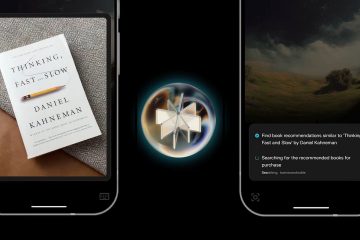
Peneliti di Mohamed bin Zayed University of Artificial Intelligence ( mbzuai ) di Abu dhabi memiliki meluncurkan LLAMAV-O1 , model AI multimodal baru yang memprioritaskan transparansi dan koherensi logis dalam penalaran.
Tidak seperti model AI penalaran lainnya, yang sering kali memberikan output kotak hitam, LLAMAV-O1 menunjukkan proses penyelesaian masalahnya langkah demi langkah, memungkinkan pengguna untuk melacak setiap tahap logikanya.
> Dipasangkan dengan pengenalan VRC-Bench, tolok ukur baru untuk mengevaluasi langkah-langkah penalaran menengah, LLAMAV-O1 menawarkan perspektif baru tentang interpretabilitas AI dan kegunaan di beragam bidang seperti diagnostik medis, keuangan, dan penelitian ilmiah.
Lebar IMG=”1024″Tinggi=”398″SRC=”Data: Image/GIF; Base64, R0lgodlhaqabaaaach5baeKaealaaaaaaaabaaaaaictaeaow==”>
Pengiriman Hasil ini dan Benchmark mencerminkan permintaan untuk AI yang berkembang bahwa AI tidak ada sistem yang memang mencerminkan permintaan AI yang berkembang dengan meningkatnya AITe, tetapi juga jelaskan bagaimana hasil tersebut tercapai.
terkait: OpenAi meluncurkan model O3 baru dengan keterampilan penalaran yang ditingkatkan secara drastis
vrc-bench: a Benchmark yang dirancang untuk penalaran transparan
Benchmark VRC-Bench adalah elemen inti dari pengembangan dan evaluasi LLAMAV-O1. Tolok ukur AI tradisional berfokus terutama pada akurasi jawaban akhir, sering mengabaikan proses logis yang mengarah pada jawaban tersebut.
VRC-Bench mengatasi batasan ini dengan mengevaluasi kualitas langkah-langkah penalaran melalui metrik seperti langkah-langkah kesetiaan dan cakupan semantik, yang mengukur seberapa baik penalaran model selaras dengan bahan sumber dan konsistensi logis.
P> Terkait: Model Flash Thinking Gemini 2.0 Google baru menantang Openai O1 Pro dengan kinerja yang sangat baik
mencakup lebih dari 1.000 tugas di delapan kategori, VRC-Bench mencakup domain seperti penalaran visual, pencitraan medis, dan analisis konteks budaya budaya. Tugas-tugas ini menampilkan lebih dari 4.000 langkah penalaran yang diverifikasi secara manual, menjadikan tolok ukur salah satu yang paling komprehensif dalam mengevaluasi penalaran langkah demi langkah.
Para peneliti menggambarkan pentingnya, menyatakan, “Sebagian besar tolok ukur fokus terutama pada akurasi tugas-akhir, mengabaikan kualitas langkah-langkah penalaran perantara. VRC-Bench menyajikan beragam tantangan… memungkinkan evaluasi yang kuat dari koherensi logis dan kebenaran dalam penalaran.”
Dengan menetapkan standar baru untuk evaluasi AI multimodal, VRC-Bench memastikan bahwa model seperti LLAMAV-O1 adalah dimintai pertanggungjawaban atas proses pengambilan keputusan mereka, menawarkan tingkat transparansi yang kritis untuk aplikasi berisiko tinggi.
Metrik kinerja: Bagaimana LLAMAV-O1 menonjol
Kinerja LLAMAV-O1 di VRC-Bench dan tolok ukur lainnya menunjukkan kecakapan teknisnya. , yang mencetak 71,8. AI2D, dan Hallusion-LlaMav-O1 mendapatkan skor rata-rata 67,33%.=”https://winbuzzer.com/wp-content/uploads/2025/01/llamav-o1-vs.-gpt-4o-gemini-2.0-flash-claude-3.5-sonnet-mmstar-mmbench-mmvet-athvista-Ai2d-hallusions-benchmarks-1024×398.jpg”>
pelatihan llitav-o1: sinergi pembelajaran kurikulum dan pencarian balok
Keberhasilan LLAMAV-O1 berakar di dalamnya metode pelatihan inovatif. Para peneliti menggunakan pembelajaran kurikulum, teknik yang terinspirasi oleh pendidikan manusia.
Pendekatan ini dimulai dengan tugas-tugas yang lebih sederhana dan secara bertahap berkembang menjadi yang lebih kompleks, memungkinkan model untuk membangun keterampilan penalaran dasar sebelum mengatasi tantangan lanjutan.
Dengan menyusun proses pelatihan, pembelajaran kurikulum meningkatkan kemampuan model untuk menggeneralisasi berbagai tugas, dari dokumen OCR hingga penalaran ilmiah.
terkait: qwq alibaba dari alibaba-32B-Preview Bergabung dengan AI Model Reasoning Battle dengan OpenAI
Pencarian balok, algoritma optimasi, meningkatkan pendekatan pelatihan ini dengan menghasilkan beberapa jalur penalaran secara paralel dan memilih yang paling logis. Metode ini tidak hanya meningkatkan akurasi model tetapi juga mengurangi biaya komputasi, membuatnya lebih efisien untuk aplikasi dunia nyata.
Seperti yang dijelaskan oleh para peneliti, “Dengan memanfaatkan pembelajaran kurikulum dan pencarian balok, model kami secara bertahap memperoleh keterampilan… memastikan kedua inferensi yang dioptimalkan dan kemampuan penalaran yang kuat.”
Aplikasi dalam Kedokteran , Keuangan, dan Beyond
Kemampuan penalaran transparan LLAMAV-O1 membuatnya sangat cocok untuk aplikasi di mana kepercayaan dan interpretabilitas sangat penting. Tetapi penjelasan terperinci tentang bagaimana hal itu sampai pada kesimpulan itu. > Di sektor keuangan, LLAMAV-O1 unggul dalam menafsirkan grafik dan diagram yang kompleks, menawarkan kerusakan langkah demi langkah yang memberikan wawasan yang dapat ditindaklanjuti.
Llamav-O1 mewakili kemajuan yang signifikan dalam AI multimodal, terutama dalam kemampuannya untuk menyediakan untuk menyediakan untuk menyediakan untuk menyediakan untuk menyediakan untuk menyediakan untuk menyediakan untuk menyediakan untuk menyediakan untuk menyediakan untuk menyediakan untuk menyediakan kemampuannya untuk menyediakan untuk menyediakan kemampuannya untuk menyediakan dalam kemampuan multimodal, khusus penalaran transparan. Dengan menggabungkan pembelajaran kurikulum dan pencarian balok dengan metrik evaluasi yang kuat dari VRC-Bench, ia menetapkan tolok ukur baru untuk interpretabilitas dan efisiensi.
Ketika sistem AI menjadi semakin terintegrasi ke dalam industri kritis, kebutuhan akan model yang dapat menjelaskan proses penalaran mereka hanya akan tumbuh.