A DeepSeek AI kiadta a DeepSeek-VL2-t, a Vision-Language Models (VLM-ek) családját, amely immár nyílt forráskódú licencek alatt érhető el. A sorozat három változatot mutat be – Tiny, Small és a standard VL2 –, amelyek aktivált paraméterméretei 1,0 milliárd, 2,8 milliárd és 4,5 milliárd.
A modellek a GitHubon és a Ölelő arc. Azt ígérik, hogy továbbfejlesztik a kulcsfontosságú mesterséges intelligencia alkalmazásokat, beleértve a vizuális kérdések megválaszolását (VQA), az optikai karakterfelismerést (OCR), valamint a nagy felbontású dokumentum-és diagramelemzést.
A hivatalos GitHub-dokumentáció szerint „A DeepSeek-VL2 kiváló képességeket demonstrál a különböző feladatok során, beleértve, de nem kizárólagosan a vizuális kérdések megválaszolását, a dokumentumok/táblázatok/diagramok megértését és a vizuális alapozást.”
A kiadás időzítése szerint a DeepSeek AI közvetlen versenyben áll a főbb szereplőkkel, például az OpenAI-val és a Google-lal, amelyek mindketten uralják a vision-nyelvű mesterséges intelligencia tartományt. olyan modellek, mint a GPT-4V és a Gemini-Exp.
A DeepSeek a nyílt forráskódú együttműködésre helyezi a hangsúlyt, és a VL2 család fejlett műszaki jellemzőivel kombinálva a kutatók számára ingyenes lehetőségként pozicionálja.
Dinamikus csempézés: Advancing High-Felbontású képfeldolgozás
A DeepSeek-VL2 egyik legfigyelemreméltóbb fejlesztése a dinamikus csempézéses képkódolás stratégia, amely forradalmasítja a modellek nagy felbontású vizuális adatok feldolgozását.
A hagyományos fix felbontású megközelítésekkel ellentétben a dinamikus csempézés kisebb, rugalmas csempékre osztja a képeket, amelyek alkalmazkodnak a különböző képarányokhoz. Ez a módszer biztosítja a részletes jellemzők kinyerését, miközben megőrzi a számítási hatékonyságot.
A GitHub adattárában a DeepSeek ezt úgy írja le, mint „hatékonyan feldolgozza a nagy felbontású képeket változó képarányokkal, elkerülve a számítási skálázást, amely általában a növekvő képfelbontásokhoz társul”.
Ez a képesség lehetővé teszi a DeepSeek-VL2 számára, hogy kiválóan teljesítsen olyan alkalmazásokban, mint például a vizuális földelés, ahol a nagy pontosság elengedhetetlen az objektumok azonosításához összetett képeken és a sűrű OCR feladatok, amelyek a részletes dokumentumokban vagy diagramokban található szöveg feldolgozását igénylik
A különböző képfelbontásokhoz és képarányokhoz való dinamikus alkalmazkodással a modellek leküzdik a statikus kódolási módszerek korlátait, így alkalmassá válnak olyan felhasználási esetekre, amelyek rugalmasságot igényelnek. és a pontosság.
Szakértők keveréke és többfejű látens figyelem a hatékonyság érdekében
A DeepSeek-VL2 teljesítménynövekedését tovább támogatja a Mixture-of-Experts (MoE) keretrendszer és a Multi-head Latent Attention (MLA) mechanizmus integrálása.
A MoE architektúrája szelektíven aktivál bizonyos részhalmazokat , vagy „szakértők” a modellen belül a feladatok hatékonyabb kezeléséhez. Ez a kialakítás csökkenti a számítási többletterhelést azáltal, hogy csak a szükséges paramétereket kapcsolja be az egyes műveletekhez, ami különösen hasznos erőforrás-korlátos környezetben.
Az MLA-mechanizmus kiegészíti a MoE keretrendszert azáltal, hogy a kulcs-érték gyorsítótárat látenssé tömöríti. vektorok a következtetés során. Ez az optimalizálás minimálisra csökkenti a memóriahasználatot és növeli a feldolgozási sebességet a modell pontosságának feláldozása nélkül.
