A Microsoft bemutatta az rStar-Math programot, amely a korábbi rStar keretrendszer, amely a kis nyelvi modellek (SLM-ek) határait feszegeti a matematikai érvelésben.
A nagyobb rendszerekkel, például az OpenAI o1-előnézetével riválisra tervezett rStar-Math figyelemre méltó teljesítményt nyújt a problémamegoldásban, miközben bemutatja, hogy a kompakt modellek milyen teljesítményt nyújtanak versenyképes szinten. Ez a fejlesztés a mesterséges intelligencia prioritásainak eltolódását mutatja, a skálázástól a teljesítmény optimalizálása felé haladva bizonyos feladatokhoz.
Tovább az rStar-ról az rStar-Math-re
Az rStar A tavaly nyári keretrendszer lefektette az alapot az SLM-gondolkodás fejlesztéséhez a Monte révén Carlo Tree Search (MCTS), egy olyan algoritmus, amely több útvonal szimulálásával és érvényesítésével finomítja a megoldásokat.
rStar bebizonyította, hogy a kisebb modellek képesek összetett feladatok kezelésére, de alkalmazása általános maradt. Az rStar-Math erre az alapra épít a matematikai érveléshez szabott célzott innovációkkal.
Az rStar-Math sikerének központi eleme a kóddal kiegészített gondolatlánc (CoT) módszertana, ahol a modell mindkét területen megoldásokat hoz létre. természetes nyelv és végrehajtható Python kód.
Ez a kettős kimenetű struktúra biztosítja, hogy a közbenső érvelési lépések ellenőrizhetőek legyenek, csökkentve a hibákat és fenntartva a logikai konzisztenciát. A kutatók hangsúlyozták ennek a megközelítésnek a fontosságát, és kijelentették: „A kölcsönös következetesség tükrözi a felügyelet hiányában bevett általános emberi gyakorlatot, ahol a származtatott válaszokban a társak közötti egyetértés a helyesség nagyobb valószínűségére utal.”
Kapcsolódó: A kínai DeepSeek R1-Lite-Preview modell az OpenAI vezető pozícióját célozza meg az automatizált érvelésben
A CoT mellett az rStar-Math bemutatja a Process Preference Model (PPM), amely a köztes lépéseket a minőség alapján értékeli és rangsorolja A hagyományos jutalmazási rendszerekkel ellentétben, amelyek gyakran zajos adatokra támaszkodnak, a PPM a logikai koherenciát és pontosságot helyezi előtérbe, tovább növelve a modell megbízhatóságát >
“A PPM kihasználja azt a tényt, hogy bár a Q-értékek még mindig nem elég pontosak az egyes érvelési lépések pontozásához, annak ellenére, hogy kiterjedt MCTS-t használnak. A Q-értékek megbízhatóan meg tudják különböztetni a pozitív (helyes) lépéseket a negatív (irreleváns/helytelen) lépésektől.
Így a képzési módszer minden lépéshez preferenciapárokat hoz létre Q-értékek alapján, és páronkénti rangsort használ veszteség a PPM pontszám előrejelzésének optimalizálásához minden egyes érvelési lépéshez, megbízható címkézést érve el. Ez a megközelítés elkerüli azokat a hagyományos módszereket, amelyek közvetlenül Q-értékeket használnak jutalomcímkéként, amelyek eredendően zajosak és pontatlanok a jutalom fokozatos kiosztásánál.”
Végül egy négyfordulós önfejlődési recept, amely fokozatosan kiépíti mindkét határvonalat. irányelvmodell és PPM a semmiből.
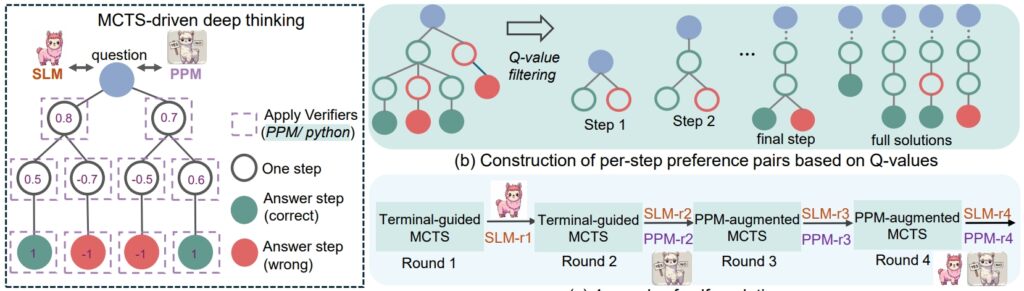 rSTar-Math érvelési eljárás (Forrás: kutatási cikk)
rSTar-Math érvelési eljárás (Forrás: kutatási cikk)
A nagyobb modellek számára kihívást jelentő teljesítmény
Az rStar-Math új mércét állít fel a matematikai érvelési benchmarkokban, olyan eredményeket érve el, amelyek vetekednek a nagyobb mesterségesintelligencia-rendszerekével, és bizonyos esetekben meg is haladják azokat.
