Le nouveau modèle de raisonnement de
Deepseek appelé R1 remet en question les performances du Chatgpt O1 d’Openai, même si elle s’appuie sur des GPU étranglés et un budget relativement faible.
Dans un environnement façonné par des contrôles d’exportation américains restreignant les puces avancées, la startup de renseignement artificiel chinois fondée par le gestionnaire de fonds de couverture Liang Wenfeng, montre comment l’efficacité et le partage des ressources peuvent propulser le développement de l’IA.
La montée en puissance de l’entreprise a retenu l’attention des cercles technologiques en Chine et aux États-Unis.
lié : Pourquoi les sanctions américaines peuvent lutter pour freiner la croissance technologique de la Chine
Rapid Rise de Deepseek
Le voyage de Deepseek a commencé en 2021, lorsque Liang, mieux connu pour son Fonds de trading quant High-Flyer , a commencé à acheter des milliers de GPU Nvidia.
À l’époque, cette décision semblait inhabituelle. En tant que l’un des partenaires commerciaux de Liang a dit à le temps financier, «lorsque nous l’avons rencontré pour la première fois, Il était ce gars très ringard avec une coiffure terrible parlant de la construction d’un cluster de 10 000 puces pour former ses propres modèles. Nous ne l’avons pas pris au sérieux.”
Selon la même source,”il ne pouvait pas articuler sa vision autre que dire: je veux construire ceci, et ce sera un changement de jeu. Nous pensions Cela n’était possible que de géants comme Bytedance et Alibaba.”
Malgré le scepticisme initial, Liang est resté axé sur la préparation des contrôles à l’exportation américaine potentiels. Cette prévoyance a permis à Deepseek de sécuriser une grande fourniture de matériel NVIDIA, y compris des GPU A100 et H800, avant que des restrictions de balayage ne prennent effet.
lié: profondeek Sources ouvertes VL2 série de langage de vision Modèles
Deepseek a fait la une des journaux en révélant qu’il avait entraîné son modèle R1 de 671 milliards de paramètres pour seulement 5,6 millions de dollars en utilisant 2 048 GPU NVIDIA H800.
Le marché chinois, les ingénieurs de Deepseek ont optimisé la procédure de formation pour obtenir des résultats de haut niveau à une fraction du coût généralement associé aux modèles de langage à grande échelle.
dans un interview Publié par MIT Technology Review, Zihan Wang, un ancien chercheur en profondeur, décrit comment l’équipe a réussi à réduire l’utilisation de la mémoire et les frais généraux de calcul tout en préservant la précision.
Il a déclaré que les limitations techniques les poussaient à explorer de nouvelles stratégies d’ingénierie, ce qui les a finalement aidés à rester compétitifs contre des laboratoires de technologie américains mieux financés.
liés : Chine’s Le modèle de raisonnement R1 Deepseek et le concurrent Openai O1 sont fortement censurés
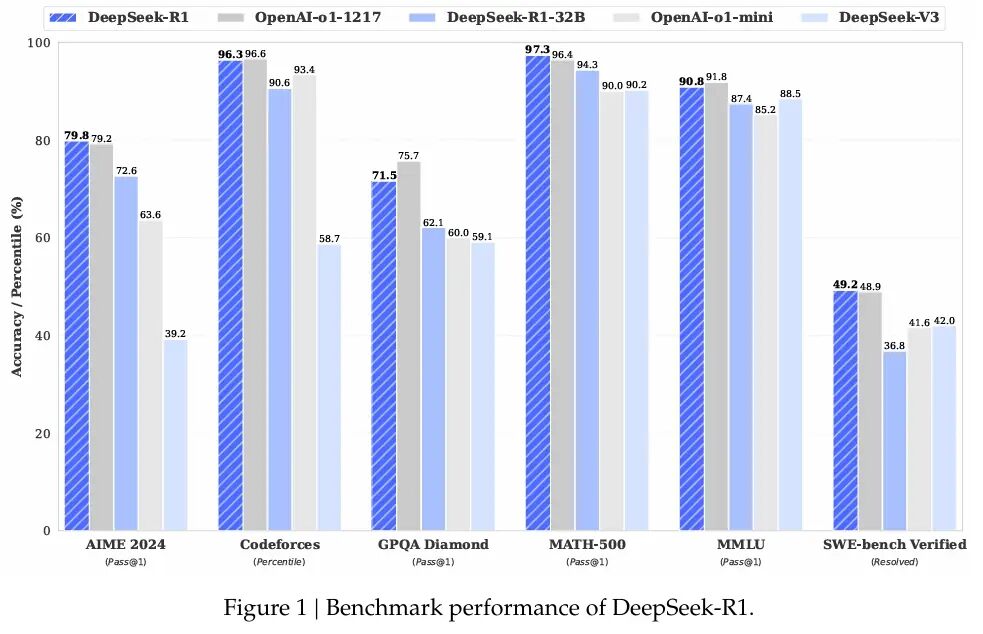
Résultats exceptionnels sur les mathématiques et les références codantes
R1 démontrent d’excellentes capacités à travers diverses références mathématiques et codage. Deepseek a révélé que R1 avait marqué 97,3% (passer @ 1) sur Math-500 et 79,8% sur AIME 2024.
