonsumsi daya komputasi empat kali lebih banyak untuk mencapai efek yang sama. Apa yang perlu kita lakukan adalah terus mempersempit kesenjangan ini”[36Kr].
Efek Riak di Pasar Global
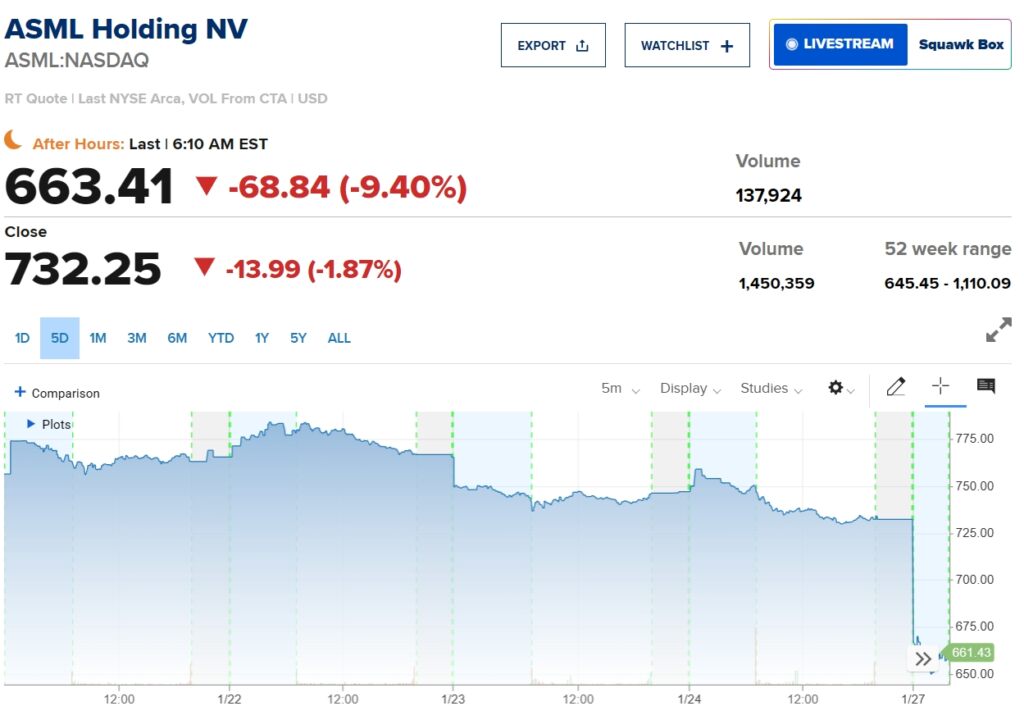
Pelepasan R1 memicu aksi jual tajam di pasar saham teknologi global. Nvidia, yang GPU-nya dianggap penting bagi pengembangan AI, mengalami penurunan valuasi hingga miliaran href=”https://www.cnbc.com/quotes/ASML?qsearchterm=ASML%20Holding”>ASML Holding NV juga mengalami penurunan 11%, sementara Nasdaq 100 futures mencatat volume perdagangan empat kali lipat rata-rata harian pada Senin pagi. Investor menilai kembali landasan finansial sektor AI, yang telah mendorong pertumbuhan signifikan pada saham-saham teknologi selama setahun terakhir.
Dampaknya meluas ke luar AS, hingga Tiongkok Saham terkait AI seperti Merit Interactive Co. melonjak sebanyak 20% sebagai respons terhadap kesuksesan DeepSeek. Indeks Hang Seng Tech naik menjelang Tahun Baru Imlek, mencerminkan optimisme terhadap semakin besarnya kehadiran Tiongkok dalam inovasi AI.
Dimensi Geopolitik: Sanksi dan Inovasi
Kebangkitan DeepSeek adalah sebuah terobosan tanggapan langsung terhadap kontrol ekspor AS yang dirancang untuk membatasi akses Tiongkok terhadap teknologi maju. Sejak tahun 2021, pembatasan ini bertujuan untuk mencegah pengembangan sistem AI yang kompetitif di Tiongkok dengan membatasi akses ke perangkat keras mutakhir.
Namun, penggunaan GPU H800 yang cerdik oleh DeepSeek telah menunjukkan bahwa inovasi dapat berkembang bahkan dalam kondisi yang ketat. kendala.
Strategi Liang dalam menimbun GPU terbatas sebelum sanksi diterapkan sepenuhnya sangatlah penting. Dengan berfokus pada efisiensi dibandingkan kekuatan komputasi, para insinyur DeepSeek menunjukkan bagaimana kendala dapat mendorong pemecahan masalah secara kreatif.
Yann LeCun, Kepala Ilmuwan AI Meta, memuji etos sumber terbuka di balik pengembangan R1, dengan menyatakan: “DeepSeek dibangun berdasarkan karya orang lain sambil menyumbangkan ide-ide baru, menunjukkan nilai penelitian terbuka”.
Implikasi bagi Raksasa Teknologi AS
Keberhasilan model R1 DeepSeek menimbulkan pertanyaan yang tidak nyaman bagi para pemimpin teknologi AS seperti Meta dan Microsoft, yang telah menginvestasikan miliaran dolar dalam infrastruktur AI. CEO Meta Mark Zuckerberg baru-baru ini menguraikan rencana ambisius perusahaan untuk menerapkan lebih dari 1,3 juta GPU pada tahun 2025, dengan menyatakan: “Kami berencana untuk menginvestasikan $60-65 miliar dalam belanja modal tahun ini sambil terus bertumbuh. tim AI kami secara signifikan”.
Era Baru untuk Inovasi AI
Komitmen DeepSeek terhadap kolaborasi sumber terbuka telah membedakannya dari raksasa industri. Dengan menerbitkan arsitektur dan metode pelatihan R1, perusahaan telah memungkinkan pengembang di seluruh dunia untuk mereplikasi atau meningkatkan pekerjaan mereka.
Transparansi ini kontras dengan sifat kepemilikan platform seperti ChatGPT OpenAI, yang menyoroti potensi pergeseran menuju inovasi AI yang lebih mudah diakses.
Seiring dengan semakin ketatnya persaingan AI, pencapaian DeepSeek adalah pengingat bahwa teknologi kepemimpinan tidak semata-mata ditentukan oleh sumber daya keuangan. Apakah ini menandai berakhirnya gelembung pasar saham teknologi AS atau babak baru dalam persaingan AI global, satu hal yang jelas: aturan mainnya sedang berubah.