A műszaki dokumentáció szerint „A MoE architektúra az MLA-val kombinálva lehetővé teszi a DeepSeek-VL2 számára versenyképes vagy jobb teljesítmény elérését, mint a kevesebb aktivált paraméterrel rendelkező sűrű modellek.”
Three-Stage Training Pipeline
A DeepSeek-VL2 fejlesztése egy szigorú, háromlépcsős képzési folyamatot tartalmazott, amelynek célja a A modell multimodális képességei Az első szakasz a látás-nyelv igazítására összpontosított, ahol a modelleket a vizuális funkciók és a szöveges információk integrálására tették. A kezdeti összehangolás a látás-nyelv előképzést foglalta magában, amely sokféle adatkészletet tartalmazott, beleértve a WIT-et, a WikiHow-t és. többnyelvű OCR adatok, a modell általánosítási képességeinek javítása több tartományon keresztül. Végül a harmadik szakasz a felügyelt finomhangolásból (SFT) állt, ahol a feladatspecifikus adatkészletek segítségével finomították a modell teljesítményét olyan területeken, mint a vizuális alapozás, a grafikus felhasználói felület. (GUI) szövegértés és sűrű feliratozás.
Ezek a képzési szakaszok lehetővé tették a DeepSeek-VL2 számára, hogy szilárd alapot építsen a multimodális megértéshez, miközben lehetővé téve a modellek speciális feladatokhoz való alkalmazkodását. A többnyelvű adatkészletek beépítése tovább javította a modellek alkalmazhatóságát a globális kutatási és ipari környezetben.
Kapcsolódó: A kínai DeepSeek R1-Lite-Preview modell az OpenAI vezető pozícióját célozza meg az automatizált érvelés terén
p>
Benchmarking eredmények
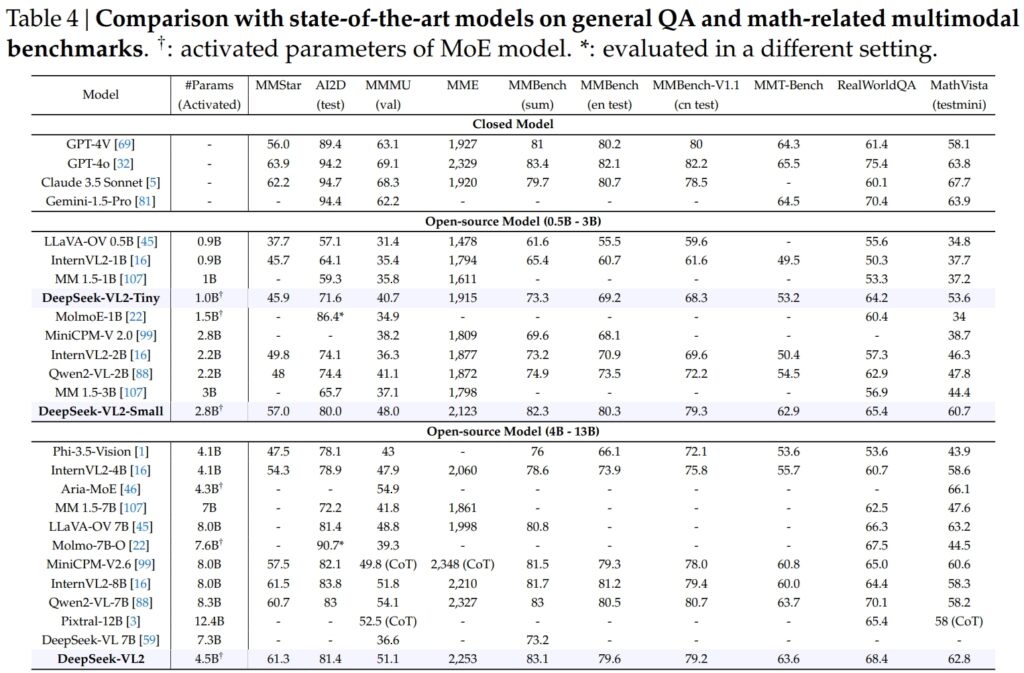
DeepSeek-VL2 modellek, beleértve a Tiny, Small és standard változatok, kiválóan teljesítettek az általános kérdés-válaszolás (QA) és a matematikával kapcsolatos multimodális feladatok kritikus benchmarkjaiban.