A GSM8K adatkészlet, a matematikai érvelés tesztje, egy 7 milliárd paraméteres modell pontossága 12,51%-ról javult 63,91% az rStar-Math integrálása után Az American Invitational Mathematics Examination (AIME) során a modell a problémák 53,3%-át oldotta meg, a középiskolások legjobb 20%-a közé helyezve.
A MATH adatkészlet eredményei ugyanilyen lenyűgözőek voltak: az rStar-Math 90%-os pontosságot ért el, felülmúlva az OpenAI o1-előnézetét.
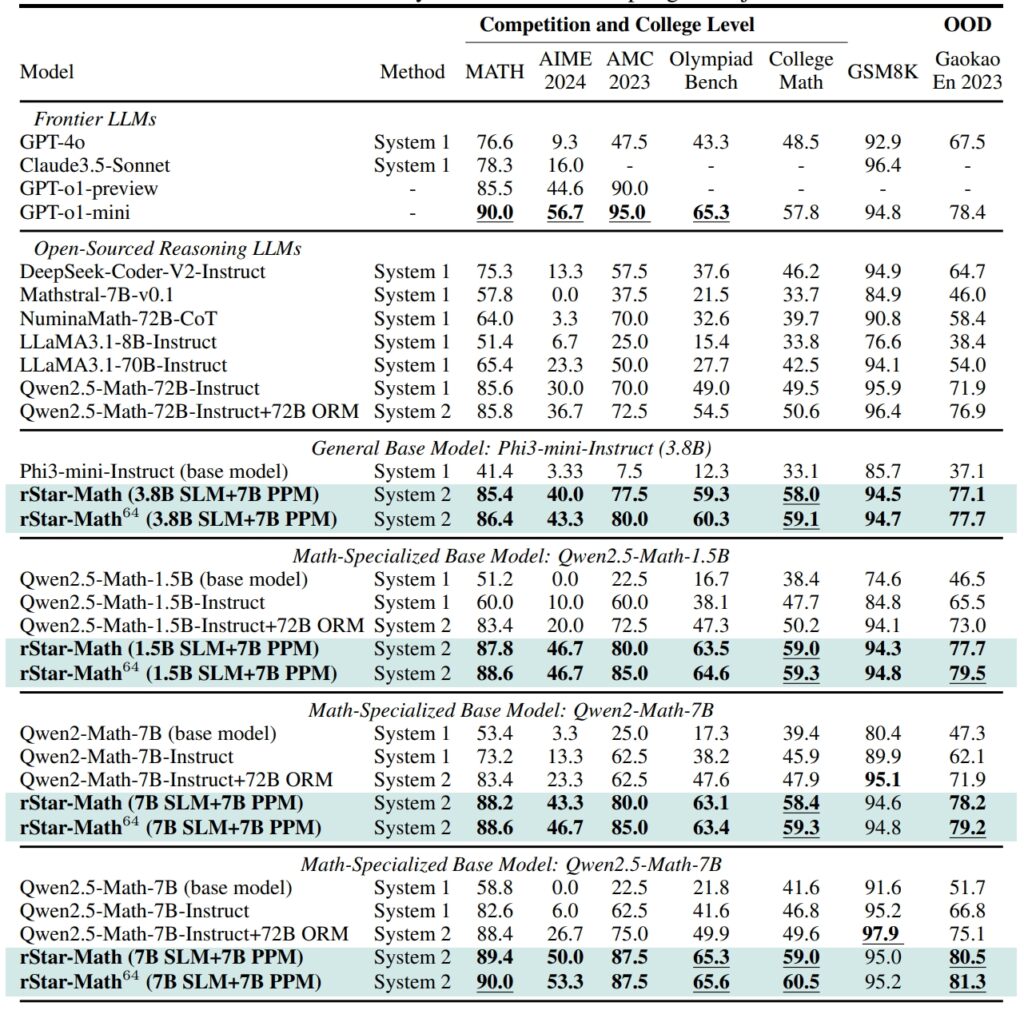 Az rStar-Math és más határmenti LLM-ek teljesítménye a legnagyobb kihívást jelentő matematikai benchmarkokon (Forrás: kutatási cikk)
Az rStar-Math és más határmenti LLM-ek teljesítménye a legnagyobb kihívást jelentő matematikai benchmarkokon (Forrás: kutatási cikk)
Ezek az eredmények rávilágítanak a keretrendszer azon képességére, hogy az SLM-ek képesek legyenek kezelni azokat a feladatokat, amelyeket korábban az erőforrás-igényes nagy modellek uraltak. A logikai konzisztencia és az ellenőrizhető köztes lépések hangsúlyozásával az rStar-Math az AI egyik legmaradandóbb kihívását oldja meg: megbízható érvelést biztosít összetett problématerületeken.
