Para peneliti di Sakana AI, sebuah startup AI yang berbasis di Tokyo, telah memperkenalkan sistem pengoptimalan memori baru yang meningkatkan efisiensi model berbasis Transformer, termasuk model bahasa besar (LLM).
Metodenya, disebut Neural Attention Memory Models (NAMMs) tersedia melalui kode pelatihan lengkap di GitHub, mengurangi penggunaan memori hingga 75% sekaligus meningkatkan kinerja secara keseluruhan. Dengan berfokus pada token penting dan menghilangkan informasi yang berlebihan, NAMM mengatasi salah satu tantangan paling intensif sumber daya dalam AI modern: mengelola jendela konteks yang panjang.
Model transformator, tulang punggung LLM, mengandalkan “jendela konteks”untuk memproses data masukan. Jendela konteks ini menyimpan”pasangan nilai kunci”(cache KV) untuk setiap token dalam urutan masukan.
Seiring dengan bertambahnya panjang jendela—kini mencapai ratusan ribu token— biaya komputasi meroket. Solusi sebelumnya berupaya mengurangi biaya ini melalui pemangkasan token manual atau strategi heuristik, namun sering kali menurunkan kinerja. Namun, NAMM menggunakan jaringan saraf yang dilatih melalui pengoptimalan evolusioner untuk mengotomatiskan dan menyempurnakan proses manajemen memori.
Optimasi Memori dengan NAMM
NAMM menganalisis nilai perhatian dihasilkan oleh Transformers untuk menentukan kepentingan token. Mereka memproses nilai-nilai ini menjadi spektogram—representasi berbasis frekuensi yang biasa digunakan dalam pemrosesan audio dan sinyal—untuk mengompresi dan mengekstrak fitur-fitur utama dari pola perhatian.
Informasi ini kemudian diteruskan melalui jaringan saraf ringan yang memberikan skor pada setiap token, memutuskan apakah token tersebut harus dipertahankan atau dibuang.
Sakana AI menyoroti bagaimana algoritme evolusioner mendorong NAMM kesuksesan. Tidak seperti metode berbasis gradien tradisional, yang tidak kompatibel dengan keputusan biner seperti “ingat” atau “lupakan”, pengoptimalan evolusioner menguji dan menyempurnakan strategi memori secara berulang untuk memaksimalkan performa hilir.
“Evolusi secara inheren mengatasi non-diferensiabilitas operasi pengelolaan memori kami, yang melibatkan hasil biner’ingat’atau’lupakan’,”jelas para peneliti.
Hasil yang Terbukti di Seluruh Tolok Ukur
Untuk memvalidasi kinerja dan efisiensi Neural Attention Memory Models (NAMMs), Sakana AI melakukan pengujian ekstensif pada berbagai tolok ukur terkemuka di industri yang dirancang untuk menilai pemrosesan konteks panjang dan kemampuan multitugas persyaratan memori, membuktikan keefektifannya di berbagai kerangka evaluasi.
Di LongBench, tolok ukur yang khusus dibuat untuk mengukur performa model pada tugas-tugas konteks panjang, NAMM mencapai peningkatan akurasi sebesar 11% dibandingkan dengan model dasar konteks penuh. Peningkatan ini dicapai sekaligus mengurangi penggunaan memori sebesar 75%, menyoroti efisiensi metode dalam mengelola cache nilai kunci (KV).
Dengan secara cerdas memangkas token yang kurang relevan, NAMM memungkinkan model untuk fokus pada konteks penting tanpa mengorbankan hasil, sehingga ideal untuk skenario yang memerlukan masukan yang lebih banyak, seperti analisis dokumen atau menjawab pertanyaan dalam jangka panjang.
Untuk InfiniteBench, tolok ukur yang mendorong model hingga batasnya dengan waktu yang sangat lama urutan—beberapa melebihi 200.000 token—NAMM menunjukkan kemampuannya untuk melakukan penskalaan secara efektif.
Sementara model dasar kesulitan dengan tuntutan komputasi dari input yang panjang, NAMM mencapai peningkatan kinerja yang dramatis, meningkatkan akurasi dari 1,05% menjadi 11,00%.
Hasil ini sangat penting karena menunjukkan kapasitas NAMM untuk menangani konteks yang sangat panjang, kemampuan yang semakin penting untuk aplikasi seperti pemrosesan literatur ilmiah, dokumen hukum, atau repositori kode besar di mana ukuran input token sangat besar.