A DeepSeek-VL2-Small 2,8 milliárd aktivált paraméterével 57,0 MMStar pontszámot ért el, és felülmúlta a hasonló méretű modelleket, mint az InternVL2-2B (49,8) és a Qwen2-VL-2B (48,0). Szorosan vetekedett a sokkal nagyobb modellekkel is, mint például a 4.1B InternVL2-4B (54.3) és a 8.3B Qwen2-VL-7B (60.7), bizonyítva versenyképességi hatékonyságát.
A vizuális AI2D teszten érvelése szerint a DeepSeek-VL2-Small 80,0 pontot ért el, megelőzve az InternVL2-2B-t (74,1) és MM 1,5-3B (nincs jelentve). Még az olyan nagyobb versenytársakkal szemben is, mint az InternVL2-4B (78.9) és a MiniCPM-V2.6 (82.1), a DeepSeek-VL2 erős eredményeket mutatott fel kevesebb aktivált paraméterrel.
 Forrás: DeepSeek
Forrás: DeepSeek
A zászlóshajó A DeepSeek-VL2 modell (4,5 milliárd aktivált paraméter) kivételes eredményeket hozott, pontozást 61,3 az MMStar-on és 81,4 az AI2D-n. Meghaladta a versenytársakat, például a Molmo-7B-O-t (7,6B aktivált paraméterek, 39,3) és a MiniCPM-V2.6-ot (8,0B, 57,5), tovább erősítve technikai fölényét.
Kiválóság az OCR-ben-Kapcsolódó referenciaértékek
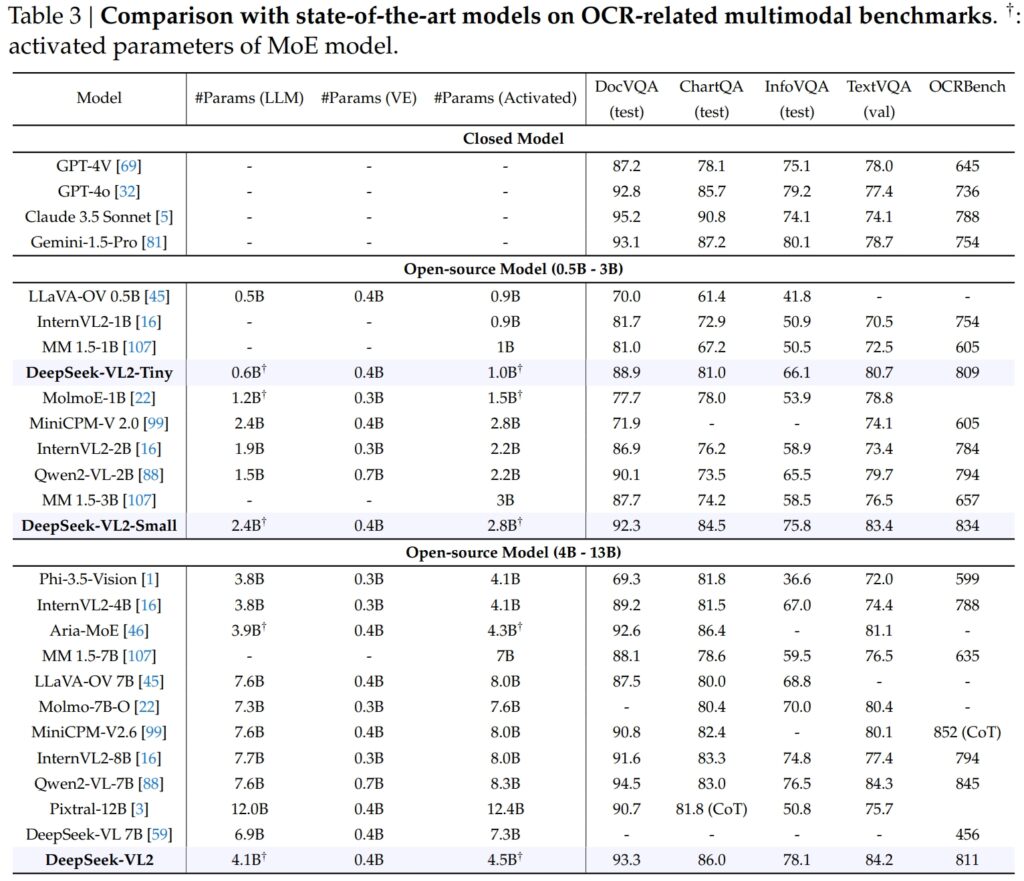
A DeepSeek-VL2 képességei kiemelkedően kiterjednek az OCR-re (optikai karakterfelismeréssel) kapcsolatos feladatok, amelyek kulcsfontosságú terület a dokumentumok megértéséhez és a szövegek kinyeréséhez az AI-ban. A DocVQA tesztben a DeepSeek-VL2-Small lenyűgöző, 92,3%-os pontosságot ért el, felülmúlva az összes többi, hasonló léptékű nyílt forráskódú modellt, beleértve az InternVL2-4B-t (89,2%) és a MiniCPM-V2.6-ot (90,8%). Pontossága a zárt modellek, például a GPT-4o (92.8) és a Claude 3.5 Sonnet (95.2) mögött volt.