Ces chiffres rivalisent avec la série O1 d’Openai, montrant comment l’optimisation délibérée peut défier les modèles formés sur des puces plus puissantes.
dimitris Papailiopoulos, chercheur principal au Microsoft’s AI Frontiers Lab, a déclaré à MIT Technology Review: «Deepseek visait des réponses précises plutôt que de détailler chaque étape logique, réduisant considérablement le temps de calcul tout en conservant un haut niveau d’efficacité.”
Au-delà Le modèle principal, Deepseek a publié des versions plus petites de R1 qui peuvent fonctionner sur le matériel de base.
Deepseek a largement reproduit O1-MinI et l’a ouvert. pic.twitter.com/2tbq5p5l2c
-aravind srinivas (@aravsrinivas) 20 janvier 2025
Raisonnement de la chaîne et r1-zero
En plus de la formation standard de R1, Deepseek s’est aventuré dans un apprentissage en renforcement pur avec une variante appelée R1-Zero. Cette approche, détaillée dans la documentation de recherche de l’entreprise, rejette le réglage fin supervisé en faveur de l’optimisation des politiques relatives du groupe (GRPO).
En supprimant un modèle de critique distinct et en s’appuyant sur les scores de base groupés, R1-Zero a affiché des comportements de raisonnement et d’auto-réflexion R1-Zero. Cependant, l’équipe a reconnu que R1-Zero produisait des sorties répétitives ou mixtes, indiquant un besoin de supervision partielle avant qu’il ne puisse être utilisé dans les applications quotidiennes.
L’éthique open source derrière Deepseek le distingue de le séparer de de nombreux laboratoires propriétaires. Alors que les entreprises américaines telles qu’Openai, Meta et Google Deepmind gardent souvent leurs méthodes de formation cachées, Deepseek rend son code, son modèle de poids et ses recettes de formation accessibles au public.
lié : Mistral AI fait ses débuts Pixtral 12b pour le traitement du texte et de l’image
Selon Liang, cette approche découle d’un désir de construire une culture de recherche qui favorise transparence et progrès collectif. Dans un Interview avec le média chinois 36KR, il a expliqué que de nombreuses entreprises de l’IA chinoise ont du mal à efficacité par rapport à leurs pairs occidentaux, Et que combler cet écart nécessite une collaboration à la fois sur le matériel et les stratégies de formation.
Son point de vue s’aligne avec d’autres dans la scène de l’IA en Chine, où les sorties open-source sont en augmentation. Alibaba Cloud a introduit plus de 100 modèles open source, et 01.ai, fondée par Kai-Fu Lee, récemment associé à Alibaba Cloud pour établir un laboratoire d’IA industriel.
La communauté technologique mondiale a répondu par un Mélange de crainte et de prudence. Sur X, Marc Andreessen, co-inventeur du navigateur Web Mosaic et maintenant un investisseur de premier plan chez Andreessen Horowitz, a écrit: «Deepseek R1 est l’une des percées les plus étonnantes et les plus impressionnantes que j’ai jamais vues-et en tant que source, une profonde profonde cadeau au monde.”
