Dalam upaya meningkatkan performa Model Bahasa Besar (LLM), NVIDIA telah memperkenalkan TensorRT-LLM, perpustakaan sumber terbuka yang dirancang untuk meningkatkan kinerja Model Bahasa Besar (LLM) pada perangkat keras NVIDIA.
AI generatif telah mengalami lonjakan signifikan sejak OpenAI memperkenalkan ChatGPT. Perusahaan kini memanfaatkan sistem AI percakapan, yang biasa disebut chatbot AI seperti ChatGPT, untuk memenuhi kebutuhan pelanggan. NVIDIA, pemain terkemuka di pasar GPU, berada di garis depan transformasi ini, menyediakan hardware yang diperlukan untuk melatih model bahasa ekstensif seperti ChatGPT, GPT-4, BERT, dan PaLM Google.
TensorRT-LLM: Era Baru untuk Inferensi AI
TensorRT-LLM adalah perpustakaan sumber terbuka yang beroperasi pada GPU NVIDIA Tensor Core. Fungsi utamanya adalah menawarkan lingkungan kepada pengembang untuk bereksperimen dan membangun model bahasa besar baru, yang menjadi landasan platform AI generatif seperti ChatGPT. Perangkat lunak ini berfokus pada inferensi, yang menyempurnakan proses pelatihan AI, membantu sistem memahami cara menghubungkan konsep dan membuat prediksi. NVIDIA menekankan bahwa TensorRT-LLM dapat mempercepat kecepatan inferensi pada GPU mereka secara signifikan.
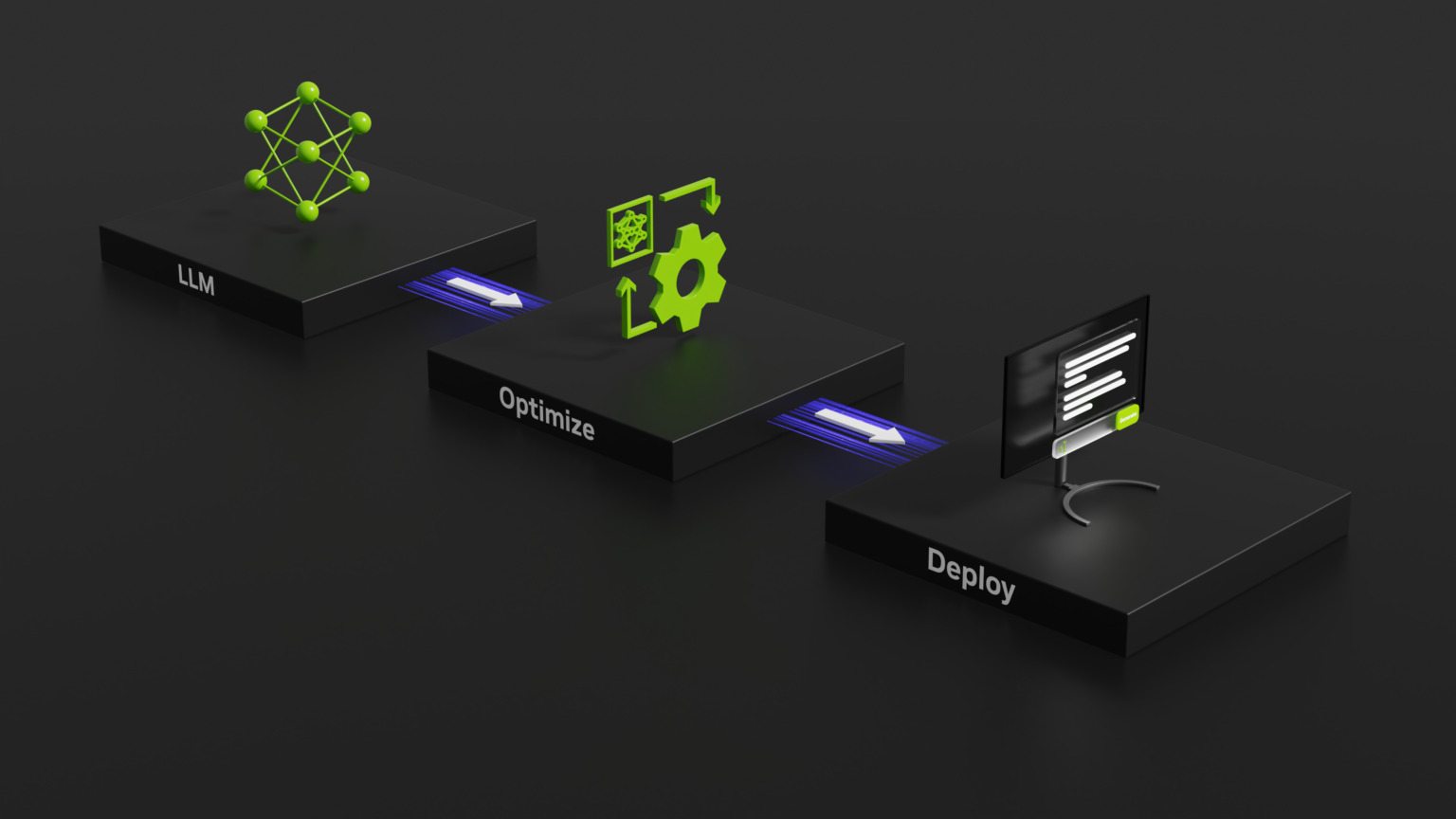
Perangkat lunak ini dilengkapi untuk menangani LLM kontemporer seperti Meta Llama 2, OpenAI GPT-4, Falcon, MPT mosaik, BLOOM, dan banyak lagi. Ini menggabungkan compiler pembelajaran mendalam TensorRT, kernel yang dioptimalkan, dan alat sebelum dan sesudah pemrosesan. Selain itu, ini memfasilitasi komunikasi multi-GPU dan multi-node. Fitur yang menonjol adalah developer tidak memerlukan pemahaman mendalam tentang C++ atau NVIDIA CUDA untuk memanfaatkan TensorRT-LLM.
