Mark Russinovich, Chief Technology Officer Microsoft Azure, menyoroti meningkatnya masalah keamanan yang terkait dengan AI generatif. Berbicara di konferensi Microsoft Build 2024 di Seattle, Russinovich menggarisbawahi keberagaman serangkaian ancaman yang harus dihadapi oleh Chief Information Security Officers (CISO) dan pengembang saat mereka mengintegrasikan teknologi AI generatif. Dia menekankan perlunya pendekatan multidisiplin terhadap keamanan AI, yang mencakup pemeriksaan ancaman dari berbagai sudut seperti aplikasi AI, kode model yang mendasarinya, permintaan API, data pelatihan, dan potensi pintu belakang.
Keracunan Data dan Kesalahan Klasifikasi Model
Salah satu kekhawatiran utama yang ditangani Russinovich adalah keracunan data. Dalam serangan ini, musuh memanipulasi kumpulan data yang digunakan untuk melatih AI atau model pembelajaran mesin, sehingga menghasilkan keluaran yang rusak. Dia mengilustrasikan hal ini dengan contoh di mana gangguan digital yang ditambahkan ke gambar menyebabkan AI salah mengklasifikasikan panda sebagai monyet. Jenis serangan ini bisa sangat berbahaya karena perubahan kecil sekalipun, seperti penyisipan pintu belakang, dapat berdampak signifikan terhadap performa model.
Russinovich juga membahas masalah pintu belakang dalam model AI. Meskipun sering dianggap sebagai kerentanan, pintu belakang juga dapat berfungsi untuk memverifikasi keaslian dan integritas model. Dia menjelaskan bahwa pintu belakang dapat digunakan untuk mengambil sidik jari suatu model, sehingga perangkat lunak dapat memeriksa keasliannya. Hal ini melibatkan penambahan pertanyaan unik ke kode yang kemungkinan tidak akan ditanyakan oleh pengguna sebenarnya, sehingga memastikan integritas model.
Teknik Injeksi Cepat
Ancaman signifikan lainnya yang disoroti Russinovich adalah teknik injeksi cepat. Hal ini melibatkan penyisipan teks tersembunyi ke dalam dialog, yang dapat menyebabkan kebocoran data atau memengaruhi perilaku AI di luar operasi yang dimaksudkan. Kita telah melihat bagaimana GPT-4 V OpenAI rentan terhadap jenis serangan ini. Dia mendemonstrasikan bagaimana sepotong teks tersembunyi yang dimasukkan ke dalam dialog dapat mengakibatkan bocornya data pribadi, mirip dengan eksploitasi skrip lintas situs dalam keamanan web. Hal ini memerlukan isolasi pengguna, sesi, dan konten satu sama lain untuk mencegah serangan semacam itu.
Yang menjadi perhatian utama Microsoft adalah masalah terkait pengungkapan data sensitif, teknik jailbreaking untuk menyalip model AI, dan pemaksaan pihak ketiga.-aplikasi pihak dan plugin model untuk melewati filter keamanan atau menghasilkan konten yang dibatasi. Russinovich menyebutkan metode serangan spesifik, Crescendo, yang dapat melewati langkah-langkah keamanan konten untuk mendorong model agar menghasilkan konten berbahaya.
Pendekatan Holistik terhadap Keamanan AI
Russinovich menyamakan model AI dengan “karyawan yang sangat cerdas namun junior atau naif” yang, meskipun memiliki kecerdasan, rentan terhadap manipulasi dan dapat bertindak melawan kebijakan organisasi tanpa pengawasan ketat. Ia menekankan risiko keamanan yang melekat dalam model bahasa besar (LLM) dan model bahasa besar. kebutuhan akan pagar pembatas yang ketat untuk memitigasi kerentanan ini.
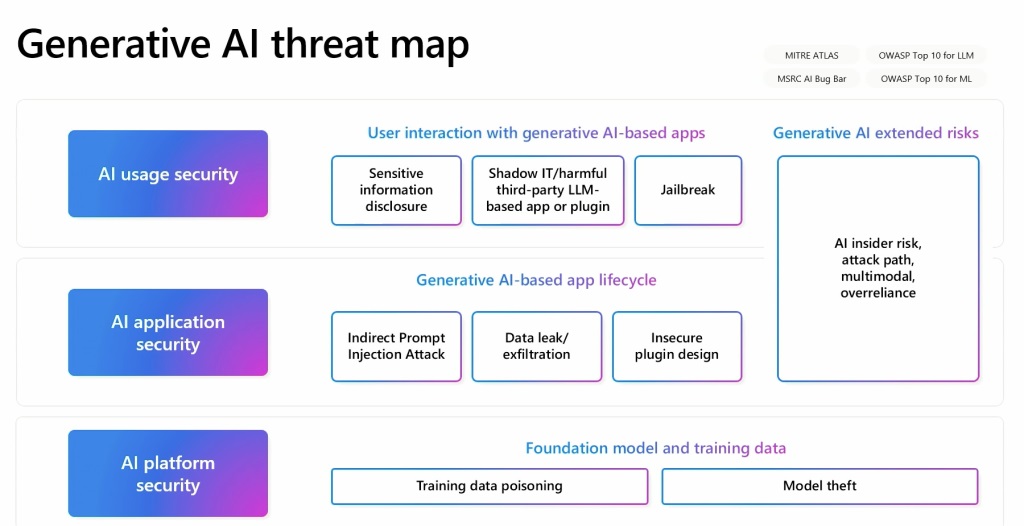
Russinovich telah mengembangkan peta ancaman AI generatif yang menguraikan hubungan antara berbagai elemen ini. Peta ini berfungsi sebagai alat penting untuk memahami dan mengatasi sifat keamanan AI yang beragam Dia memberikan contoh bagaimana menanam data beracun di halaman Wikipedia, yang dikenal sebagai sumber data, dapat menyebabkan masalah jangka panjang bahkan jika data tersebut kemudian diperbaiki. Hal ini membuat pelacakan data beracun menjadi sulit karena tidak ada lagi ada di sumber aslinya.