Deepseek R1 est l’une des percées les plus étonnantes et les plus impressionnantes que j’ai jamais vues-et en tant qu’open source, un cadeau profond pour le monde. 🤖🫡
-Marc Andreessen 🇺🇸 (@PMarca) janvier 24, 2025
Yann LeCun, scientifique en chef de l’IA chez Meta, a noté sur LinkedIn que bien que la réalisation de Deepseek puisse sembler indiquer que la Chine dépasse les États-Unis, il serait plus exact de dire que les modèles open-source rattrapent collectivement des alternatives propriétaires.
«Deepseek a profité de la recherche ouverte et de l’open source (par exemple Pytorch et Llama de Meta)», a-t-il expliqué. «Ils ont proposé de nouvelles idées et les ont construites au-dessus du travail des autres. Parce que leur travail est publié et open source, tout le monde peut en profiter. C’est la puissance de la recherche ouverte et de l’open source.”
Voir sur les threads
Même Mark Zuckerberg, fondateur et PDG de Meta, a fait allusion à un chemin différent en annonçant des investissements massifs dans les centres de données et l’infrastructure GPU. > Sur Facebook, il a écrit: «Ce sera une année déterminante pour l’IA. «Je construira un ingénieur AI qui commencera à contribuer des quantités croissantes de code à nos efforts de R&D. «Je vais en ligne ~ 1 gw de calcul en 2000 et nous terminerons l’année avec plus de 1,3 million de GPU. Capital pour continuer à investir dans les années à venir. Il s’agit d’un effort massif, et au cours des années à venir, elle stimulera nos produits de base et nos activités, déverrouillera l’innovation historique et étendra le leadership technologique américain. Allons construire!”
Les remarques de Zuckerberg suggèrent que les stratégies à forte intensité de ressources restent une force majeure pour façonner le secteur de l’IA.
lié: llama ai sous le feu-Ce que Meta ne vous parle pas des modèles”open source”
élargissant l’impact et les prospects futurs
pour Deepseek, la combinaison de talents locaux, tôt Le stockage GPU et l’accent mis sur les méthodes open-source l’ont propulsé sous un projecteur généralement réservé aux grands géants technologiques. En juillet 2024, Liang a déclaré que son équipe visait à combler ce qu’il a appelé un écart d’efficacité dans l’IA chinois.
Il a décrit de nombreuses sociétés d’IA locales nécessitant le double de la puissance de calcul pour correspondre aux résultats à l’étranger, ce qui aggrave plus en détail lorsque l’utilisation des données est prise en compte. Les bénéfices des fonds de couverture de High-Flyer donnent à Deepseek un tampon contre les pressions commerciales immédiates, Permettre à Liang et à ses ingénieurs de se concentrer sur les priorités de recherche. Liang a déclaré:
«Nous estimons que les meilleurs modèles domestiques et étrangers peuvent avoir un écart d’un fois dans la structure du modèle et la dynamique de formation. Pour cette seule raison, nous devons consommer deux fois plus de puissance de calcul pour obtenir le même effet.
En outre, il peut également y avoir un écart de fois dans l’efficacité des données. Ensemble, nous devons consommer quatre fois plus de puissance de calcul. Ce que nous devons faire est de réduire en continu ces lacunes.”
La réputation de Deepseek en Chine a également reçu un coup de pouce lorsque Liang est devenu le seul leader de l’IA invité à une réunion de grande envergure avec Li Qiang, le deuxième du pays le plus puissant officiel, où il a été invité à se concentrer sur la construction de technologies de base.
Bien que l’avenir reste incertain-en particulier les restrictions américaines pour les États-Unis, Deepseek se démarque de relever les défis de la manière qui transforme les contraintes en voies pour la résolution rapide des problèmes.-Les techniques de formation à l’échelle, la startup a motivé des discussions plus larges sur la question de savoir si l’efficacité des ressources peut sérieusement rivaliser avec les grappes de supercalcul massives. Les réalisations de ce modèle peuvent ouvrir une voie durable pour les progrès de l’IA à une époque d’évolution des restrictions.