Technikai innovációk az rStar-Math számára
Az rStarról az rStar-Math-re való evolúció számos kulcsfontosságú fejlesztést vezet be. Az MCTS integrációja továbbra is központi szerepet játszik a keretrendszerben, lehetővé téve a modell számára, hogy különféle érvelési utakat tárjon fel, és a legígéretesebbeket rangsorolja.
A kódellenőrzésre összpontosító CoT érvelés hozzáadása biztosítja, hogy a kimenetek értelmezhetőek és pontosak legyenek.
Kapcsolódó: Alibaba QwQ-32B-Az előnézet csatlakozik a mesterséges intelligencia-modellekért folytatott küzdelemhez az OpenAI-val.
Talán az rStar-Math önfejlődő képzési folyamata a legátalakítóbb. Négy iteratív körön keresztül a keretrendszer finomítja a politikai modellt és a PPM-et, és minden lépésben jobb minőségű érvelési adatokat tartalmaz.
Ez az iteratív megközelítés lehetővé teszi a modell számára, hogy folyamatosan javítsa teljesítményét, és a legkorszerűbb eredményeket érje el anélkül, hogy nagyobb modellek desztillációjára hagyatkozna.
Az rStar-Math összehasonlítása az OpenAI o1-hez
Míg a Microsoft a kisebb modellek optimalizálására összpontosít, az OpenAI továbbra is prioritásként kezeli rendszerei bővítését.
A 2024 decemberében a ChatGPT Pro terv részeként bevezetett o1 Pro mód fejlett érvelési képességeket kínál olyan nagy téttel rendelkező alkalmazásokhoz, mint a kódolás és a tudományos kutatás. Az OpenAI arról számolt be, hogy az o1 Pro Mode 86%-os pontossági arányt ért el az AIME-n és 90%-os sikerarányt olyan kódolási benchmarkokban, mint a Codeforces.
rStar-Math egy elmozdulást jelent az AI-innovációban, megkérdőjelezve az iparág nagyobb modellekre való összpontosítását. mint a fejlett érvelés elérésének elsődleges eszköze. Az SLM-ek tartományspecifikus optimalizálásokkal történő fejlesztésével a Microsoft fenntartható alternatívát kínál, amely csökkenti a számítási költségeket és a környezeti hatásokat.
Kapcsolódó: Deliberatív összehangolás: Az OpenAI biztonsági stratégiája az o1 és o3 gondolkodási modellekhez
A keretrendszer sikere a matematikai érvelés terén szélesebb körű alkalmazások előtt nyit ajtót, az oktatástól kezdve a tudományos kutatáshoz.
A kutatók azt tervezik, hogy kiadják az rStar-Math kódját és adatait a GitHubon, megnyitva az utat a további együttműködés és fejlődését. Ez az átláthatóság tükrözi a Microsoft azon megközelítését, amellyel a nagy teljesítményű AI-eszközöket szélesebb közönség számára teszi elérhetővé, beleértve a tudományos intézményeket és a közepes méretű szervezeteket.
Kapcsolódó: SemiAnalysis: Nem, AI Scaling Isn Nem lassul
A Microsoft és az OpenAI közötti verseny fokozódásával az rStar-Math által bevezetett fejlesztések rávilágítanak a kisebb modellek kihívásaira. a nagyobb rendszerek dominanciája. A hatékonyság és a pontosság előtérbe helyezésével az rStar-Math új mércét állít fel a kompakt AI-rendszerek teljesítményére vonatkozóan.