A DeepSeek-VL2 modell a ChartQA tesztben is vezetett 86.0-s eredménnyel, felülmúlva az InternVL2-t. 4B (81.5) és MiniCPM-V2.6 (82.4). Ez az eredmény a DeepSeek-VL2 fejlett képességét tükrözi, amellyel diagramokat dolgozhat fel, és betekintést nyerhet összetett vizuális adatokból.
 Forrás: DeepSeek
Forrás: DeepSeek
In Az OCRBench, a finomszemcsés szövegfelismerés rendkívül versenyképes mérőszáma, a DeepSeek-VL2 811-et ért el, felülmúlja a 7.6B Qwen2-VL-7B (845) és MiniCPM-V2.6 (852 CoT-vel), és kiemeli erősségét a sűrű OCR-feladatokban.
Összehasonlítás a vezető Vision-Language modellekkel
Ha olyan iparági vezetők mellé helyezzük, mint az OpenAI GPT-4V és a Google A Gemini-1.5-Pro, DeepSeek-VL2 modellek a teljesítmény és a hatékonyság lenyűgöző egyensúlyát kínálják. Például a GPT-4V 87,2 pontot ért el a DocVQA-ban, ami csak kis mértékben előzi meg a DeepSeek-VL2-t (93,3), annak ellenére, hogy az utóbbi nyílt forráskódú keretrendszerben működik, kevesebb aktivált paraméterrel.
A TextVQA-n a DeepSeek-VL2-Small 83,4-et ért el, jelentősen felülmúlva a hasonló nyílt forráskódú modelleket, mint például az InternVL2-2B (73,4) és MiniCPM-V2.0 (74.1). Még a sokkal nagyobb MiniCPM-V2.6 (8.0B) is csak a 80.4-et érte el, ami tovább hangsúlyozta a DeepSeek-VL2 architektúrájának méretezhetőségét és hatékonyságát.
A ChartQA esetében a DeepSeek-VL2 86.0-s pontszáma meghaladta a Pixtral-ét. 12B (81.8) és InternVL2-8B (83.3), bizonyítva, hogy képes excel a precíz vizuális-szövegértést igénylő speciális feladatokban.