Pada tolok ukur ChouBun milik Sakana AI, yang mengevaluasi penalaran konteks panjang untuk tugas-tugas berbahasa Jepang, NAMM dikirimkan peningkatan 15% dari baseline. ChouBun mengatasi kesenjangan dalam tolok ukur yang ada, yang cenderung berfokus pada bahasa Inggris dan Cina, dengan menguji model pada input teks bahasa Jepang yang diperluas.
Keberhasilan NAMM di ChouBun menyoroti keserbagunaannya dalam berbagai bahasa dan membuktikan ketangguhannya dalam menangani masukan non-Inggris—fitur utama untuk aplikasi AI global. NAMM mampu secara efisien mempertahankan konten spesifik konteks sambil membuang redundansi tata bahasa dan token yang kurang bermakna, sehingga memungkinkan model bekerja lebih efektif pada tugas-tugas seperti ringkasan dan pemahaman jangka panjang dalam bahasa Jepang.
 Sumber: Sakana AI
Sumber: Sakana AI
The hasilnya secara kolektif menunjukkan bahwa NAMM unggul dalam mengoptimalkan penggunaan memori tanpa mengurangi akurasi. Baik dievaluasi pada tugas-tugas yang memerlukan urutan yang sangat panjang atau dalam konteks non-bahasa Inggris, NAMM secara konsisten mengungguli model dasar, mencapai efisiensi komputasi dan hasil yang lebih baik.
Kombinasi penghematan memori dan peningkatan akurasi ini menempatkan NAMM sebagai kemajuan besar bagi sistem AI perusahaan yang bertugas menangani masukan yang luas dan kompleks.
Hasilnya sangat penting dibandingkan dengan metode sebelumnya seperti H₂O dan L2, yang mengorbankan performa demi efisiensi. NAMM, di sisi lain, mencapai keduanya.
“Hasil kami menunjukkan bahwa NAMM berhasil memberikan peningkatan yang konsisten baik pada sumbu kinerja maupun efisiensi dibandingkan dengan Transformer dasar,” kata para peneliti.
Aplikasi Lintas-Modal: Melampaui Bahasa
Salah satu temuan yang paling mengesankan adalah kemampuan NAMM untuk mentransfer zero-shot ke tugas-tugas lain dan modalitas masukan Salah satu aspek yang paling luar biasa Salah satu keunggulan Neural Attention Memory Models (NAMMs) adalah kemampuannya untuk mentransfer berbagai tugas dan modalitas input dengan lancar—di luar aplikasi berbasis bahasa tradisional di setiap domain, NAMM mempertahankan efisiensi dan keunggulan kinerjanya tanpa penyesuaian tambahan. Eksperimen Sakana AI menunjukkan keserbagunaan ini dalam dua domain utama: visi komputer dan pembelajaran penguatan, yang keduanya menghadirkan tantangan unik untuk berbasis Transformer. model.
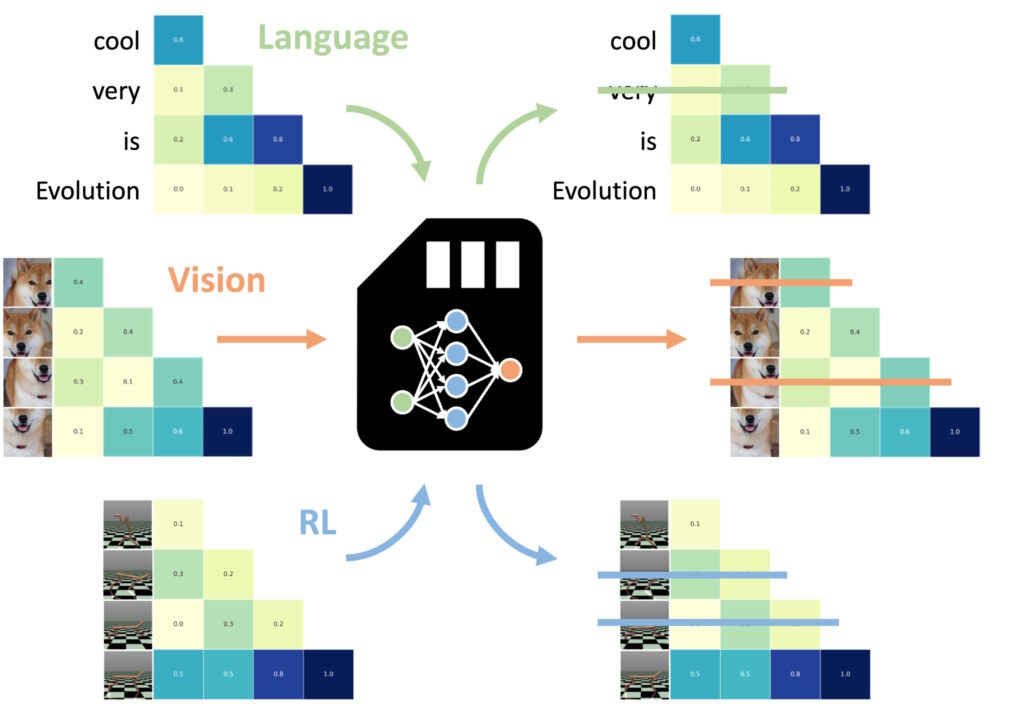 NAMM yang dilatih tentang bahasa bisa jadi nol-tembakan ditransfer ke transformator lain di seluruh modalitas masukan dan domain tugas. (Gambar: Sakana AI)
NAMM yang dilatih tentang bahasa bisa jadi nol-tembakan ditransfer ke transformator lain di seluruh modalitas masukan dan domain tugas. (Gambar: Sakana AI)
Dalam computer vision, NAMM dievaluasi menggunakan model Llava Next Video, sebuah Transformer dirancang untuk memproses rangkaian video panjang. Video pada dasarnya berisi sejumlah besar data yang berlebihan, seperti frame berulang atau variasi kecil yang memberikan sedikit informasi tambahan.
