Hugging Face telah meluncurkan dua model AI ringan, SmolVLM-256M-Instruct dan SmolVLM-500M-Instruct, yang bertujuan untuk mendefinisikan ulang bagaimana AI dapat berfungsi pada perangkat dengan daya komputasi terbatas.
Model-model tersebut, masing-masing menggunakan 256 juta dan 500 juta parameter, dirancang untuk mengatasi tantangan yang dihadapi oleh pengembang yang bekerja dengan perangkat keras terbatas atau analisis data skala besar dengan biaya minimal.
Rilisan mewakili terobosan dalam efisiensi dan aksesibilitas untuk pemrosesan AI. Model SmolVLM memberikan kemampuan multimodal tingkat lanjut, memungkinkan tugas-tugas seperti mendeskripsikan gambar, menganalisis video pendek, dan menjawab pertanyaan tentang PDF atau grafik ilmiah.
Seperti yang dijelaskan oleh Hugging Face, “SmolVLM menjadikannya lebih cepat dan lebih murah untuk membuat build yang dapat ditelusuri database, dengan kecepatan menyaingi model yang ukurannya 10x lipat.”
Mendefinisikan Ulang AI Multimodal dengan Model yang Lebih Kecil
SmolVLM-256M-Instruksikan dan SmolVLM-500M-Instruct dirancang untuk memaksimalkan kinerja sekaligus meminimalkan konsumsi sumber daya seperti proses dan interpretasi ini berbagai bentuk data—seperti teks dan gambar—secara bersamaan, menjadikannya serbaguna untuk beragam aplikasi.
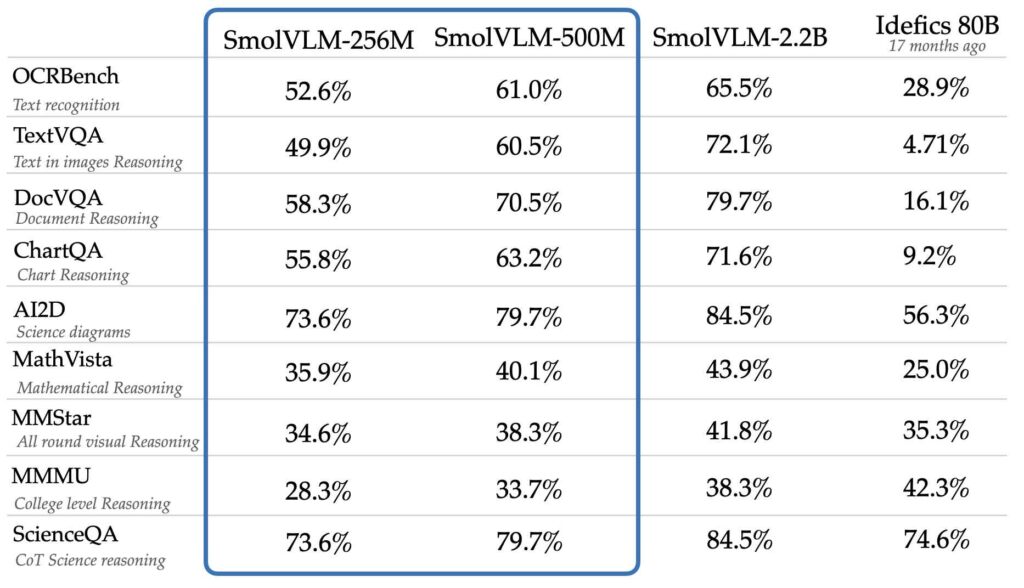
Meskipun ukurannya diperkecil, model ini mencapai tingkat kinerja yang sebanding dengan atau lebih baik daripada model yang jauh lebih besar seperti Idefics 80B, menurut tolok ukur seperti AI2D, yang mengevaluasi kemampuan untuk memahami dan bernalar dengan ilmiah diagram.
Idefis 80B adalah reproduksi akses terbuka dari Model bahasa visual Flamingo sumber tertutup DeepMind, yang dikembangkan oleh Memeluk Wajah, yang dapat memproses input gambar dan teks.
 Sumber: Hugging Face
Sumber: Hugging Face
Perkembangan model ini mengandalkan dua kumpulan data eksklusif: The Cauldron dan Docmatix. The Cauldron adalah kumpulan 50 kumpulan data gambar dan teks berkualitas tinggi yang menekankan pembelajaran multimodal, sementara Docmatix dirancang untuk pemahaman dokumen, memasangkan file yang dipindai dengan teks terperinci untuk meningkatkan pemahaman.
