A DeepSeek piacra dobta legújabb nyílt forráskódú mesterséges intelligencia-modelljeit, a DeepSeek-R1-et és a DeepSeek-R1-Zero-t, amelyek újradefiniálják, hogyan érhetők el az érvelési képességek megerősítéses tanulással (RL).
A új modellek kihívás elé állítják a hagyományos mesterséges intelligencia fejlesztést azáltal, hogy bizonyítják a felügyelt finomhangolást (SFT) nem nélkülözhetetlen a fejlett problémamegoldó képességek fejlesztéséhez. Az olyan szabadalmaztatott rendszerekkel, mint például az OpenAI o1 sorozatával vetekvő benchmark eredményekkel a DeepSeek modelljei szemléltetik a nyílt forráskódú mesterséges intelligencia növekvő potenciálját a versenyképes, nagy teljesítményű eszközök szállításában.
E modellek sikere az erősítés egyedi megközelítésében rejlik. Tanulás (RL), hidegindítási adatok bevezetése és hatékony desztillációs folyamat. Ezek az újítások érvelési képességeket hoztak létre a kódolásban, a matematikában és az általános logikai feladatokban, hangsúlyozva a nyílt forráskódú mesterséges intelligencia életképességét a vezető szabadalmaztatott modellek versenytársaként.
Kapcsolódó: DeepSeek AI nyílt forráskódú VL2 Series of Vision Language Models
Ben Jelölje ki a Nyílt forráskódú potenciál
ot
A DeepSeek-R1 teljesítménye a széles körben elismert benchmarkokban megerősíti képességeit:
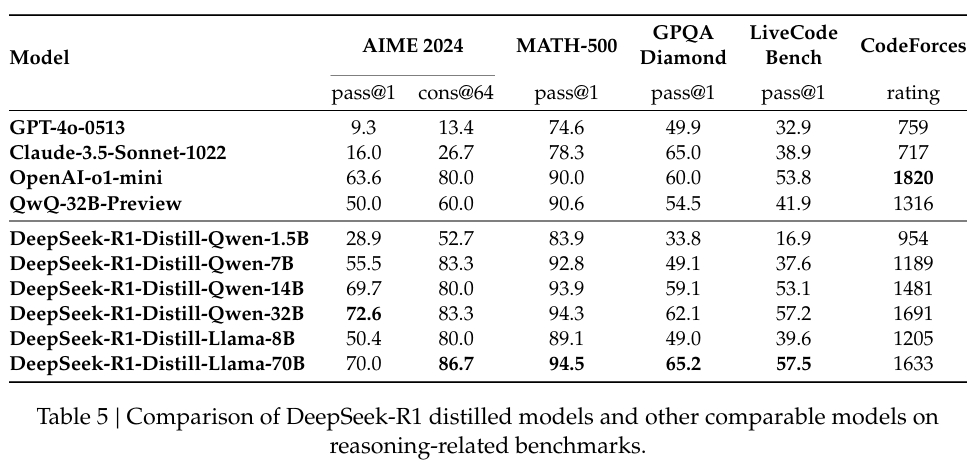
A MATH-500-ban, egy olyan adatkészletben, amelyet a matematikai problémamegoldás értékelésére terveztek, a DeepSeek-R1 97,3%-os Pass@1 pontszámot ért el. megfelel az OpenAI o1-1217 modelljének. A fejlett érvelési feladatokra összpontosító AIME 2024 benchmarkon a modell 79,8%-ot ért el, ami némileg felülmúlja az OpenAI eredményeit.
A modell teljesítménye a LiveCodeBenchben, a kódolási és logikai feladatok mércéjében egyaránt figyelemre méltó volt. a Pass@1-CoT pontszám 65,9%. A DeepSeek kutatása szerint ez az egyik legjobban teljesítő a nyílt forráskódú modellek között ebben a kategóriában.
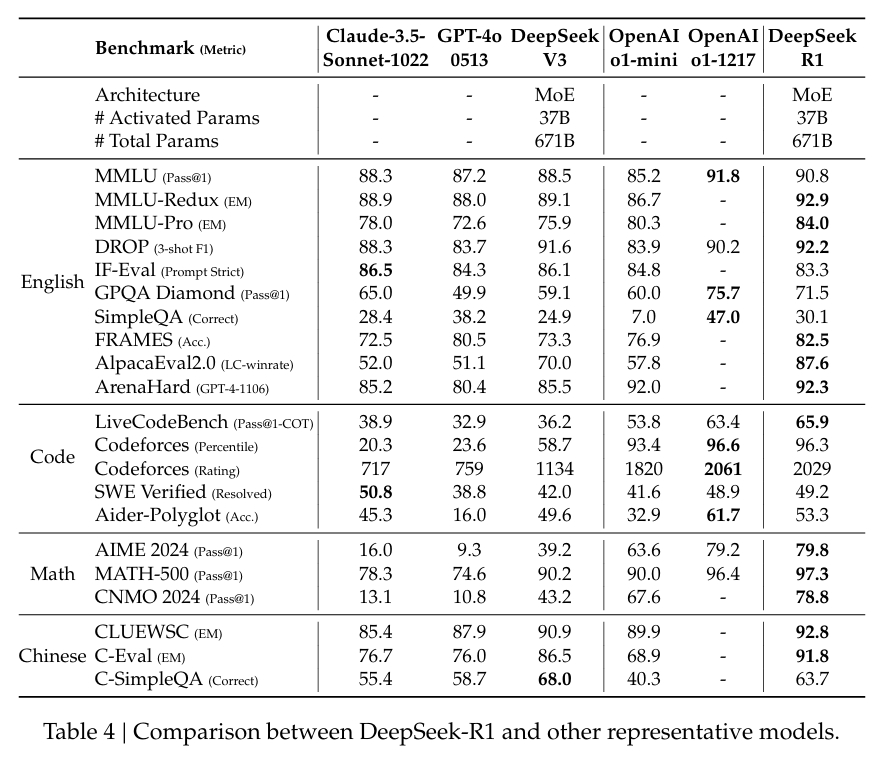
A vállalat befektetett erősen lepárolják, biztosítva, hogy a DeepSeek-R1 kisebb verziói megőrizzék a nagyobb modellek érvelési képességeinek nagy részét. Nevezetesen, a 32 milliárd paraméteres modell, a DeepSeek-R1-Distill-Qwen-32B több kategóriában felülmúlta az OpenAI o1-miniét, miközben számításilag jobban hozzáférhető volt.