NAMM secara otomatis mengidentifikasi dan membuang frame-frame yang berlebihan ini selama inferensi, sehingga secara efektif mengompresi jendela konteks tanpa mengorbankan kemampuan model untuk menafsirkan konten video.
Misalnya, NAMM mempertahankan bingkai dengan detail visual utama—seperti perubahan tindakan, interaksi objek, atau peristiwa penting—sambil menghapus bingkai berulang atau statis. Hal ini menghasilkan peningkatan efisiensi pemrosesan, memungkinkan model untuk fokus pada elemen visual yang paling relevan, sehingga menjaga akurasi sekaligus mengurangi biaya komputasi.
Dalam pembelajaran penguatan, NAMM diterapkan pada Decision Transformer, model yang dirancang untuk memproses rangkaian tindakan, observasi, dan penghargaan untuk mengoptimalkan pengambilan keputusan tugas. Tugas pembelajaran penguatan sering kali melibatkan rangkaian masukan yang panjang dengan berbagai tingkat relevansi, di mana tindakan yang kurang optimal atau berlebihan dapat menghambat kinerja.
NAMM mengatasi tantangan ini dengan secara selektif menghapus token yang berhubungan dengan tindakan yang tidak efisien dan informasi bernilai rendah sambil tetap mempertahankan hal-hal penting untuk mencapai hasil yang lebih baik.
Misalnya, dalam tugas seperti Hopper dan Walker2d—yang melibatkan pengendalian agen virtual dalam gerakan berkelanjutan—NAMM meningkatkan kinerja lebih dari 9%. Dengan memfilter pergerakan suboptimal atau detail yang tidak perlu, Decision Transformer mencapai pembelajaran yang lebih efisien dan efektif, memfokuskan kekuatan komputasinya pada keputusan yang memaksimalkan keberhasilan dalam tugas.
Hasil ini menyoroti kemampuan adaptasi NAMM di berbagai domain yang sangat berbeda. Baik memproses bingkai video dalam model visi atau mengoptimalkan rangkaian tindakan dalam pembelajaran penguatan, NAMM menunjukkan kemampuannya untuk meningkatkan kinerja, mengurangi penggunaan sumber daya, dan menjaga keakuratan model—semuanya tanpa pelatihan ulang.
NAMM belajar untuk melupakan hampir seluruh bagian dari frame video yang berlebihan, bukan token bahasa yang menjelaskan perintah terakhir, demikian catatan makalah tersebut, yang menyoroti kemampuan adaptasi NAMM.
Dasar-Dasar Teknis NAMM
Efisiensi dan efektivitas Neural Attention Memory Models (NAMMs) terletak pada proses eksekusi yang efisien dan sistematis, yang memungkinkan pemangkasan token secara tepat tanpa intervensi manual. Proses ini dibangun berdasarkan tiga komponen inti: spektogram perhatian, kompresi fitur, dan penilaian otomatis.
NAMM secara dinamis menyesuaikan perilakunya bergantung pada persyaratan tugas dan kedalaman lapisan Transformer. Lapisan awal memprioritaskan konteks “global” seperti deskripsi tugas, sementara lapisan yang lebih dalam mempertahankan detail spesifik tugas “lokal”. Dalam tugas pengkodean, misalnya, NAMM membuang komentar dan kode boilerplate; dalam tugas-tugas bahasa alami, mereka menghilangkan redundansi tata bahasa sambil tetap mempertahankan konten utama.