Kapcsolódó: A Mistral AI bemutatja a Pixtral 12B-t szöveg-és képfeldolgozáshoz
Alkalmazások bővítése: A megalapozott beszélgetésektől a vizuális történetmesélésig
A DeepSeek-VL2 modellek egyik figyelemre méltó tulajdonsága a képességük megalapozott beszélgetések lefolytatására, ahol a modell képes azonosítani a tárgyakat a képeken és integrálni azokat a kontextuális megbeszélésekbe.
Például egy speciális token használatával a modell objektumspecifikus részleteket, például helyet és leírást biztosíthat a képekkel kapcsolatos kérdések megválaszolásához. Ez lehetőségeket nyit a robotika, a kiterjesztett valóság és a digitális asszisztensek terén, ahol pontos vizuális érvelésre van szükség.
A másik alkalmazási terület a vizuális történetmesélés. A DeepSeek-VL2 képsorozat alapján koherens narratívákat tud generálni, kombinálva fejlett vizuális felismerési és nyelvi képességeit.
Ez különösen értékes az olyan területeken, mint az oktatás, a média és a szórakoztatás, ahol a dinamikus tartalomkészítés prioritást élvez. A modellek erős multimodális megértést tesznek lehetővé, hogy részletes és kontextusnak megfelelő történeteket alkossanak, a vizuális elemeket, például a tereptárgyakat és a szöveget zökkenőmentesen integrálva a narratívába.
A modellek vizuális megalapozó képessége ugyanilyen erős. Az összetett képeket tartalmazó tesztek során a DeepSeek-VL2 bebizonyította, hogy képes pontosan megkeresni és leírni az objektumokat leíró utasítások alapján.
Ha például arra kérik, hogy azonosítson egy „az utca bal oldalán parkoló autót”, a modell pontosan meg tudja határozni a képen látható objektumot, és határolódoboz koordinátákat generál a válasz illusztrálására. kiválóan alkalmazható autonóm rendszerekben és felügyeletben, ahol a részletes vizuális elemzés kritikus fontosságú.
Nyílt forráskódú hozzáférhetőség és méretezhetőség
A DeepSeek AI döntése a kiadásról A DeepSeek-VL2 nyílt forráskódúként éles ellentétben áll a versenytársak, például az OpenAI GPT-4V és a Google Gemini-Exp védett természetével, amelyek zárt rendszerek, amelyeket korlátozott nyilvános hozzáférésre terveztek.
A műszaki dokumentáció szerint,”Előre betanított modelljeink és kódjaink nyilvános elérhetővé tételével célunk, hogy felgyorsítsuk a látásnyelvi modellezés előrehaladását, és elősegítsük az együttműködésen alapuló innovációt a kutatói közösségben.”
A DeepSeek-VL2 skálázhatósága tovább növeli vonzerejét. A modelleket a hardverkonfigurációk széles skáláján történő telepítésre optimalizálták, a 10 GB memóriával rendelkező egy GPU-któl kezdve a nagyméretű munkaterhelések kezelésére alkalmas több GPU-s beállításokig.
Ez a rugalmasság biztosítja, hogy a DeepSeek-VL2-t bármilyen méretű szervezet használhatja, az induló vállalkozásoktól a nagyvállalatokig, speciális infrastruktúra nélkül.
Innovációk az adat-és Képzés
A DeepSeek-VL2 sikerének egyik fő tényezője a kiterjedt és sokrétű edzési adatok. Az előképzési szakasz olyan adatkészleteket tartalmazott, mint a WIT, a WikiHow és az OBELICS, amelyek átlapolt kép-szöveg párok keverékét biztosították az általánosításhoz.
A konkrét feladatokhoz, például az OCR-hez és a vizuális kérdések megválaszolásához további adatok származtak olyan forrásokból, mint a LaTeX OCR és a PubTabNet, így biztosítva, hogy a modellek nagy pontossággal tudják kezelni az általános és speciális feladatokat egyaránt.