Tim M4 Hugging Face, yang terkenal dengan keahliannya dalam AI multimodal, mempelopori pembuatan kumpulan data ini.
Dalam pengumumannya, Hugging Face menekankan pentingnya membuat AI lebih mudah diakses. “Pengembang memberi tahu kami bahwa mereka membutuhkan model untuk laptop atau bahkan browser, dan masukan itulah yang mendorong pembuatan model ini,” kata tim tersebut. Model ini mengatasi keterbatasan praktis yang dihadapi banyak pengembang, terutama saat bekerja dengan perangkat konsumen atau operasional yang hemat anggaran.
Inovasi Teknis dalam Model SmolVLM
Faktor penting dalam kesuksesan model terletak pada desain dasarnya. Hugging Face membuat keputusan strategis untuk meningkatkan efisiensi dan akurasi penerapan vision encoder yang lebih kecil, SigLIP base patch-16/512, bukan SigLIP 400M SO digunakan pada model sebelumnya seperti SmolVLM 2B.
Encoder yang lebih kecil ini memproses gambar pada resolusi yang lebih tinggi tanpa meningkatkan overhead komputasi secara signifikan.
Inovasi lainnya melibatkan tokenisasi, sebuah proses utama dalam model AI di mana data dibagi menjadi unit-unit yang lebih kecil (token). ) untuk analisis. Dengan mengoptimalkan cara pemrosesan token gambar, Hugging Face mengurangi redundansi dan meningkatkan kemampuan model untuk menangani data yang kompleks.
Misalnya, pemisah sub-gambar, yang sebelumnya dipetakan ke beberapa token, kini direpresentasikan dengan satu token, sehingga meningkatkan stabilitas pelatihan dan kualitas inferensi. “Dengan SmolVLM, kami mendefinisikan ulang apa yang dapat dicapai oleh model AI yang lebih kecil,” tim tersebut menjelaskan dalam pengumumannya.
Pilihan desain ini memungkinkan model SmolVLM mengkodekan gambar dengan kecepatan 4.096 piksel per token, sebuah jumlah yang signifikan peningkatan dibandingkan 1.820 piksel per token yang terlihat pada versi sebelumnya. Hasilnya adalah pemahaman visual yang lebih tajam dan kecepatan pemrosesan yang lebih cepat.
Perspektif SmolVLM untuk Aplikasi
Manfaat praktis SmolVLM melampaui kasus penggunaan AI pada umumnya. Pengembang dapat mengintegrasikan model ini dengan lancar ke dalam alur kerja yang ada menggunakan alat seperti Transformers, MLX, dan ONNX yang juga telah memberikan instruksi dengan baik-pos pemeriksaan yang disetel untuk kedua model, memungkinkan penyesuaian yang mudah untuk tugas tertentu.
Model ini sangat cocok untuk analisis dan pengambilan dokumen. Bekerja sama dengan IBM, Hugging Face menerapkan SmolVLM-256M ke sistem Docling mereka, yang menunjukkan potensinya dalam mengotomatiskan alur kerja dan mengekstraksi wawasan dari file yang dipindai. Hasil awal dari kemitraan ini menunjukkan hasil yang menjanjikan, menyoroti keserbagunaan model ini.
Selain itu, model SmolVLM tersedia di Apache Lisensi 2.0, memastikan akses terbuka bagi pengembang di seluruh dunia. Komitmen terhadap pengembangan sumber terbuka ini sejalan dengan misi Hugging Face untuk mendemokratisasi AI, memungkinkan lebih banyak organisasi untuk mengadopsi teknologi canggih tanpa menghadapi biaya yang mahal.
Menyeimbangkan Biaya dan Kinerja
Pengenalan SmolVLM-256M dan SmolVLM-500M melengkapi rangkaian SmolVLM, yang kini mencakup serangkaian Model Bahasa Visi kecil yang dirancang untuk berbagai aplikasi.
Model ini sangat efektif untuk lingkungan dengan sumber daya terbatas, seperti laptop konsumen atau aplikasi berbasis browser. Varian 256M, sebagai Model Bahasa Vision terkecil yang pernah dirilis, menonjol karena kemampuannya memberikan kinerja tangguh pada perangkat dengan RAM kurang dari 1 GB.
Hugging Face membayangkan SmolVLM menjadi solusi praktis bagi pengembang yang menangani masalah besar-pemrosesan data berskala sesuai anggaran.