Retensi token adaptif ini memastikan bahwa model tetap fokus pada informasi yang relevan selama pemrosesan, sehingga meningkatkan kecepatan dan akurasi.
Yang pertama langkah ini melibatkan pembuatan Spektogram Perhatian. Transformer menghitung “nilai perhatian”di setiap lapisan untuk menentukan kepentingan relatif setiap token dalam jendela konteks. NAMM mengubah nilai perhatian ini menjadi representasi berbasis frekuensi menggunakan Short-Time Fourier Transform (STFT)
STFT adalah teknik pemrosesan sinyal yang banyak digunakan yang memecah rangkaian menjadi komponen frekuensi lokal dari waktu ke waktu, memberikan representasi penting token yang ringkas namun terperinci. Dengan menerapkan STFT, NAMM mengubah rangkaian perhatian mentah menjadi data seperti spektogram, sehingga memungkinkan a analisis yang lebih jelas tentang token mana yang memberikan kontribusi signifikan terhadap keluaran model.
Selanjutnya, Kompresi Fitur diterapkan untuk mengurangi dimensi data spektogram sambil mempertahankan karakteristik esensialnya sebuah rata-rata pergerakan eksponensial (EMA), metode matematika yang memampatkan pola perhatian historis menjadi ringkasan yang ringkas dan berukuran tetap. EMA memastikan bahwa representasi tetap ringan dan mudah dikelola, memungkinkan NAMM menganalisis rangkaian perhatian panjang secara efisien sekaligus meminimalkan overhead komputasi.
Langkah terakhir adalah Penskoran dan Pemangkasan, di mana NAMM menggunakan metode yang ringan pengklasifikasi jaringan saraf untuk mengevaluasi representasi token terkompresi dan menetapkan skor berdasarkan kepentingannya. Token dengan skor di bawah ambang batas yang ditentukan akan dipangkas dari jendela konteks, sehingga secara efektif “melupakan” detail yang tidak membantu atau berlebihan. Mekanisme penilaian ini memungkinkan NAMM untuk memprioritaskan token penting yang berkontribusi pada proses pengambilan keputusan model sambil membuang data yang kurang relevan.
Apa yang membuat NAMM sangat efektif adalah ketergantungan mereka pada optimasi evolusioner untuk menyempurnakan proses ini. Metode optimasi tradisional seperti penurunan gradien kesulitan dengan tugas-tugas yang tidak dapat dibedakan—seperti memutuskan apakah suatu token harus dipertahankan atau dibuang.
Sebaliknya, NAMM menggunakan algoritma evolusioner berulang, yang terinspirasi oleh seleksi alam, untuk “memutasi” dan “memilih” strategi manajemen memori yang paling efisien dari waktu ke waktu berevolusi untuk memprioritaskan token penting secara otomatis, mencapai keseimbangan antara kinerja dan efisiensi memori tanpa memerlukan penyesuaian manual.
Eksekusi yang disederhanakan ini—menggabungkan analisis token berbasis spektogram, kompresi efisien, dan pemangkasan otomatis—memungkinkan NAMM untuk memberikan penghematan memori dan peningkatan kinerja yang signifikan pada beragam tugas berbasis Transformer. Dengan mengurangi kebutuhan komputasi sekaligus mempertahankan atau meningkatkan akurasi, NAMM menetapkan tolok ukur baru untuk manajemen memori yang efisien dalam model AI modern.
Apa yang Akan Terjadi Selanjutnya untuk Transformers?
Sakana AI percaya bahwa NAMM hanyalah permulaan. Meskipun pekerjaan saat ini berfokus pada optimalisasi model inferensi yang telah dilatih sebelumnya, penelitian di masa depan dapat mengintegrasikan NAMM ke dalam proses pelatihan itu sendiri. Hal ini dapat memungkinkan model mempelajari strategi pengelolaan memori secara asli, sehingga semakin memperluas jangka waktu jendela konteks dan meningkatkan efisiensi di seluruh domain.
“Pekerjaan ini baru mulai mengeksplorasi ruang desain model memori kami, yang kami antisipasi mungkin menawarkan banyak peluang baru untuk memajukan generasi trafo masa depan,”tim menyimpulkan.
Kemampuan NAMM yang telah terbukti dalam meningkatkan kinerja, mengurangi biaya, dan beradaptasi antar modalitas menetapkan standar baru untuk efisiensi skala besar. Model AI.