Tanulás megerősítése felügyelet nélkül: DeepSeek-R1-Zero
DeepSeek-R1-Zero ez a cég merész kísérlete a csak RL képzések felfedezésére. Egyedülálló algoritmust alkalmaz, a Group Relative Policy Optimization (GRPO) nevű algoritmust, amely leegyszerűsíti az RL képzést azáltal, hogy nincs szükség külön kritikus modellre.
Ehelyett csoportos pontszámokat használ az alapértékek becsléséhez, jelentősen csökkentve ezzel a számítási költségeket, miközben a képzés minőségének fenntartása. Ez a megközelítés lehetővé teszi, hogy a modell érvelési viselkedést fejlesszen ki, beleértve a gondolatlánc (CoT) gondolkodást és az önreflexiót.
A saját kutatási cikk, a DeepSeek csapata kijelentette:
„A DeepSeek-R1-Zero olyan képességeket mutat be, mint az önellenőrzés, a tükrözés és a hosszú CoT-k generálása. Azonban küszködik az ismétlődéssel, olvashatósággal és nyelvkeveréssel, így kevésbé alkalmas valós használati esetekre.”
Bár ezek a megjelenő viselkedések ígéretesek voltak, a modell korlátai rávilágítottak a finomítás szükségességére. Például , a kimenetei időnként ismétlődőek voltak, vagy vegyes nyelvű problémákat jelenítettek meg, ami csökkentette a használhatóságot a gyakorlati forgatókönyvekben.
Csak RL-től a következőig Hibrid képzés: DeepSeek-R1
Ezen kihívások kezelésére a DeepSeek kifejlesztette a DeepSeek-R1-et, amely az RL-t felügyelt finomhangolással kombinálta-olvasható CoT-k, amelyeket az alapvonal koherenciájának és olvashatóságának javítására terveztek. Ezen az alapon végzett képzéssel a modell az RL-be került, és az egyértelműség érdekében jobban megfelelt az emberi elvárásoknak és relevanciája.
Kapcsolódó: LLaMA AI Under Fire: Mit nem mond a Meta a „nyílt forráskódú” modellekről
A DeepSeek leírta ezt a megközelítést dokumentáció:
„Az R1-Zero-val ellentétben az RL edzés korai instabil hidegindítási fázisának megakadályozása érdekében az alapmodellből az R1 esetében kis mennyiségű hosszú CoT adatot készítünk és gyűjtünk a finomhangoláshoz a modellt, mint a kezdeti RL szereplőt.”
A folyamat tartalmazott iteratív RL-t is, hogy tovább finomítsa az érvelési és problémamegoldó képességeket, és olyan modellt hozzon létre, amely képes kezelni olyan összetett forgatókönyveket, mint a kódolás és a matematikai bizonyítások.
Nyílt forráskódú kisegítő lehetőségek és jövőbeli kihívások
A DeepSeek az MIT Licenc alatt adta ki modelljeit, hangsúlyozva elkötelezettségét a nyílt forráskódú elvek mellett. Ez az engedélyezési modell lehetővé teszi a kutatók és a fejlesztők számára, hogy szabadon használhassák, módosítsák és építsenek a DeepSeek munkájára, elősegítve az együttműködést és az innovációt a mesterséges intelligencia közösségében.
A sikerek ellenére a csapat elismeri, hogy továbbra is kihívásokkal kell szembenézniük. A vegyes nyelvű kimenetek, az azonnali érzékenység és a jobb szoftverfejlesztési képességek iránti igény fejlesztendő területek. A DeepSeek-R1 jövőbeli iterációinak célja ezeknek a korlátoknak a megoldása lesz, miközben funkcionalitását új tartományokra is kiterjeszti.
A kutatók optimizmusukat fejezték ki az előrehaladásukat illetően, és kijelentették:
„A hideg-emberi priorokkal kezdjük az adatokat, jobb teljesítményt figyelünk meg a DeepSeek-R1-Zero-val szemben. Úgy gondoljuk, hogy az iteratív képzés jobb módszer az okoskodási modellekhez.”
Vonatkozások az AI-iparra
A DeepSeek munkája elmozdulást jelez az AI-kutatási környezetben , ahol a nyílt forráskódú modellek már versenyezhetnek a szabadalmaztatott vezetőkkel Azáltal, hogy bebizonyította, hogy az RL képes magas szintű érvelést elérni SFT nélkül, és hangsúlyozta a desztillációt a skálázható hozzáférhetőség érdekében. mércét állít fel a jövőbeli mesterséges intelligencia-kutatáshoz.
A nyílt forráskódú mesterséges intelligencia továbbfejlődése során a DeepSeek-R1 fejlesztései vázlatot adnak az RL-nek praktikus, nagy teljesítményű modellek előállításához.