Naveen Rao, Wakil Presiden Teknik di Databricks, mengomentari efisiensi perangkat lunak tersebut, dengan menyatakan, “TensorRT-LLM mudah digunakan, penuh fitur… dan efisien.”Dia lebih lanjut menambahkan bahwa “ memberikan performa tercanggih untuk penayangan LLM menggunakan GPU NVIDIA dan memungkinkan kami meneruskan penghematan biaya kepada pelanggan kami.”
Peningkatan Performa dengan TensorRT-LLM
Jika menyangkut LLM yang melakukan tugas seperti peringkasan artikel, LLM dijalankan lebih cepat pada TensorRT-LLM yang dikombinasikan dengan GPU NVIDIA H100 dibandingkan dengan chip NVIDIA A100 lama tanpa pustaka LLM. Secara khusus, performa GPU H100 untuk inferensi GPT-J 6B LLM mengalami peningkatan empat kali lipat. Saat dipasangkan dengan software TensorRT-LLM, peningkatan ini melonjak hingga delapan kali lipat.
Fitur utama TensorRT-LLM adalah penggunaan paralelisme tensor. Teknik ini membagi matriks bobot yang berbeda di seluruh perangkat, memungkinkan inferensi dilakukan secara bersamaan di beberapa GPU dan server.
Visi NVIDIA untuk AI yang Hemat Biaya
Visi NVIDIA untuk AI yang Hemat Biaya
penerapan LLM bisa menjadi urusan yang mahal. NVIDIA menyarankan agar LLM mengubah cara pusat data dan pelatihan AI dicatat dalam laporan keuangan perusahaan. Dengan TensorRT-LLM, NVIDIA bertujuan untuk memungkinkan bisnis mengembangkan AI generatif yang rumit tanpa mengalami lonjakan total biaya kepemilikan.
TensorRT-LLM NVIDIA saat ini tersedia untuk akses awal bagi mereka yang terdaftar di Program Pengembang NVIDIA. Rilis yang lebih luas diperkirakan akan dirilis dalam beberapa minggu mendatang.