A többnyelvű adatkészletek felvétele a DeepSeek AI globális alkalmazhatóságra vonatkozó célját is tükrözi. A kínai nyelvű adatkészleteket, mint például a Wanjuan, az angol adatkészletek mellé integrálták, hogy biztosítsák a modellek hatékony működését többnyelvű környezetben.
Ez a megközelítés javítja a DeepSeek-VL2 használhatóságát azokban a régiókban, ahol a nem angol adatok dominálnak, jelentősen kibővítve a potenciális felhasználói bázist.
A felügyelt finomhangolási szakasz tovább finomította a modelleket képességeket azáltal, hogy speciális feladatokra összpontosít, mint például a grafikus felhasználói felület megértése és a diagramelemzés. A házon belüli adatkészletek kiváló minőségű nyílt forráskódú erőforrásokkal való kombinálásával a DeepSeek-VL2 a legkorszerűbb teljesítményt érte el számos benchmarkon, igazolva képzési módszertanának hatékonyságát.
A DeepSeek AI gondos gondozása Az adatok és az innovatív oktatási folyamat lehetővé tette a VL2 modellek számára, hogy a feladatok széles skálájában kitűnjenek, miközben megőrizték a hatékonyságot és a méretezhetőséget. Ezek a tényezők értékes kiegészítőivé teszik őket a multimodális mesterséges intelligencia területén.
A modellek azon képessége, hogy képesek kezelni az összetett képfeldolgozási feladatokat, mint például a vizuális alapozás és a sűrű OCR, ideálissá teszi őket olyan iparágakban, mint a logisztika és a biztonság. A logisztikában automatizálhatják a készletkövetést a raktári készlet képeinek elemzésével, cikkek azonosításával és a megállapítások készletkezelési rendszerekbe való integrálásával.
A biztonsági tartományban a DeepSeek-VL2 segíthet a felügyeletben azáltal, hogy valós időben azonosítja az objektumokat vagy személyeket, leíró lekérdezések alapján, és részletes kontextuális információkat biztosít a kezelők számára.
DeepSeek-A VL2 földelt beszélgetési képessége a robotikában és a kiterjesztett valóságban is lehetőségeket kínál. Például egy ezzel a modellel felszerelt robot képes vizuálisan értelmezni a környezetét, válaszolni bizonyos objektumokkal kapcsolatos emberi lekérdezésekre, és a vizuális bemenet megértése alapján végrehajtani műveleteket.
A kibővített valósághoz hasonló eszközök is kihasználhatják a modell vizuális alapozási és történetmesélési funkcióit, hogy interaktív, magával ragadó élményeket, például vezetett túrákat vagy kontextuális átfedéseket biztosítsanak valós idejű környezetben.
Kihívások és jövőbeli kilátások
Számos erőssége ellenére a DeepSeek-VL2 számos kihívással néz szembe. Az egyik legfontosabb korlátozás a kontextusablak mérete, amely jelenleg korlátozza az egyetlen interakción belül feldolgozható képek számát.
A kontextusablak kibővítése a jövőbeli iterációk során gazdagabb, többképes interakciókat tesz lehetővé, és javítja a modell hasznosságát a szélesebb körű kontextus megértését igénylő feladatokban.
Egy másik kihívás a kihagyás kezelésében rejlik. domain vagy gyenge minőségű vizuális bemenetek, például homályos képek vagy objektumok, amelyek nem szerepelnek a képzési adatokban. Míg a DeepSeek-VL2 figyelemreméltó általánosítási képességeket mutatott be, az ilyen bemenetekkel szembeni robusztusság javítása tovább növeli a valós világban való alkalmazhatóságát.
A jövőre nézve a DeepSeek AI azt tervezi, hogy megerősíti modelljei érvelési képességeit, lehetővé téve számukra az egyre összetettebb multimodális feladatok kezelését. A továbbfejlesztett oktatási folyamatok integrálásával és az adatkészletek kibővítésével a változatosabb forgatókönyvek lefedésére a DeepSeek-VL2 jövőbeli verziói új mércét állíthatnak fel a látásnyelvű AI-teljesítmény tekintetében.

